The full-blooded versions of o3 and o4-mini appeared late at night. For the first time, image reasoning was integrated into the thinking chain, and tools could be called independently to solve complex problems within 60 seconds. In particular, o3 refreshes programming, mathematics, and visual reasoning SOTA with ten times the computing power of o1, approaching the "genius level." In addition, OpenAI also open sourced the programming artifact Codex CLI, which became popular overnight.
As expected, the full health version of o3 is really here.
Just now, OpenAI co-creator Greg Brockman and chief research officer Mark Chen led a team to start a 20-minute online live broadcast.
This time there is not only o3, but also the next generation inference model o4-mini. They realize "thinking with images" for the first time, which can be called the pinnacle of visual reasoning.

Like AI agents, the two models independently judged and combined the built-in tools of ChatGPT to generate detailed and comprehensive answers in less than 1 minute.
These include searching web pages, using Python to analyze uploaded files and data, performing in-depth reasoning on visual input, and even generating images.

In benchmark tests such as Codeforces, SWE-bench, and MMMU, o3 refreshes SOTA and sets new benchmarks in programming, mathematics, science, and visual perception.
In particular, o3 performs particularly well for image, chart, and graphic analysis, and can deeply dig into the details of visual input.
|
|
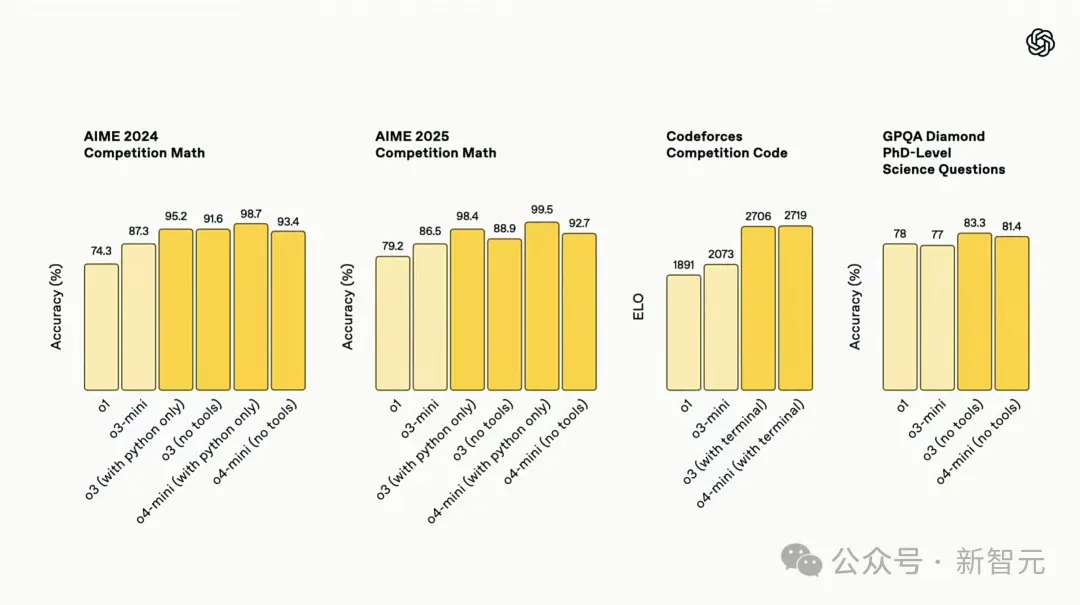
In Codeforces, the new models scored more than 2700 points, ranking among the top 200 global contestants.
In Ultraman's words, "close to or reaching genius level."

However, the price of this intelligence is that it requires more than ten times the computing power of o1.
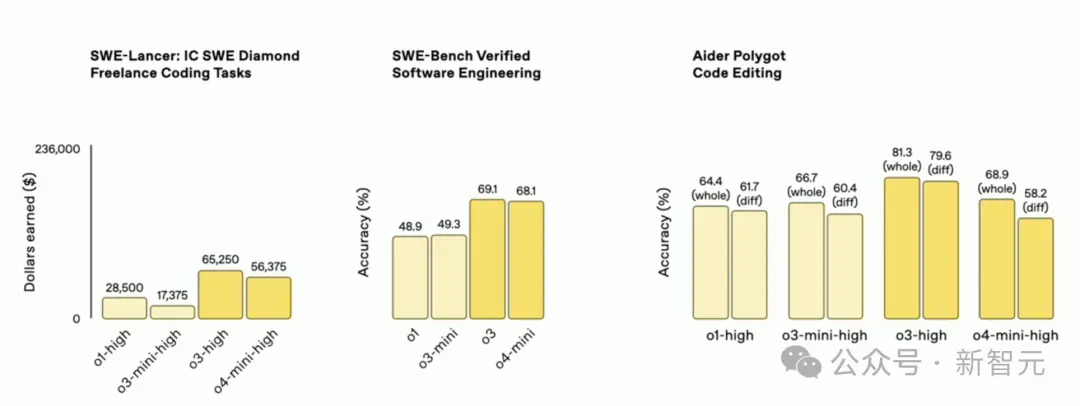
Compared with the full-blooded version of o3, o4-mini stands out for its compactness, efficiency, and high cost performance.
In the AIME 2025 test, o4-mini achieved a high score of 99.5% with the Python interpreter, almost flawlessly winning this benchmark test.
Moreover, its performance is better than o3-mini in mathematics, programming, visual tasks, and non-STEM fields.
In addition, o4-mini supports far more usage than o3, making it the best choice for high-concurrency scenarios.
All in all, both o3 and o4-mini are very good at coding, so OpenAI has also open sourced a lightweight programming AI agent that can run on the terminal - Codex CLI.
|
|
Starting today, ChatGPT Plus, Pro and Team users will be the first to experience o3, o4‑mini and o4‑mini‑high, which will replace o1, o3‑mini and o3‑mini‑high.
At the same time, these two models will also be available to all developers through the Chat Completions API and Responses API.
Inference model, using tools for the first time
During the live demonstration, Greg first mentioned a value - some models are like a qualitative leap, GPT-4 is one of them, and the same is true for o3/o4-mini today.
He said that o3 allowed him and his colleagues at OpenAI to see that large AI models can accomplish "things that have never been seen before." For example, it itself came up with a great system architecture idea.
What’s really surprising about these two models is that they are not just models, they are an “AI system”.
The biggest difference between them and previous inference models is that they are used to train various tools for the first time. They will use these tools in the CoT to solve difficult problems.
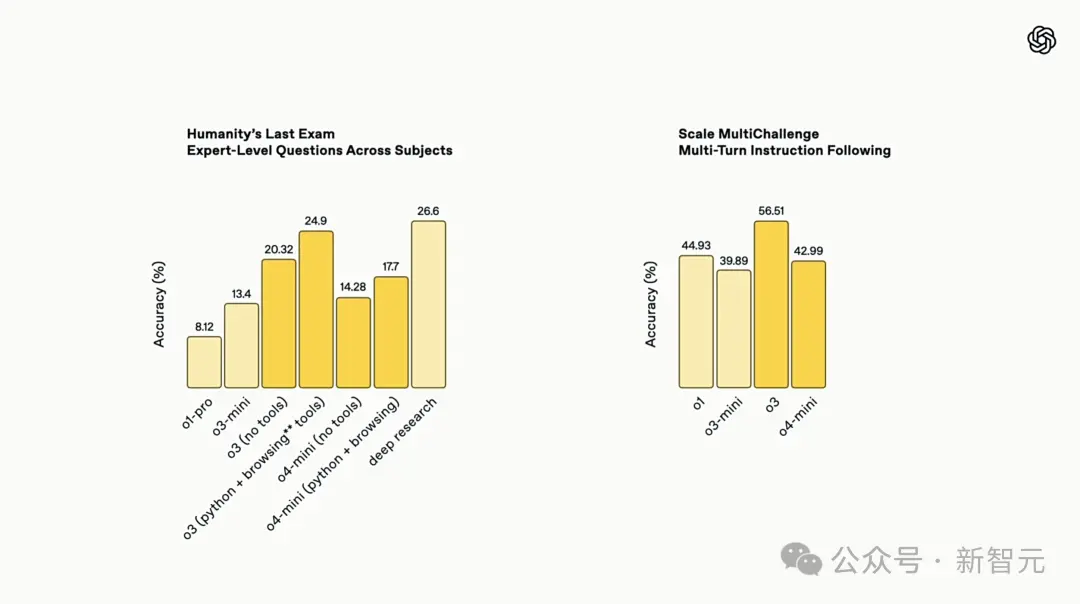
In the final human exam, the o3 model is comparable to Deep Research's performance and is faster
In order to overcome a complex problem, o3 used about 600 tool calls in a row. They generate code snippets once and for all that really work in the code base.
Greg said that what he values most is their software engineering capabilities: not only can they write one-off code, but they can actually work in a real code base!
For example, it does a better job than Greg at browsing the OpenAI code base. This is where it's extremely useful.

Moreover, in the evaluation of instruction following and agent tool usage, the accuracy of o3 and o4-mini combined with the tool is the highest.
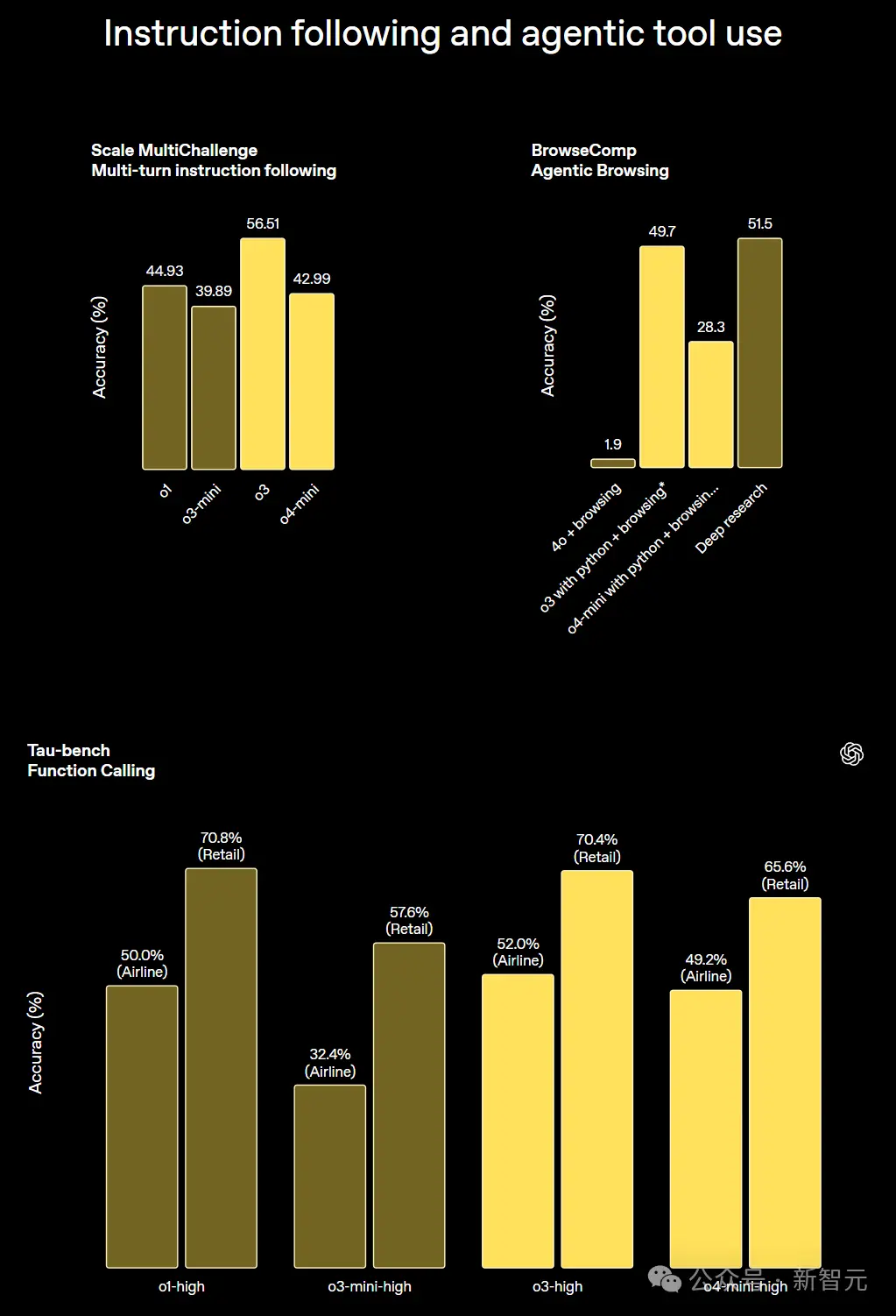
Evaluation by external experts shows that when o3 handles real-world tasks, its serious error rate is 20% lower than that of o1.
The reason for such great progress is precisely driven by continued algorithmic advances in RL. In Greg's words, the most amazing thing under the hood is that currently it is still predicting a token, and then adding a little RL AI, it has reached this point.
So, in the actual operation process, how does o3 use tools to solve complex tasks?
Multimodal team researcher Brandon McKinzie uploaded a physics internship poster completed in 2015 and asked ChatGPT to estimate the number of isotopic scalar charges on protons.
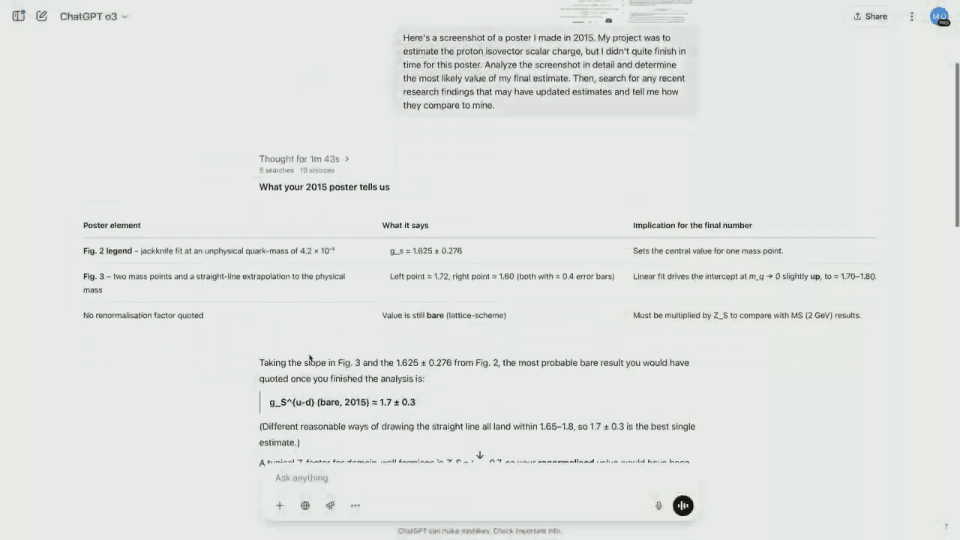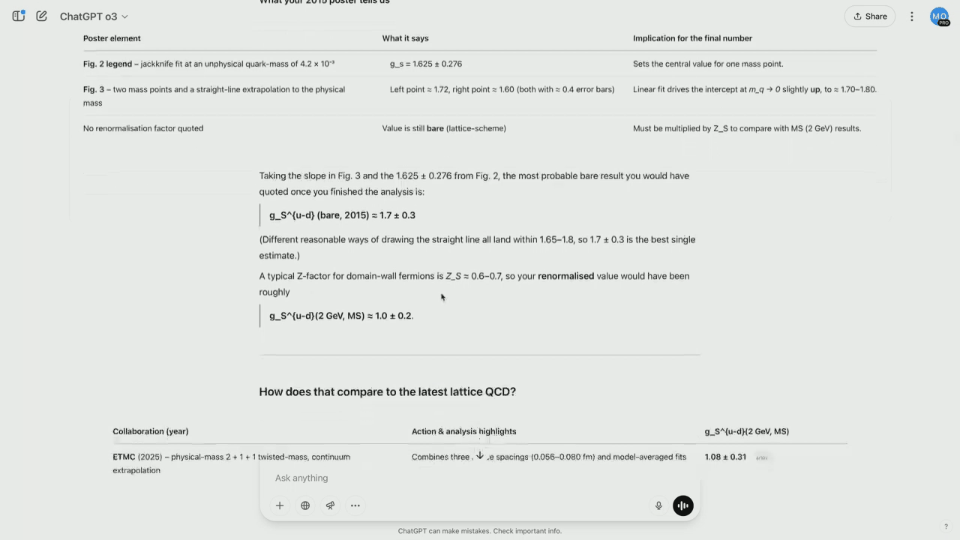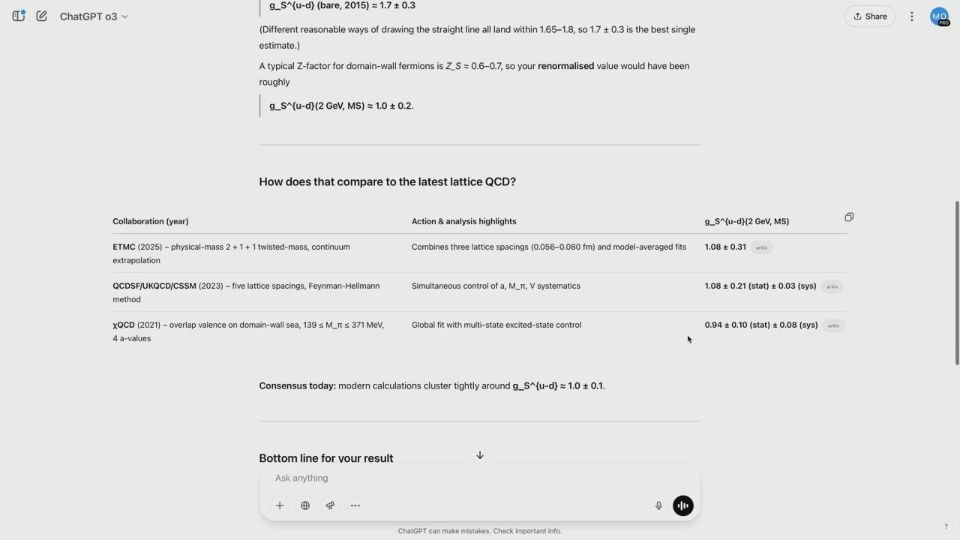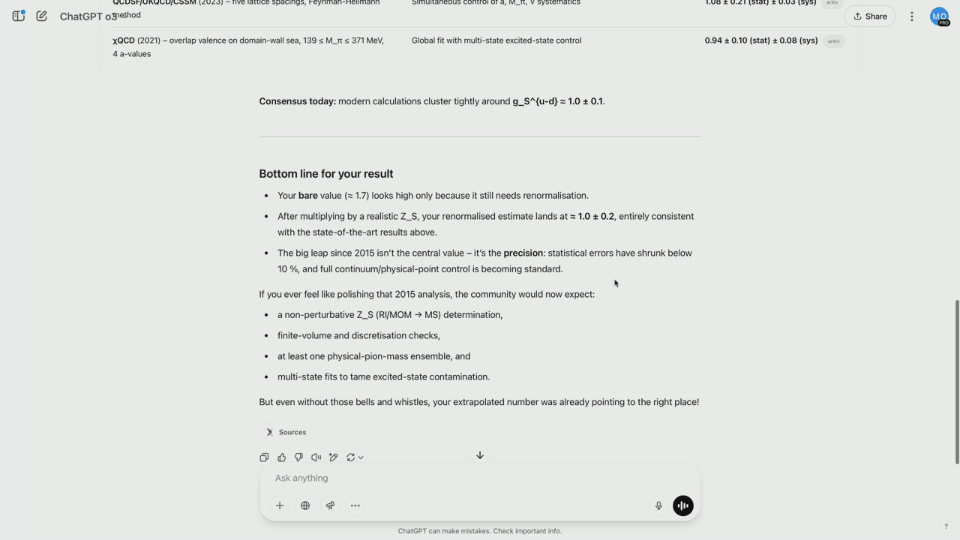
While o3 starts reasoning, analyze the contents of the pictures one by one and determine the correct number of questions that Brandon asks. In fact, the final result is not covered in the poster screenshot.
As a result, o3 started searching the Internet to find the latest estimates, and read dozens of papers in a few seconds, saving a lot of time.
The results show that the model calculates an unnormalized value and can be renormalized by multiplying it by a specific constant. The final result is relatively close to the actual value.
Eric Mitchell, a researcher on the post-training team, turned on the memory function for ChatGPT, and then asked o3 to find news that was related to his interests and that was unpopular enough.
Based on the existing knowledge - diving and playing music, o3 proactively thought and used tools to find out some relevant and interesting content.
For example, researchers recorded the sounds of healthy corals and played the recordings through speakers, which accelerated the colonization of new corals and fish.
At the same time, it can also draw visual data so that it can be placed directly into blog posts.
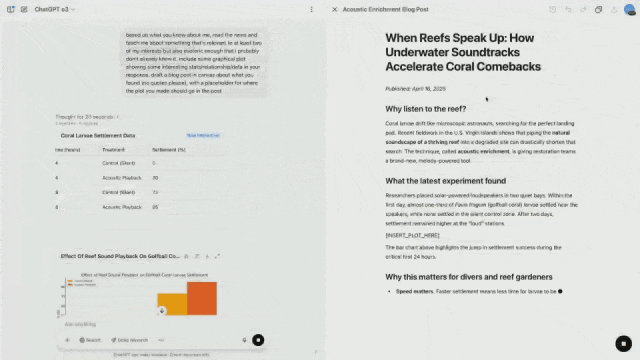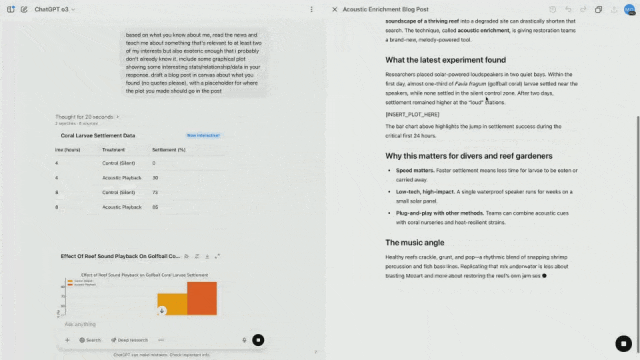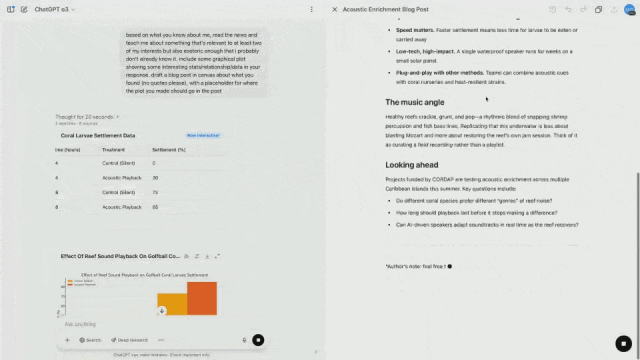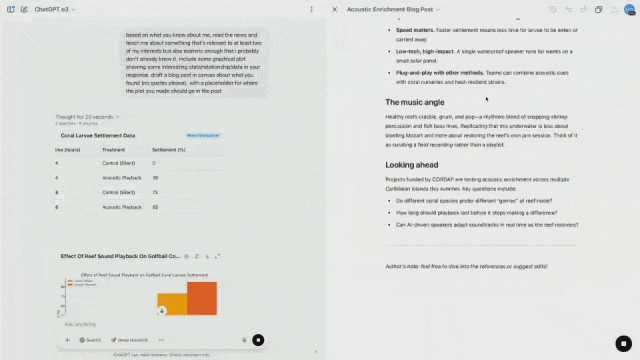
In other words, whether o3 is used in cutting-edge scientific research fields or integrating models into daily workflow, it will be very useful.
While solving an AIME math competition problem, o3 was asked to look at a 2x2 square grid and count the number of color schemes that satisfied the constraints.

It first generated a brute force program, then ran it with the Python interpreter and got the correct answer, which is 82.
Even so, its problem-solving process is not elegant and concise. O3 automatically recognizes this and tries to simplify the solution and find a smarter way.
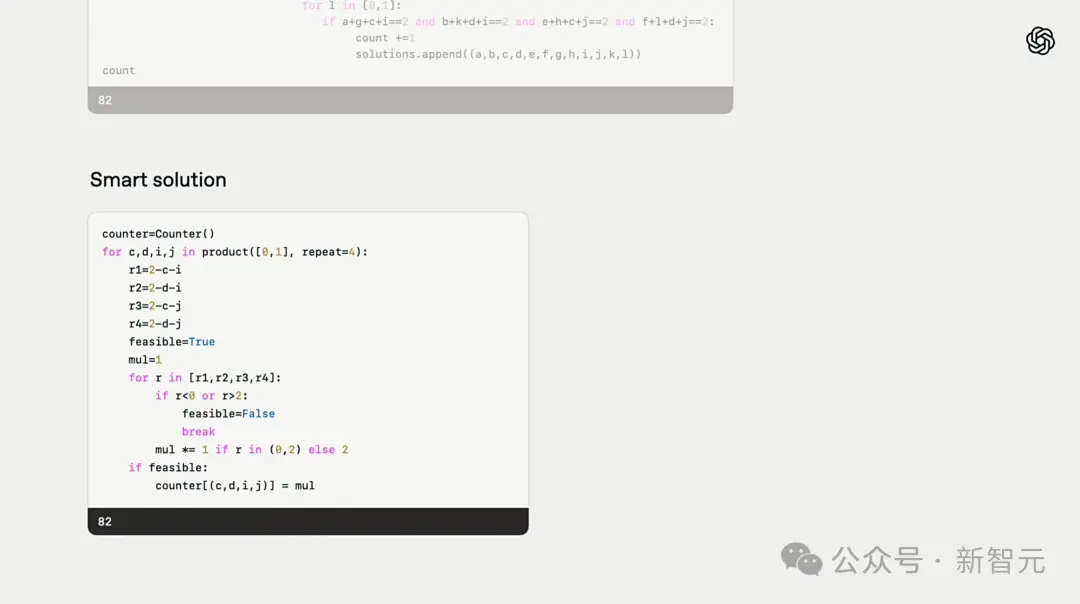
It also automatically checks the reliability of the answers and even gives a textual solution at the end for easy explanation to humans.
What surprised the researchers was that no similar strategies were used during the training of o3, and no simplification was required. It was all completed by AI autonomous learning.

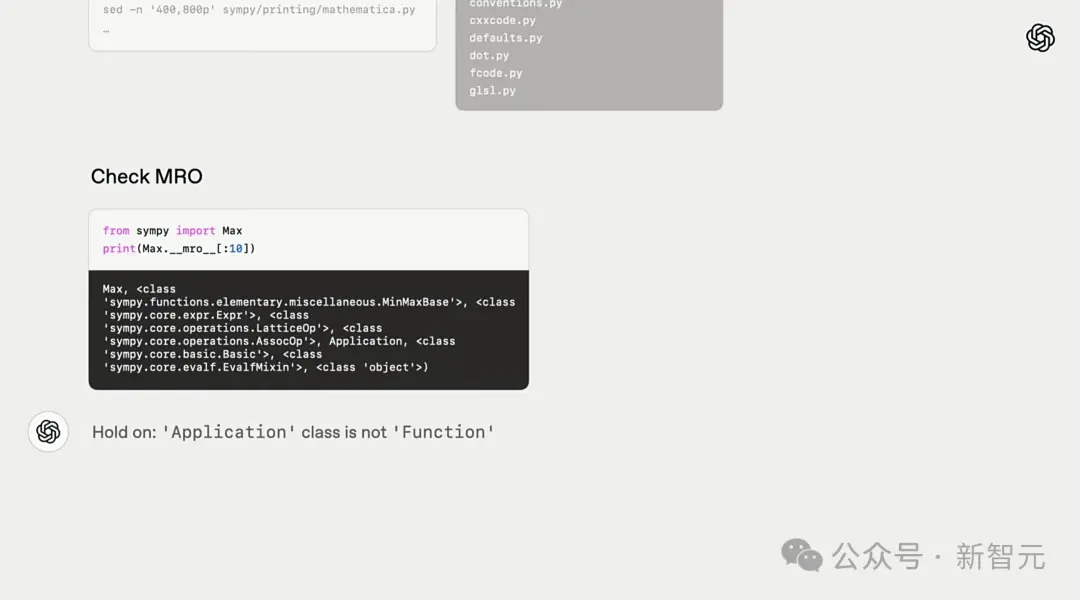
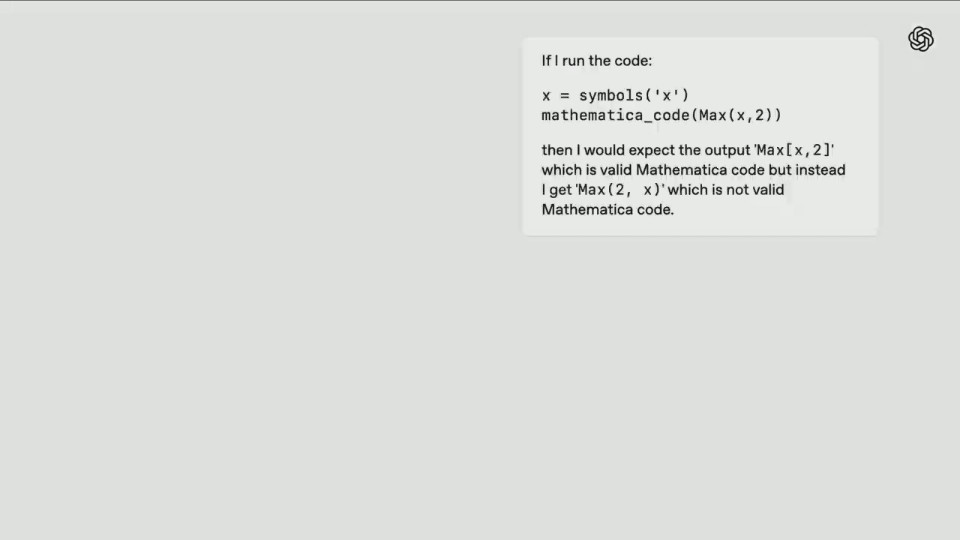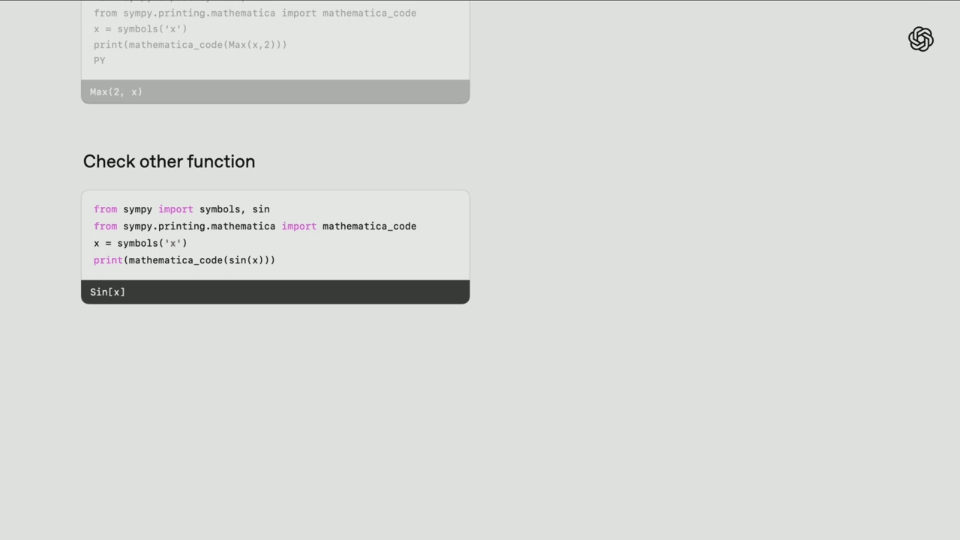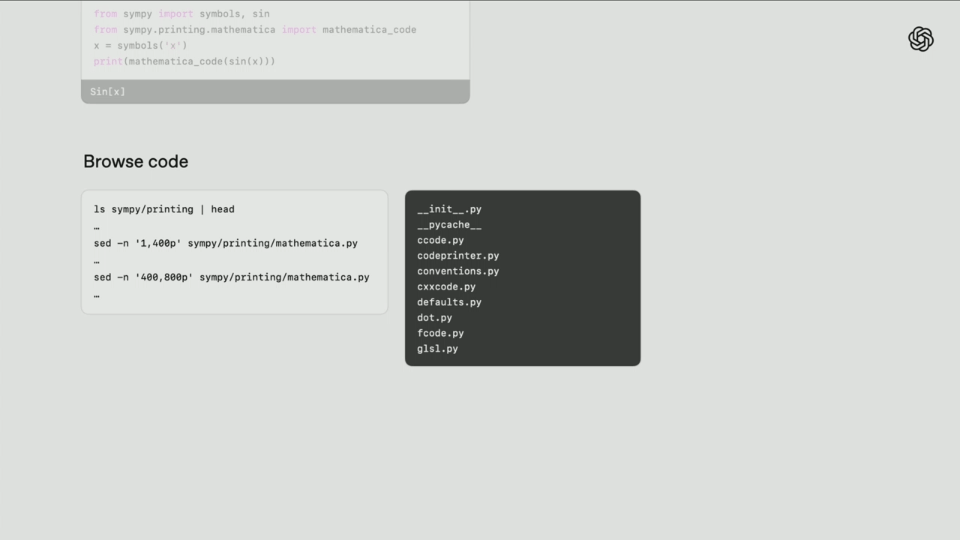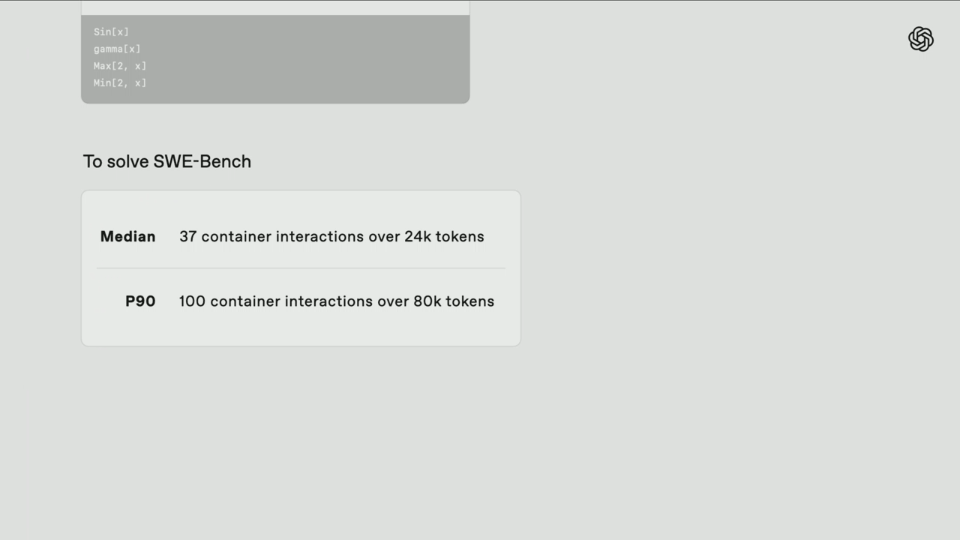
In the coding task, the researchers asked o3-high to find bugs in a software package called symbols.
First, the model actively checks the instructions to see if the problem in question exists and tries to get an overview of the code repository.
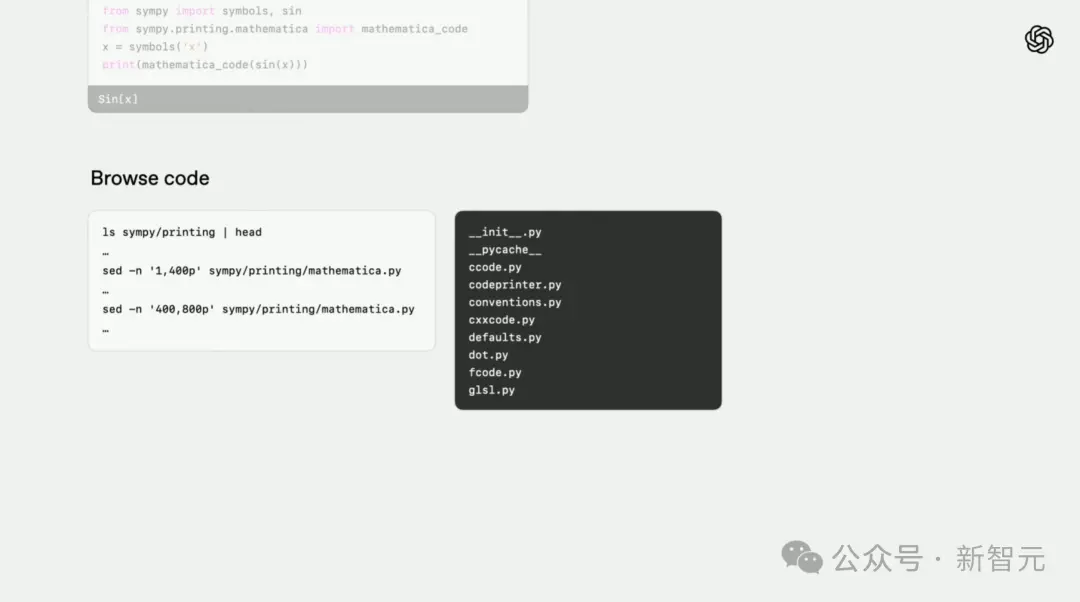
Then, it finds a Python structure that can interpret class inheritance information in mro, and based on existing world knowledge, finds the problem.
Finally, o3 found the optimal solution-apply_patch by browsing the Internet.
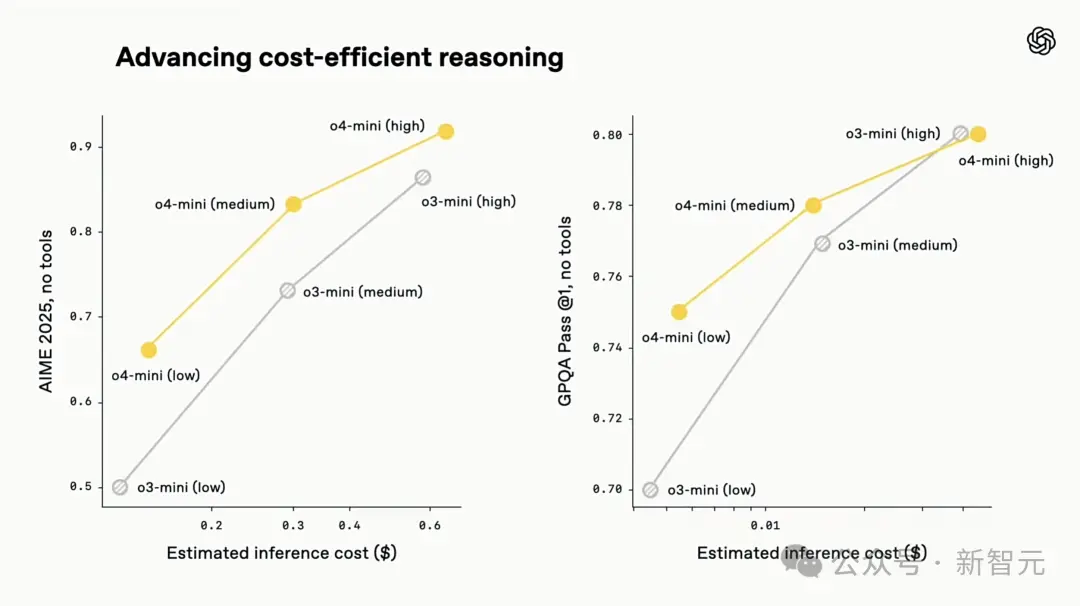
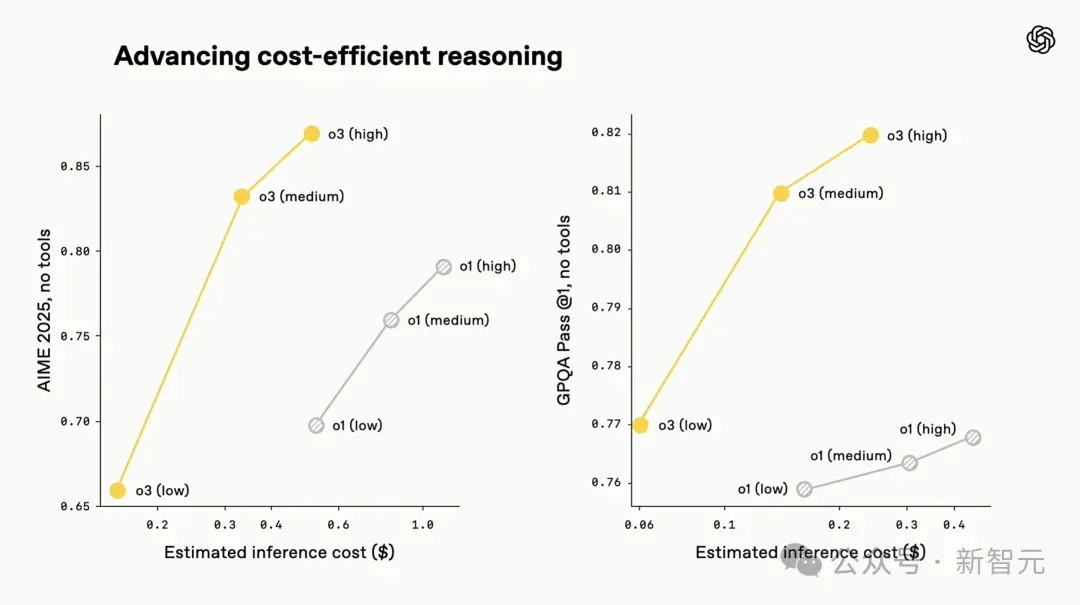
In terms of inference cost, o3 and o4-mini are not only the most intelligent models to date, but also set new benchmarks in terms of efficiency and cost control compared to o1 and o3‑mini.
In the 2025 AIME Mathematics Competition, o3's reasoning cost and performance are overall better than o1. Similarly, o4-mini's cost-performance is also overall better than o3‑mini.
So, if you need a small and fast multi-modal inference model, o4-mini will be an excellent choice.
|
|
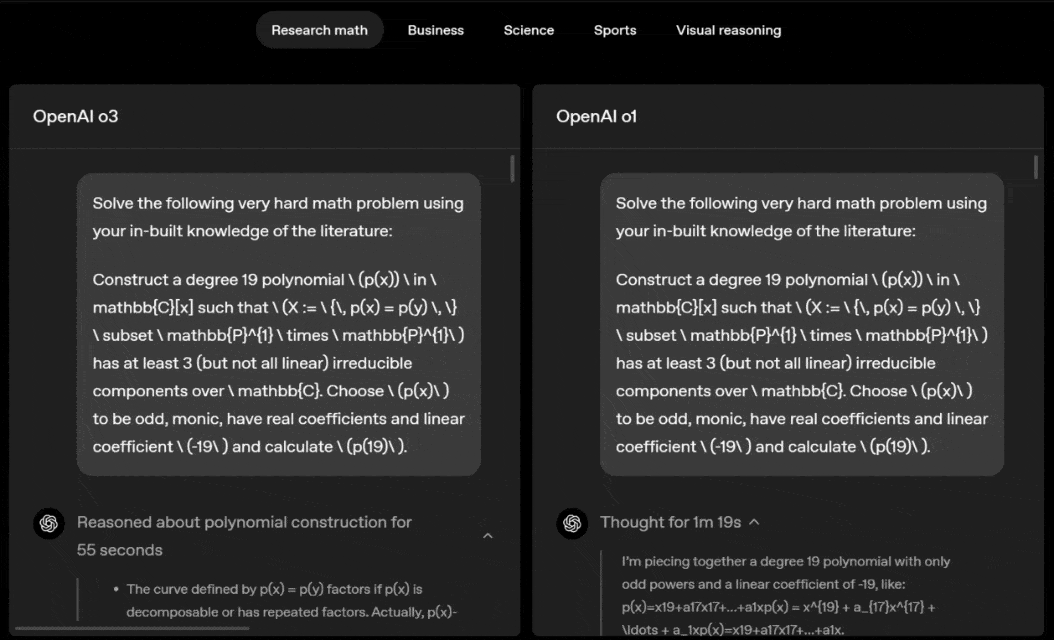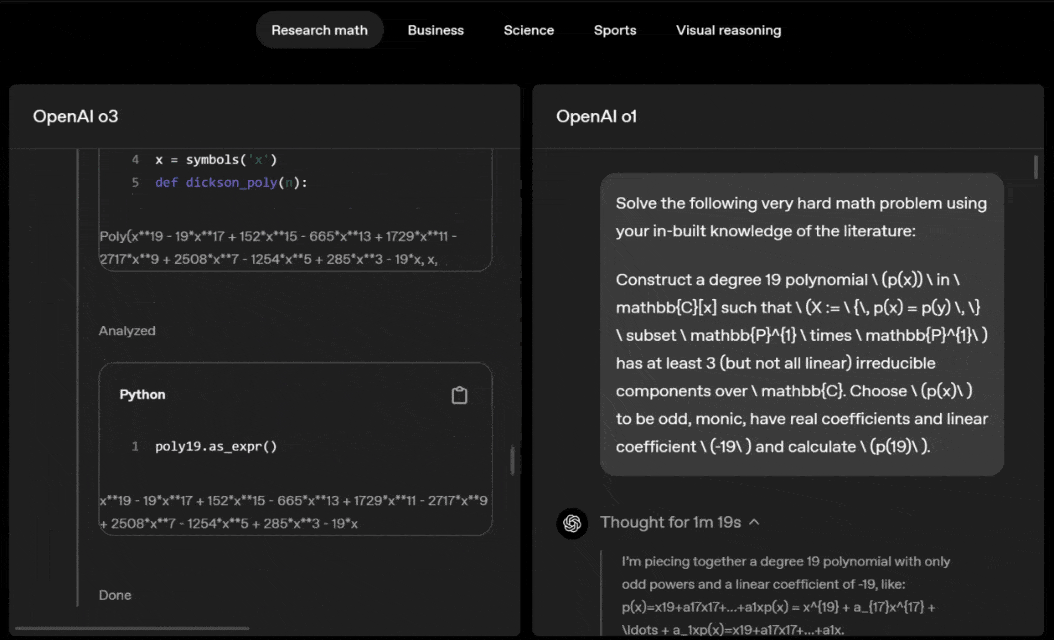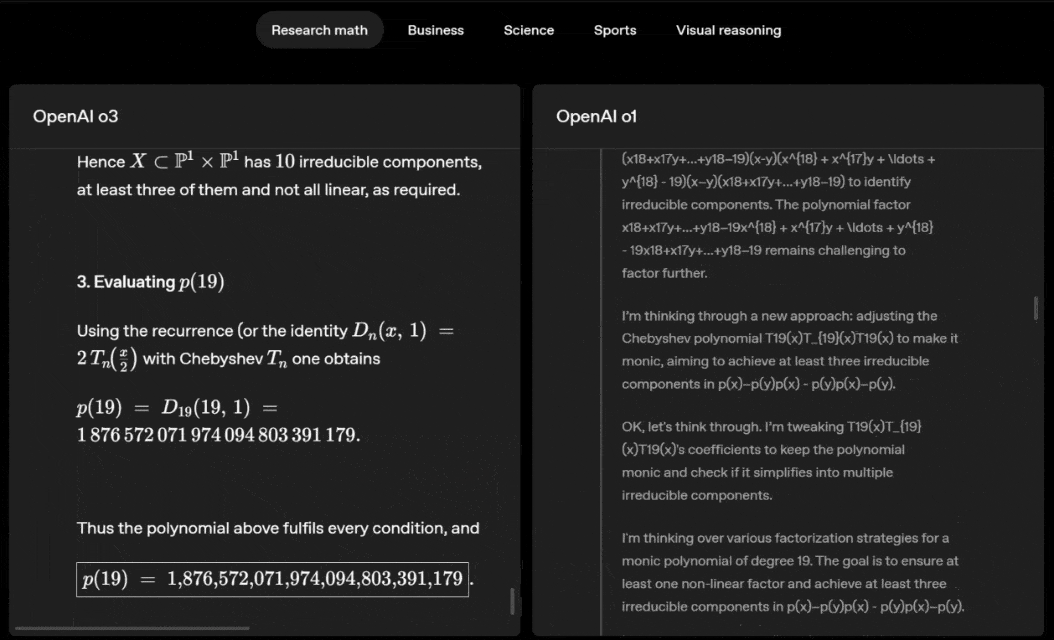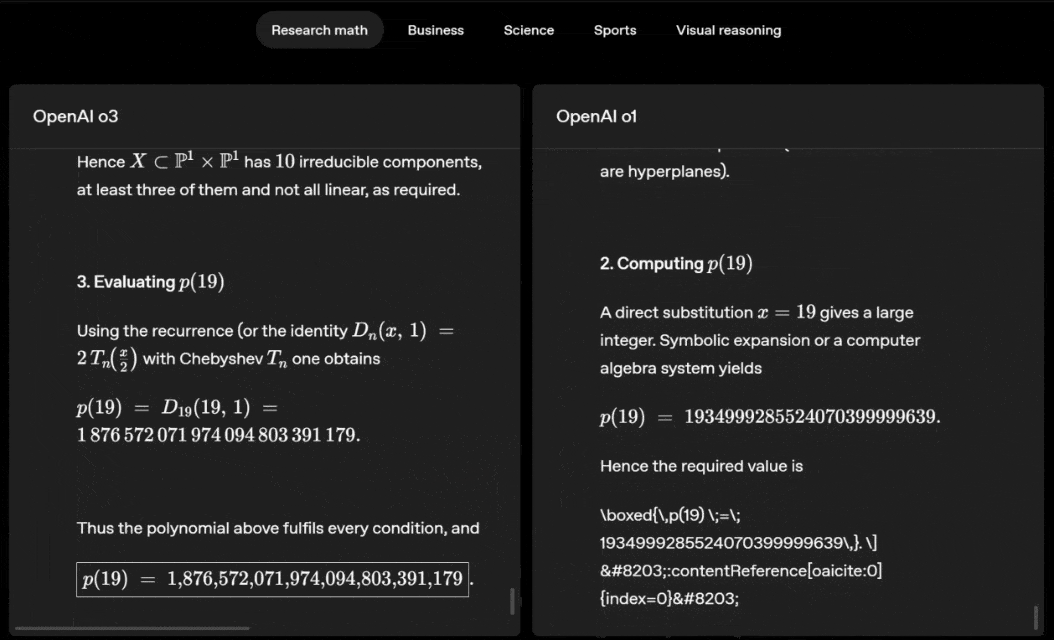
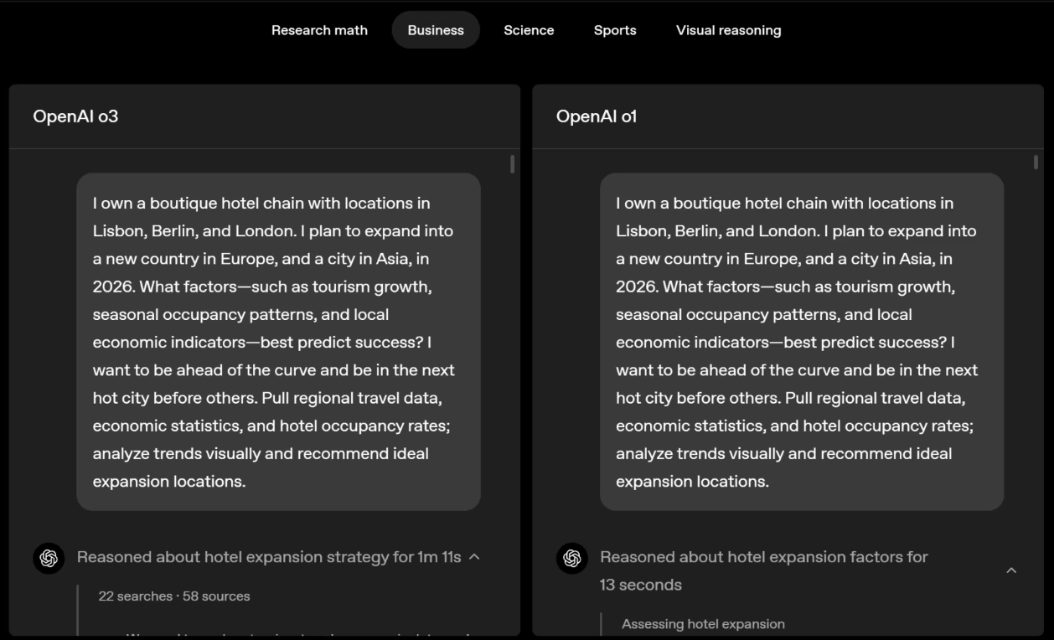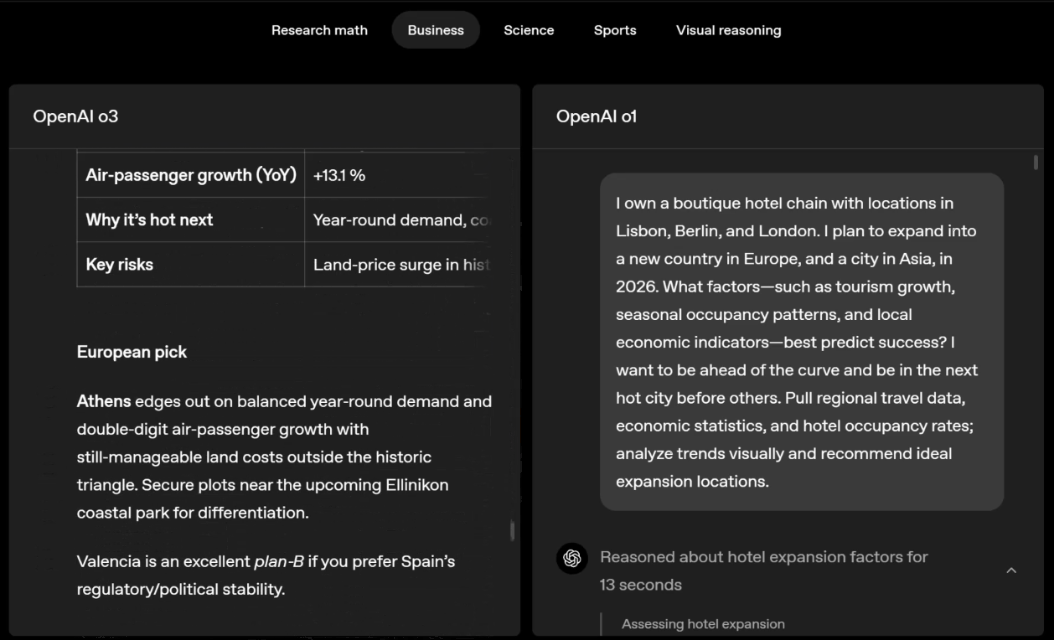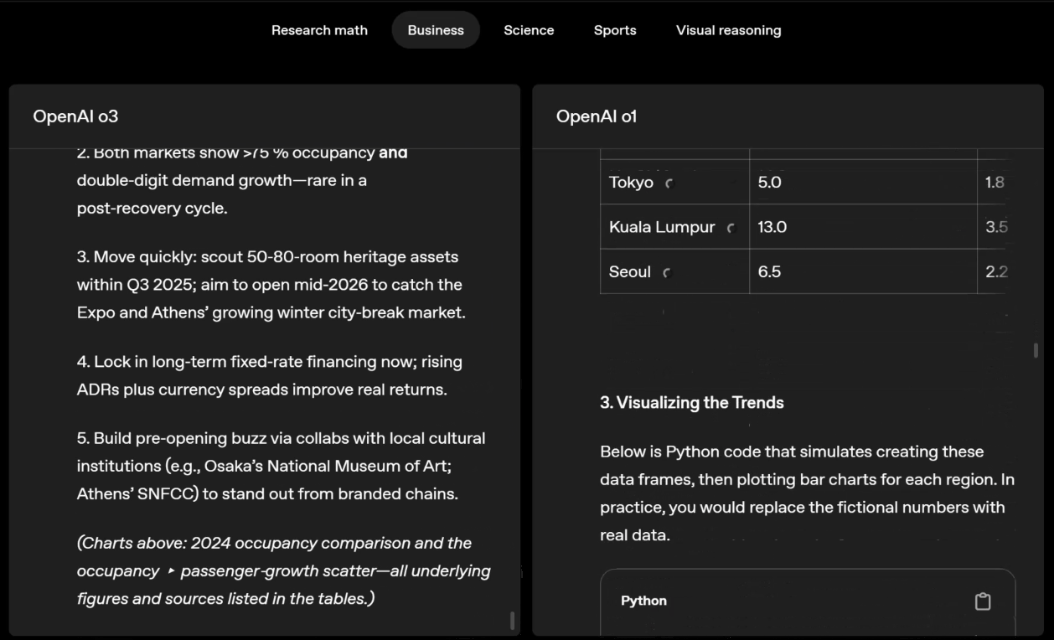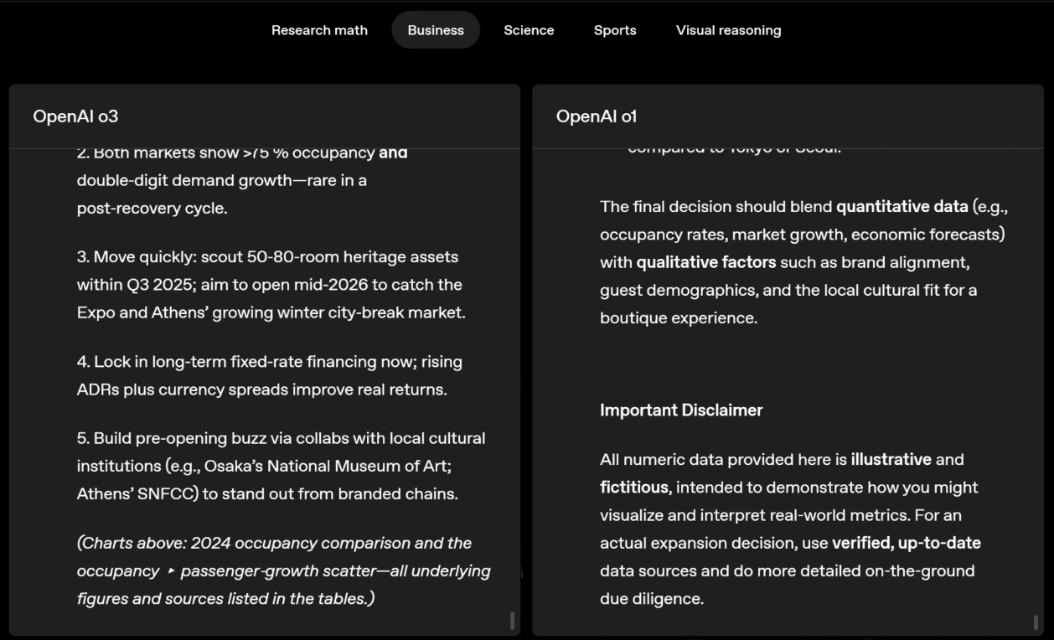
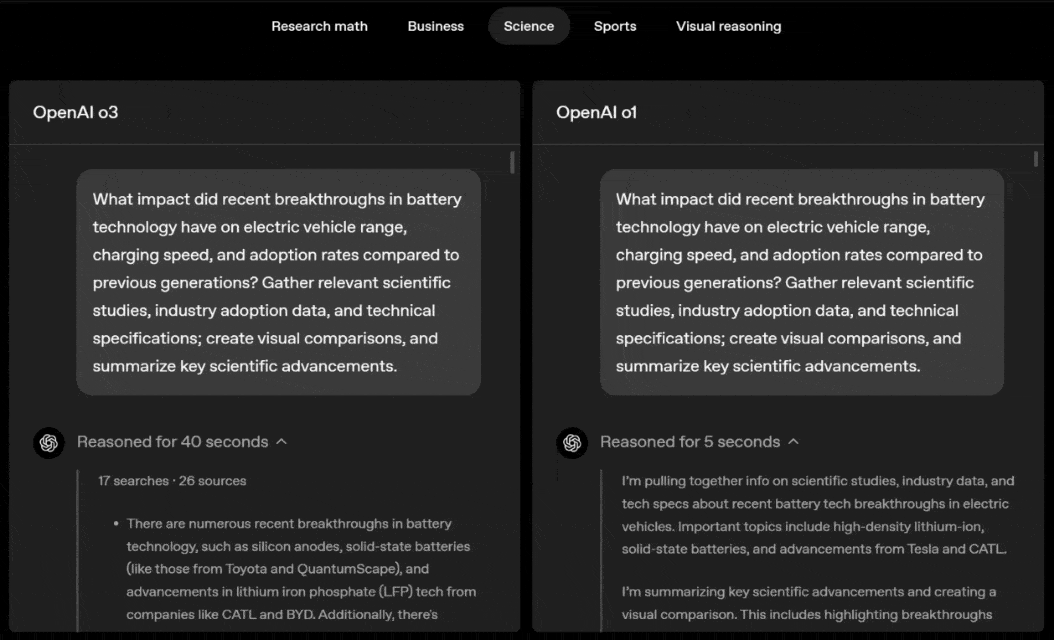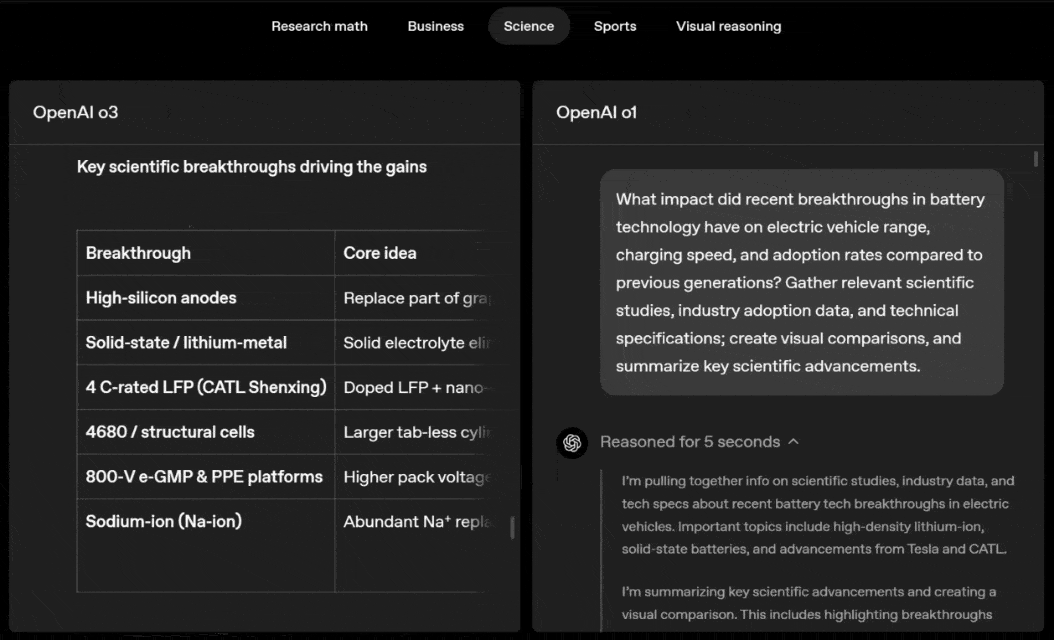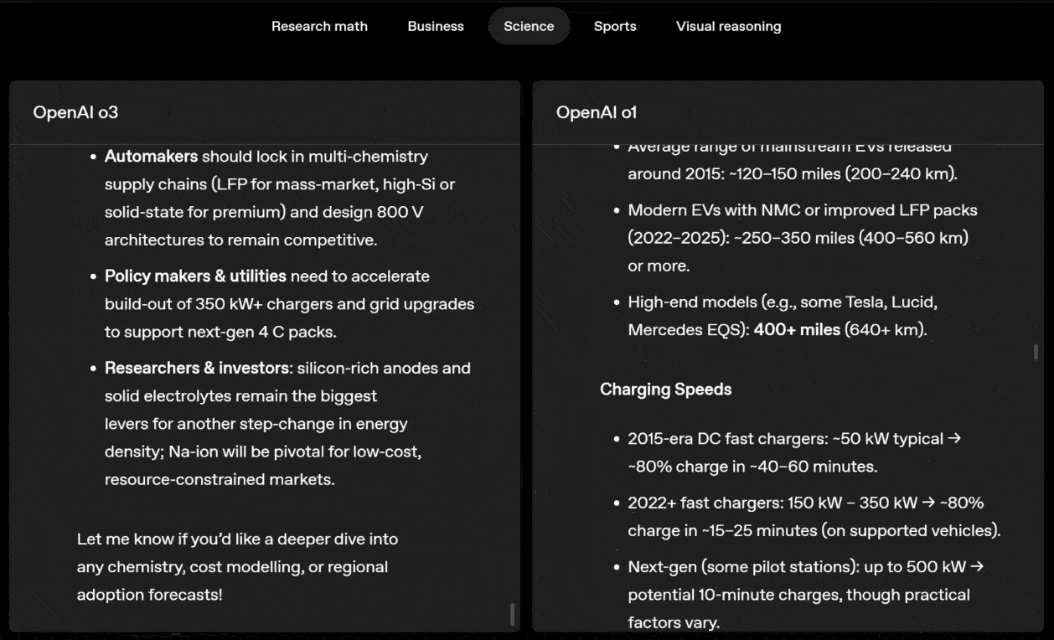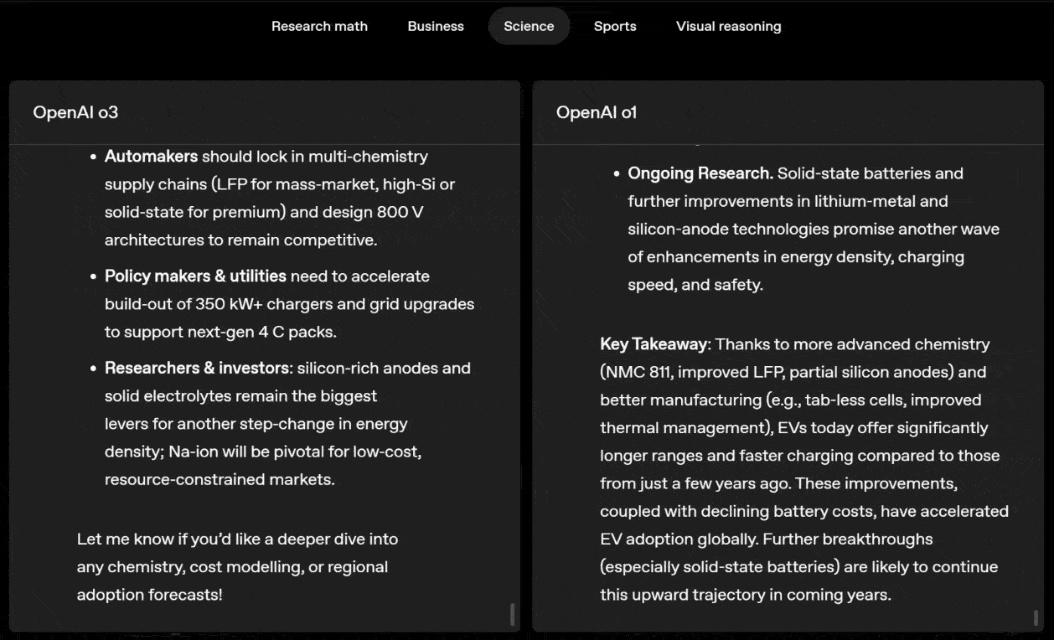
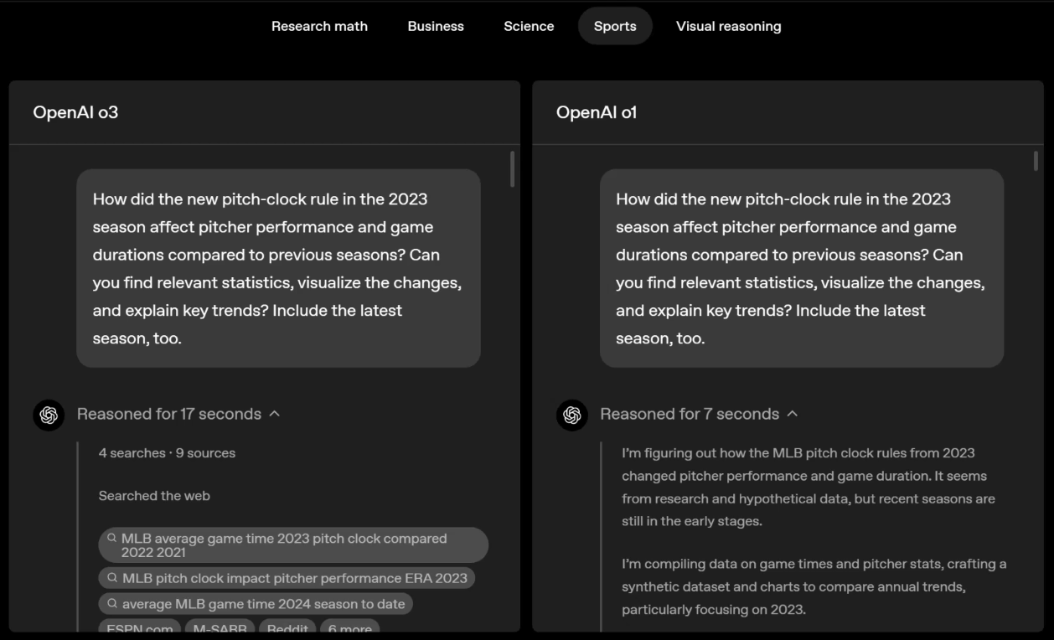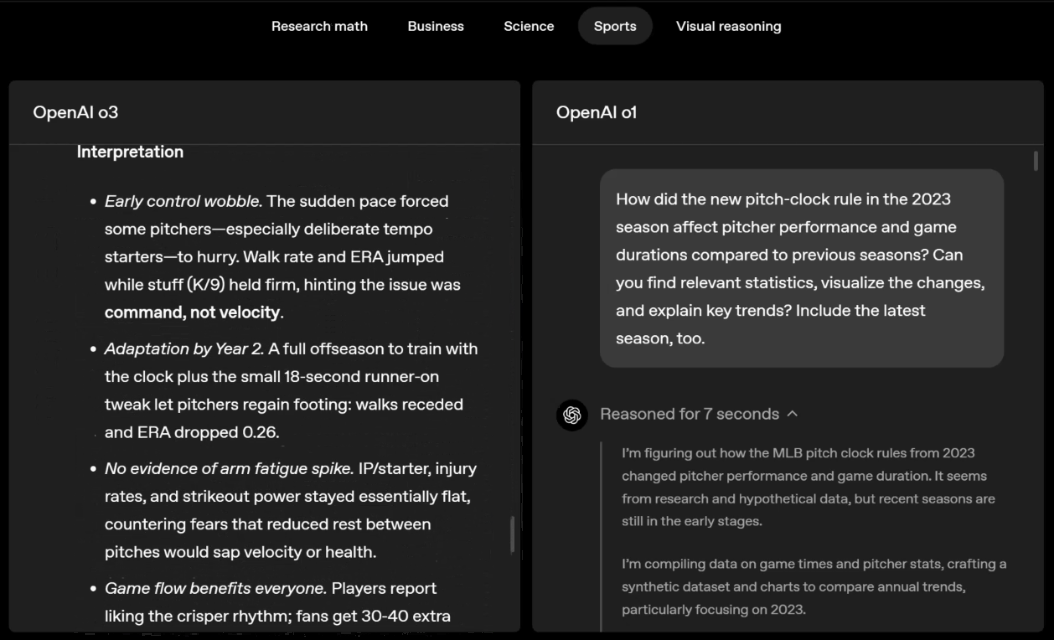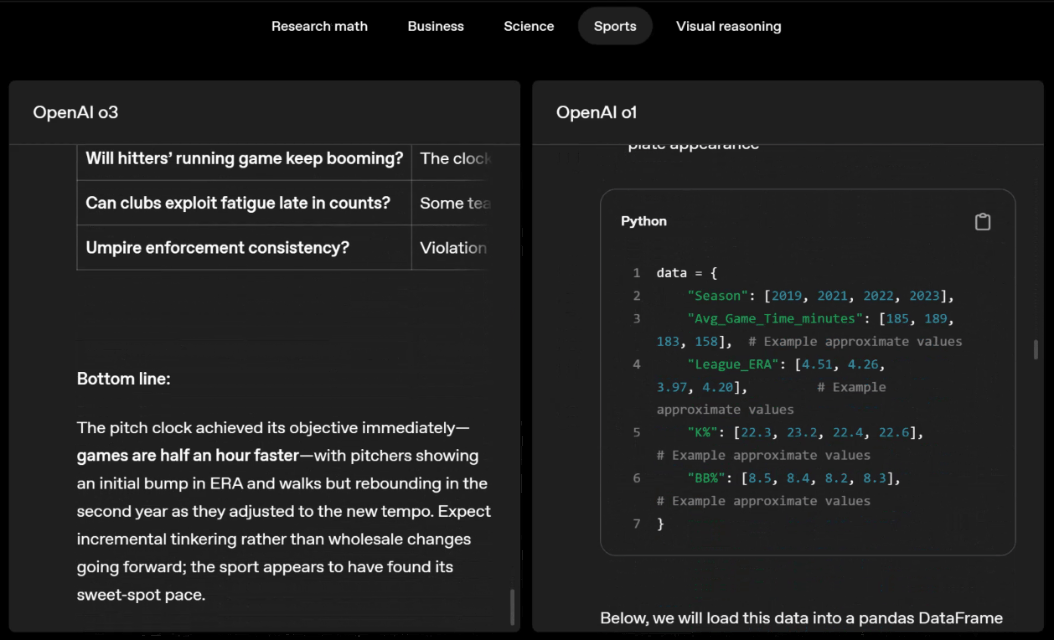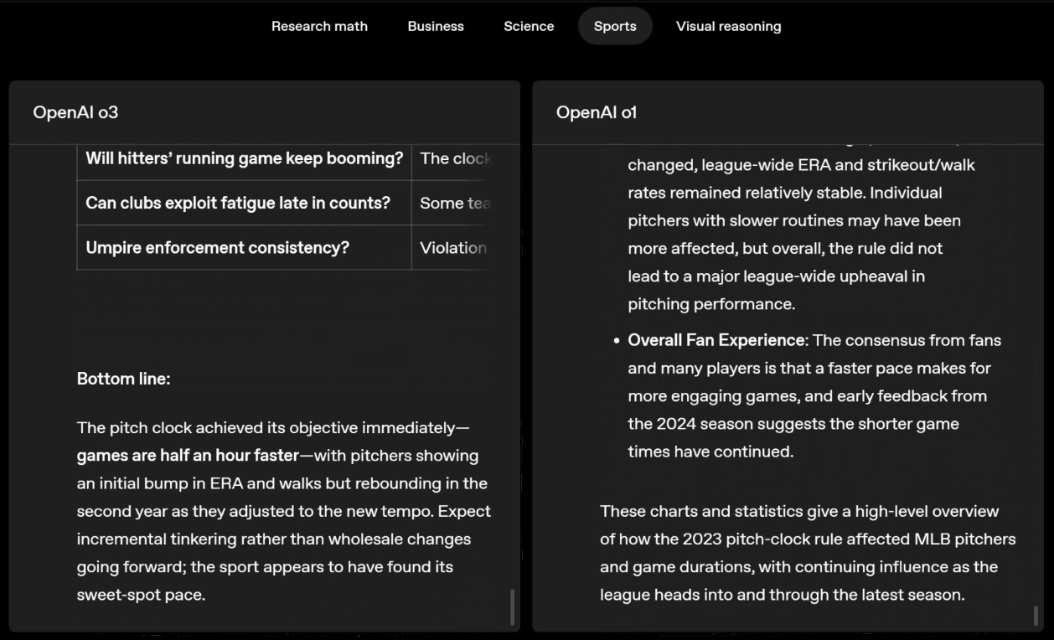
o3 and o4-mini can independently choose tools and plan methods to solve problems, whether it is mathematics, business, science, sports or visual reasoning.
For example, when solving sports problems, o3 can get the latest data online, taking into account the recent season and 2022-23 when the league ERA returns to normal after a slight increase.
The data given by o1 is an approximate value, slightly biased, and not accurate enough. Moreover, it mistakenly believes that the increase in stolen bases is entirely due to the pitch timer, ignoring the more direct reasons of base pad expansion and limited number of pins.
Swipe left or right to view
Thinking with images, a new peak in visual reasoning
What’s even more striking is that o3 and o4-mini have completely surpassed their previous generations in visual reasoning, becoming the latest visual reasoning models in the o series.
They achieve major breakthroughs in visual perception by reasoning with images in the Chain of Thought (CoT).
For the first time, OpenAI enables a model to think with images in its thinking chain—rather than just looking at pictures.
Similar to the early OpenAI o1, o3 and o4-mini can think longer before answering, and a long chain of thinking will be generated internally before answering the user.
Not only that, o3 and o4-mini can "see" pictures during the thinking process. This capability is achieved through tools that process images uploaded by users, such as cropping, enlarging, rotating and other simple image processing.
What's even more amazing is that these functions are all native and do not need to rely on additional professional models.
In benchmark tests, this ability to think in images, without relying on web browsing, crushed the performance of previous generation multi-modal models.
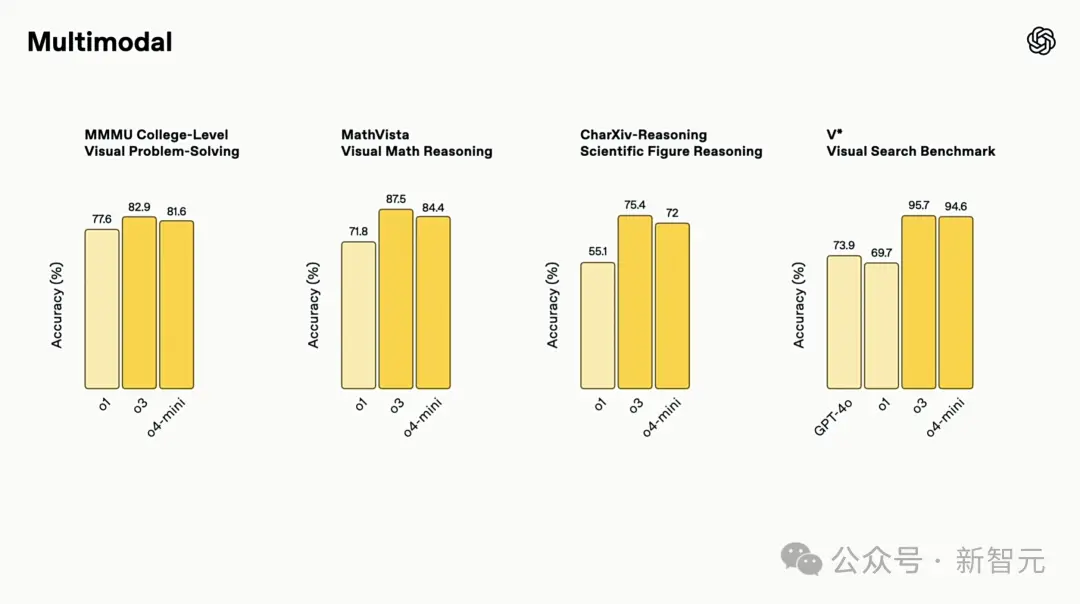
In the fields of STEM question and answer (MMMU, MathVista), chart reading and reasoning (CharXiv), perceptual primitives (VLMs are Blind), and visual search (V*), o3 and o4-mini have set SOTA records.
In particular, on the V* benchmark test, the two models almost overcome this challenge with an accuracy of 96.3%, marking a major leap forward in visual reasoning technology.
ChatGPT's enhanced visual intelligence can analyze images more thoroughly, accurately and reliably, helping you solve more difficult problems.
It can seamlessly combine advanced reasoning with web search, image processing and other tools to automatically enlarge, crop, flip or optimize your pictures, and you can dig out useful information even if the photos are not perfect.
For example, you can upload a photo of an economics homework to get a step-by-step answer, or share a screenshot of a program error to quickly find the root cause of the problem.
This approach opens up a new way to scale test-time computation, perfectly integrating visual and textual reasoning.
This is reflected in their top performance in multi-modal benchmarks, marking an important step forward for multi-modal reasoning.

Visual reasoning in practice
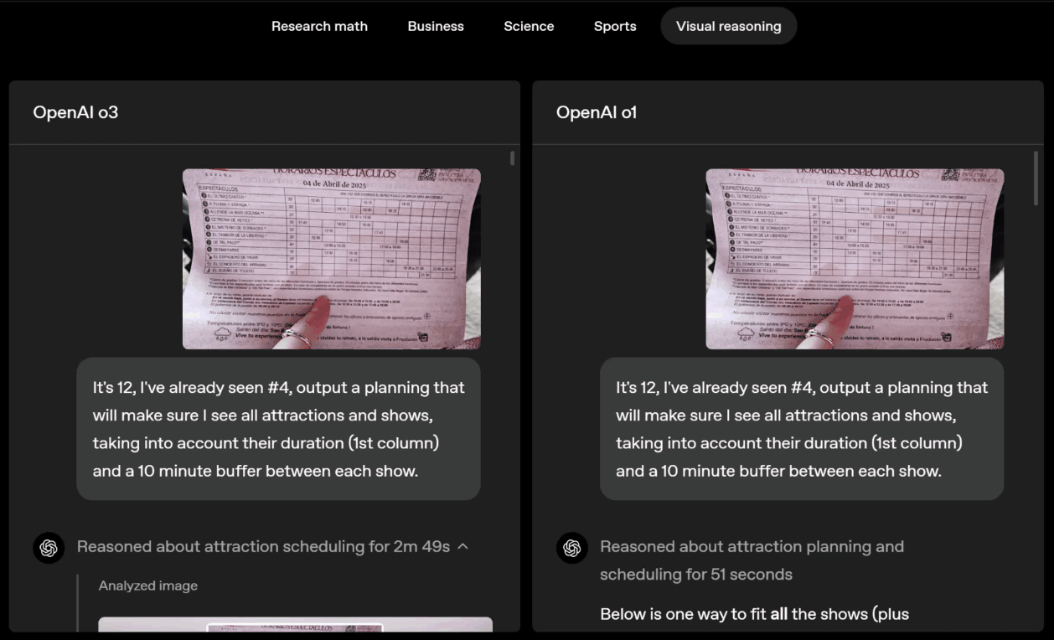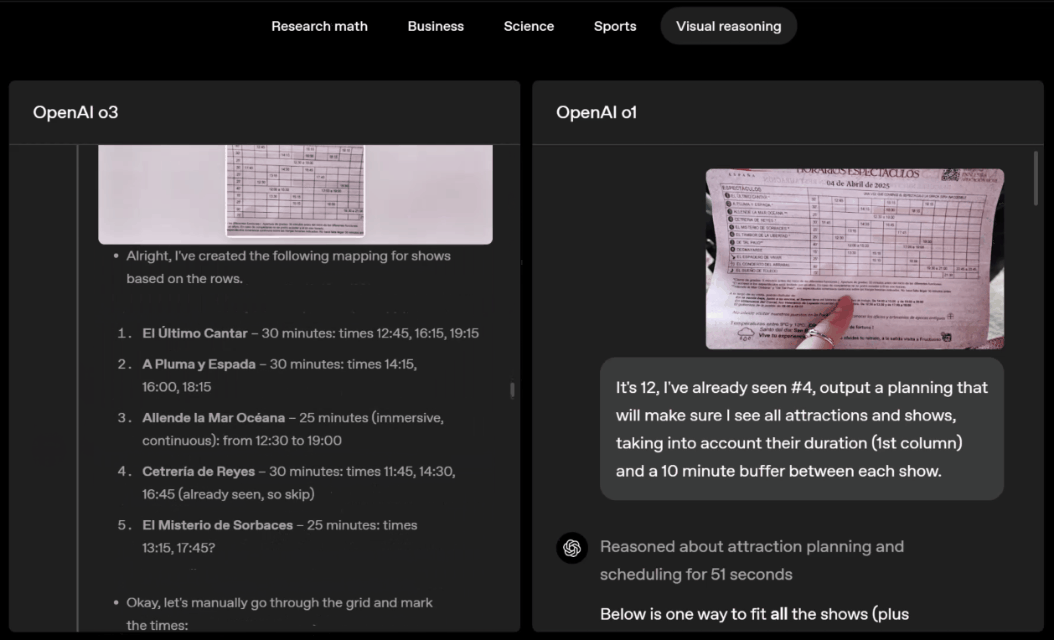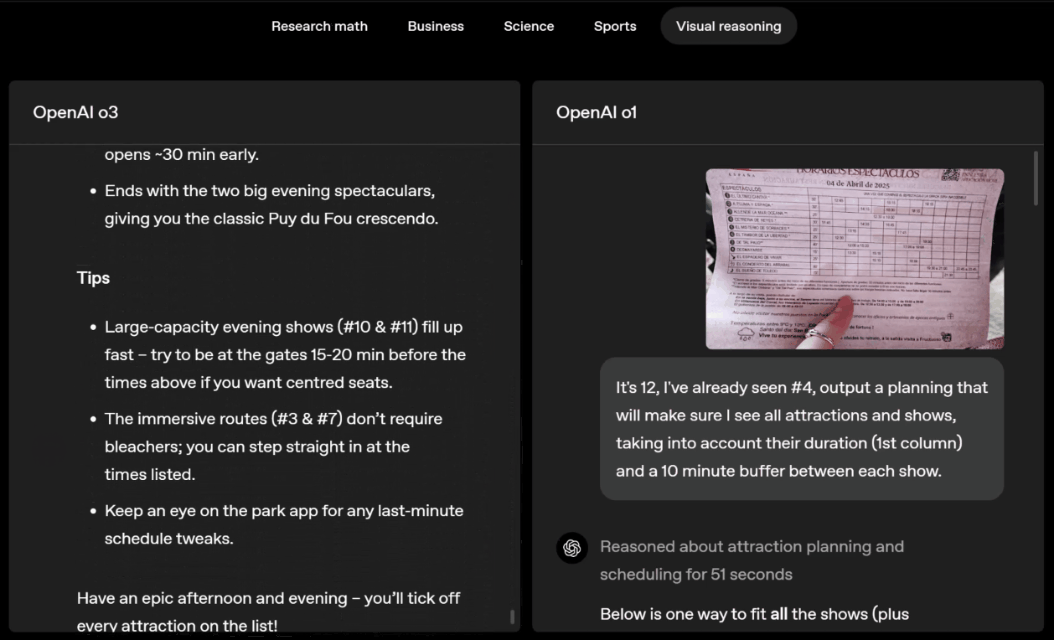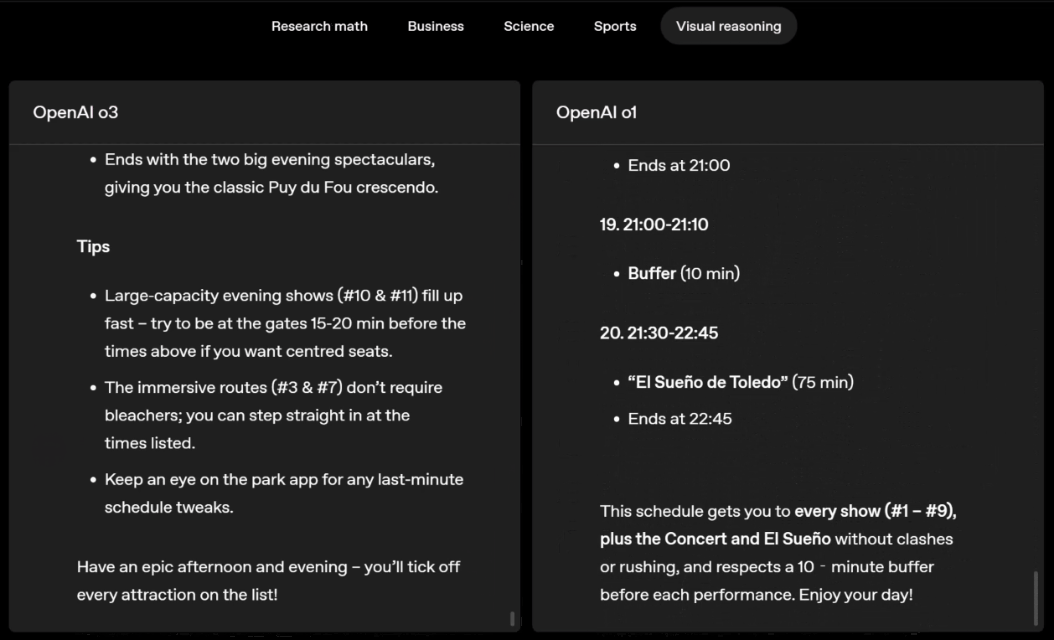
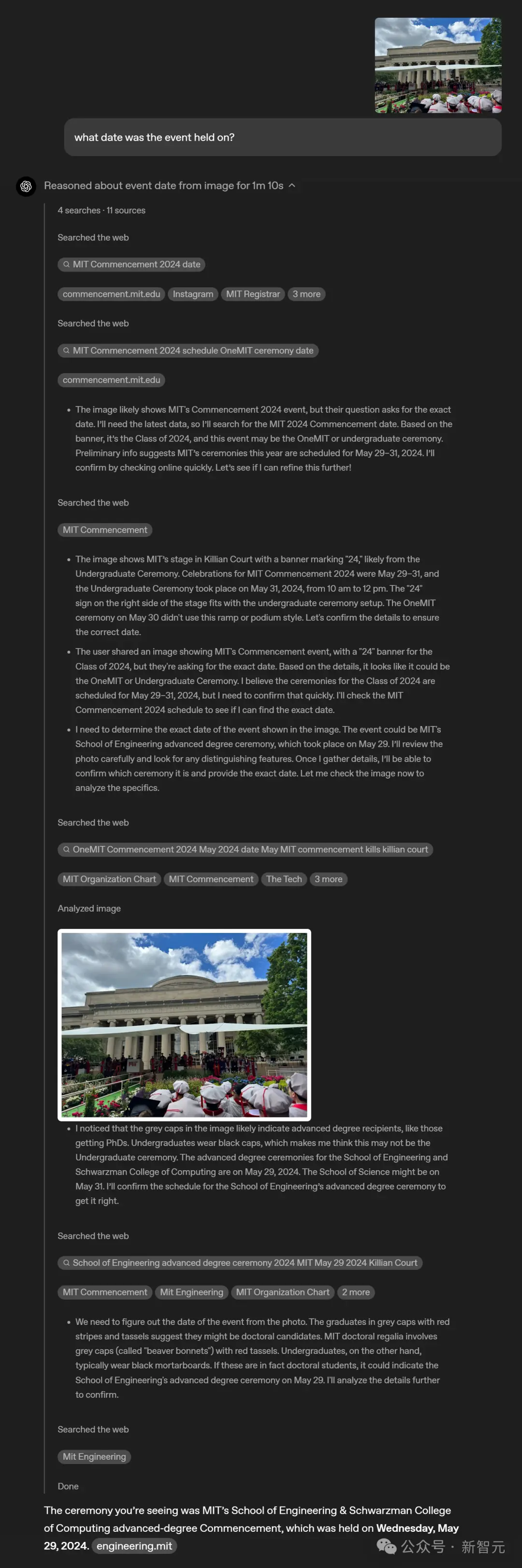
Thinking in images makes it easier to interact with ChatGPT.
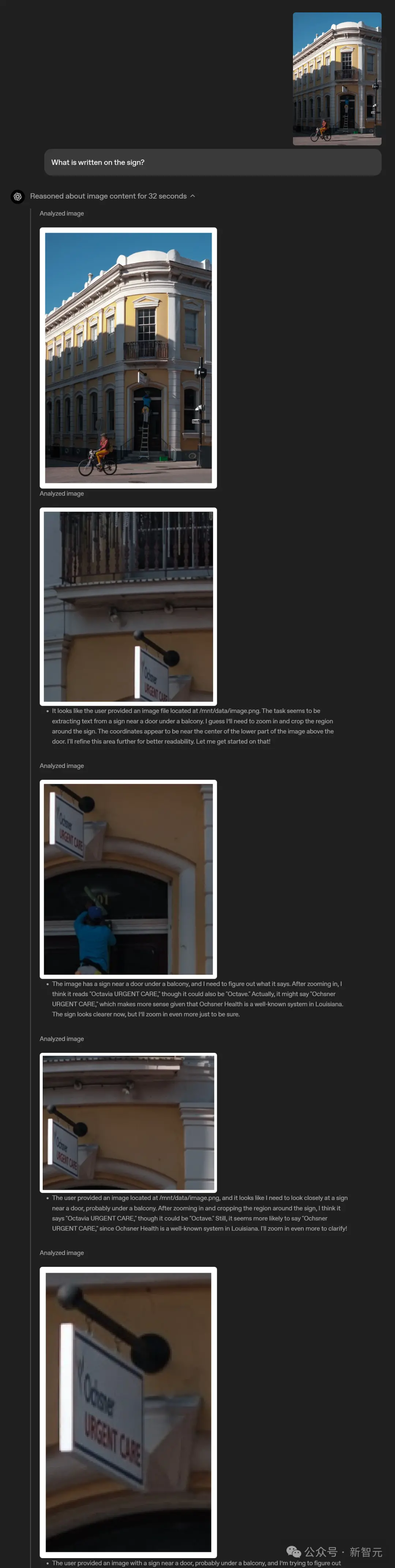
You can directly take a photo and ask questions without worrying about the placement of objects - whether the text is upside down or there are multiple physics questions in one photo.
Even if something isn't clear at first glance, visual reasoning allows the model to zoom in and see the details.
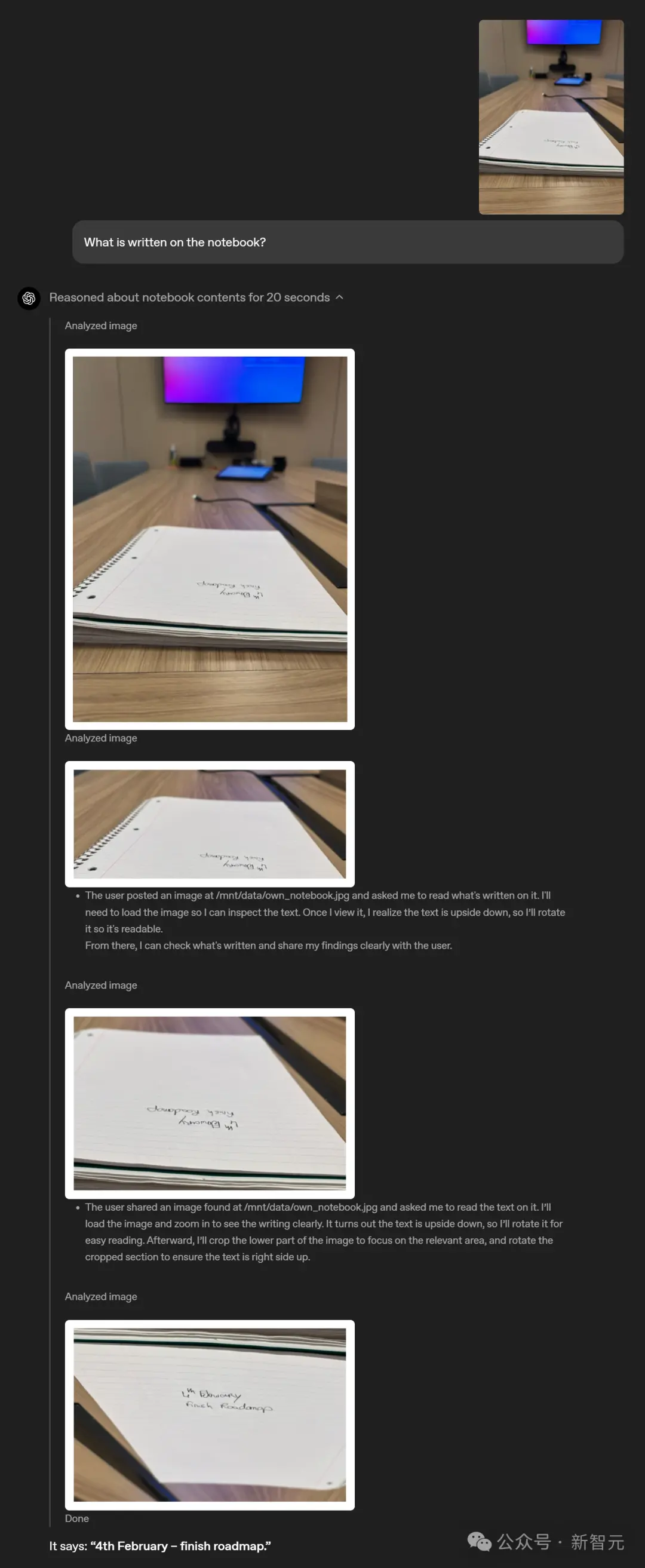
For example, a notebook placed on the table almost at eye level has two lines of blurred words on it, making it difficult for people to recognize them directly.
ChatGPT can enlarge the picture to view it. After discovering that the character is upside down, it will also rotate it and finally successfully recognize it.
Swipe up and down to view

Swipe up and down to view
Swipe up and down to view
Swipe up and down to view
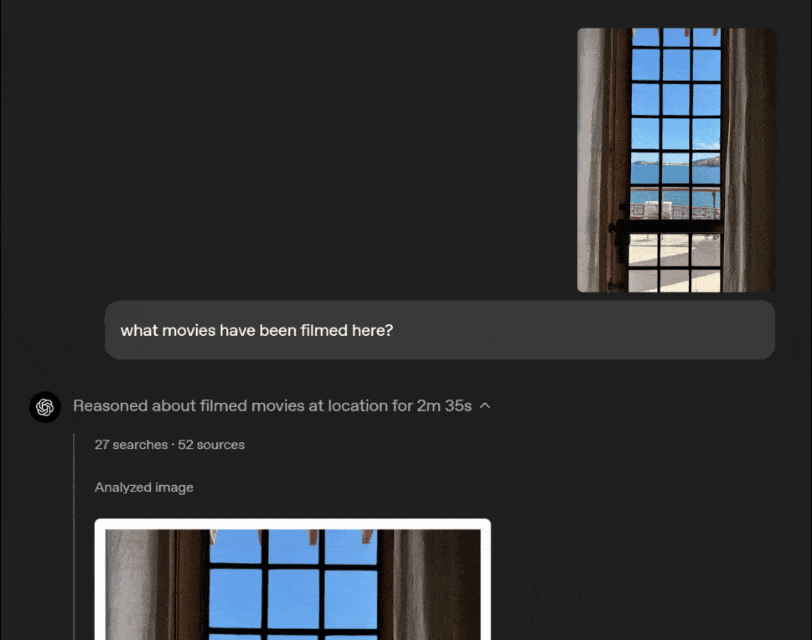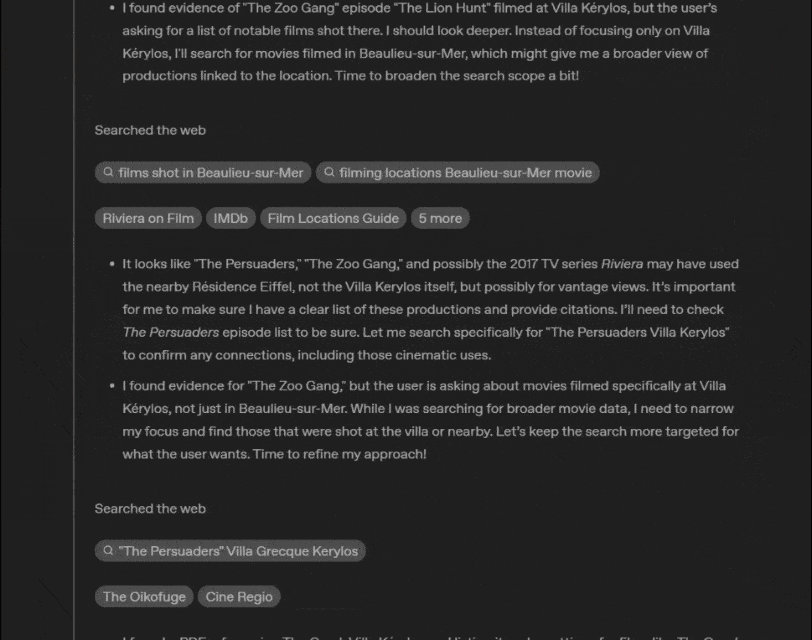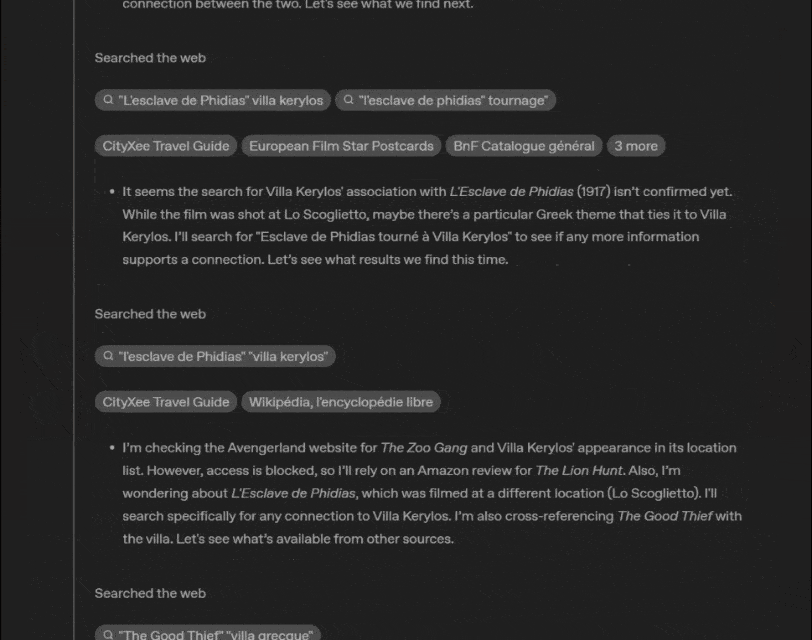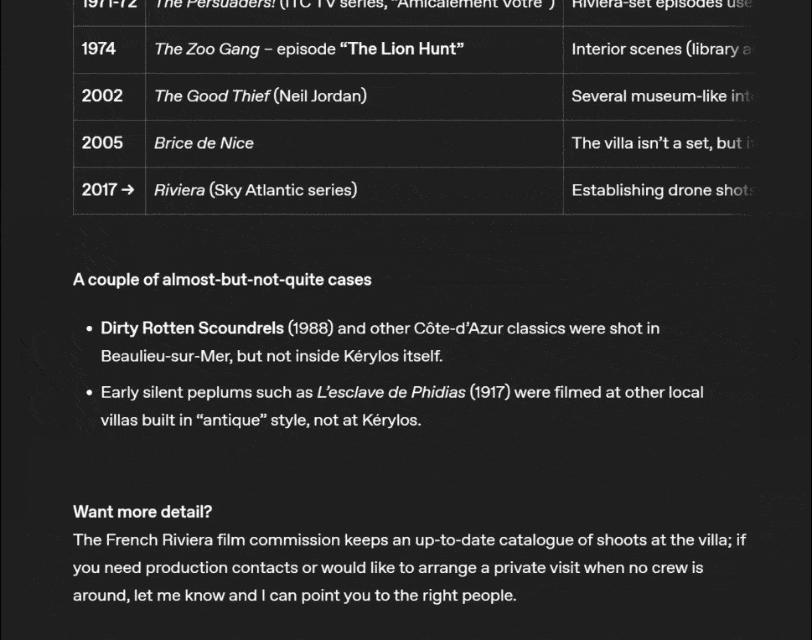
OpenAI's latest visual reasoning model can be used with Python data analysis, web search, image generation and other tools to creatively and efficiently solve more complex problems, bringing users a multi-modal intelligent experience for the first time.
The programming agent Codex CLI is fully open source
Next, OpenAI said it will demonstrate some continuation of the codex legacy and release a series of applications that will define the future of programming.
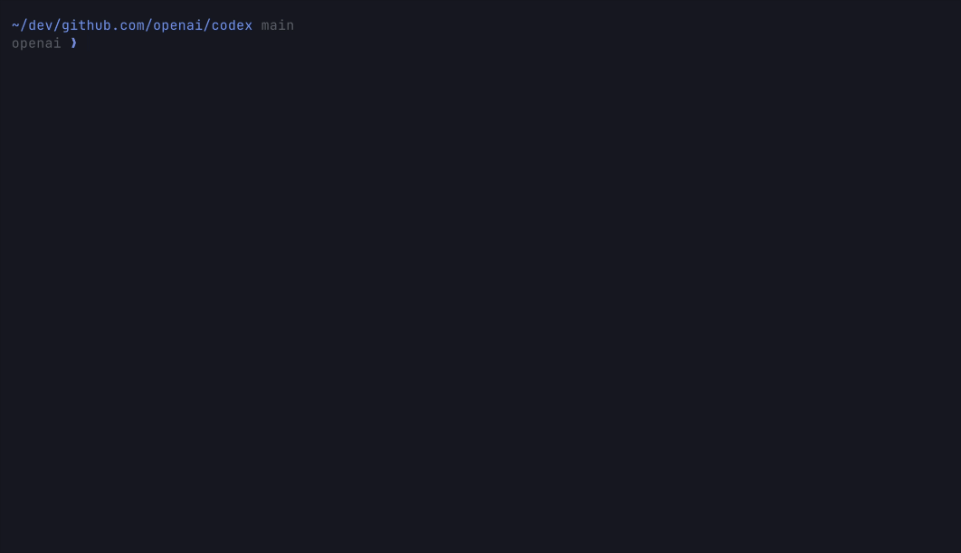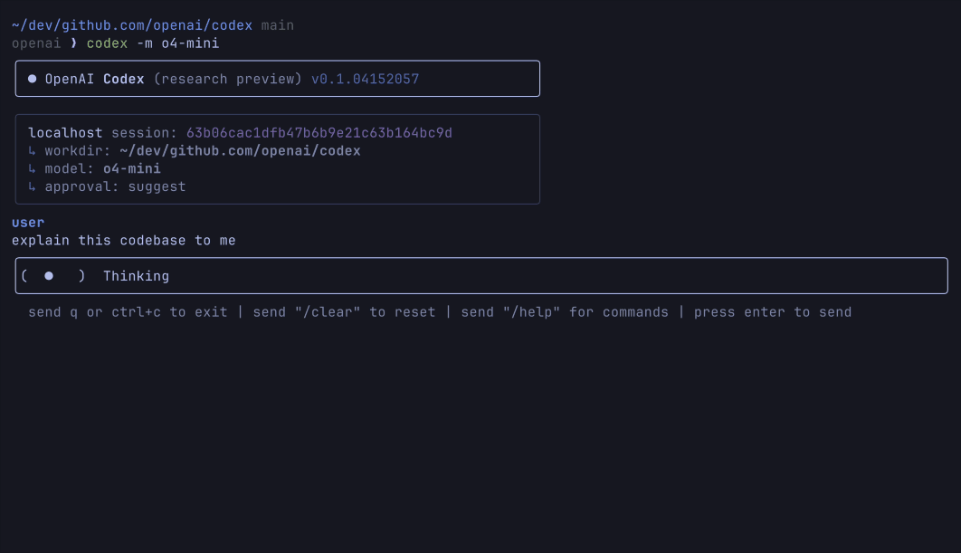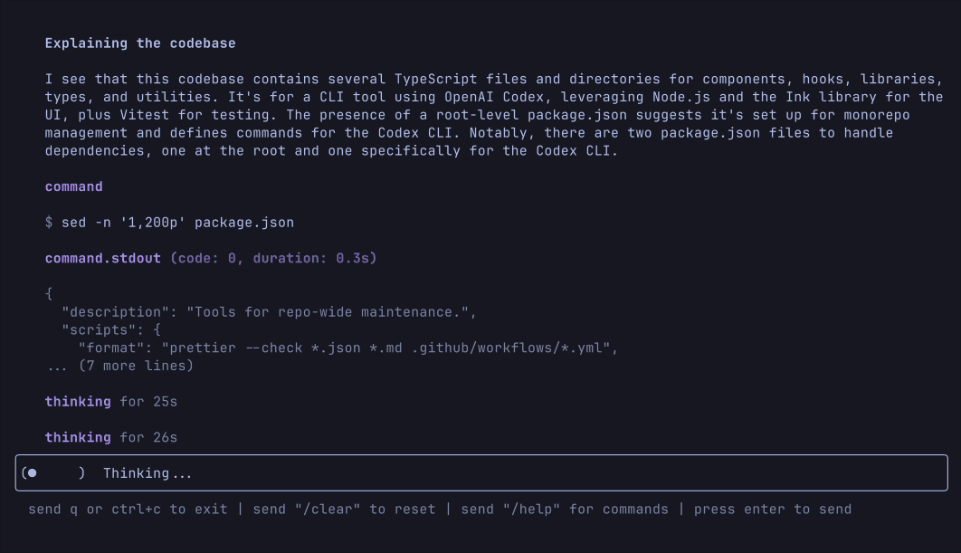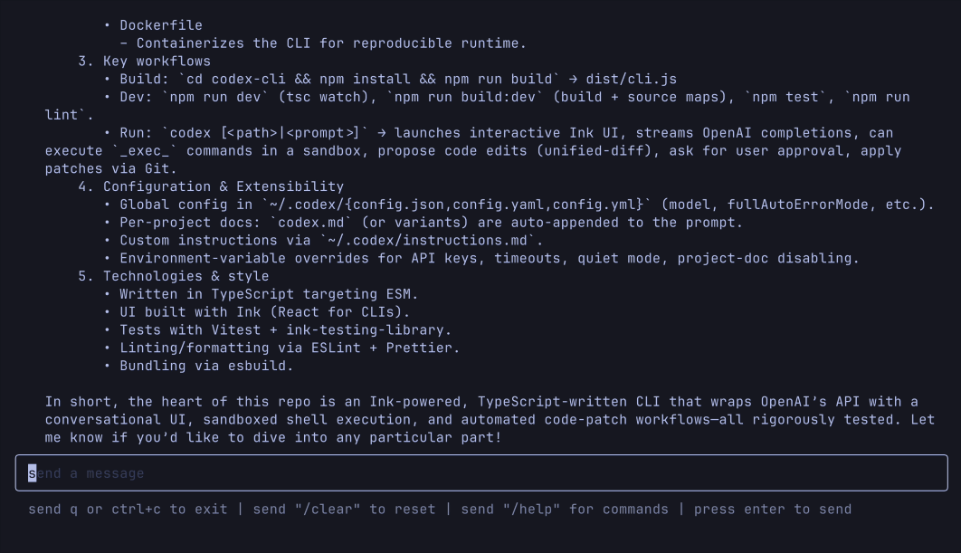
In addition to the new model, OpenAI also open sourced a new experimental tool: Codex CLI, a lightweight programming AI agent that can be run on the terminal.
Its role is to safely deploy code execution where needed.
It runs directly on the local computer and is designed to take full advantage of the powerful inference capabilities of models such as o3 and o4-mini, and will soon support API calls for more models such as GPT-4.1.
By passing a screenshot or low-fidelity sketch to the model, combined with access to local code, you can experience the power of multimodal inference from the command line.
At the same time, they also launched a $1 million grant program to support projects using Codex CLI and OpenAI models.
Once the GitHub project was released, Codex CLI has received 3.3k stars, which shows the high response rate.
Project address: https://github.com/openai/codex
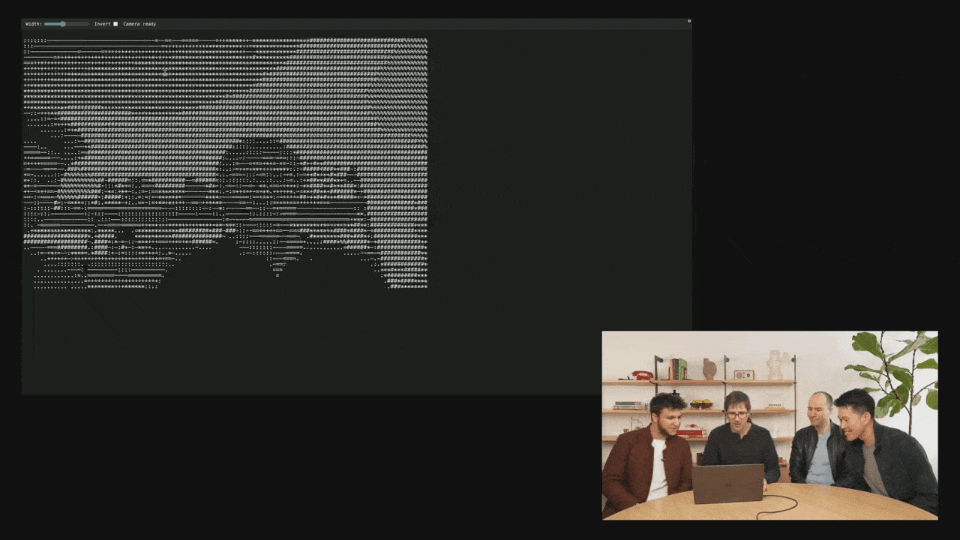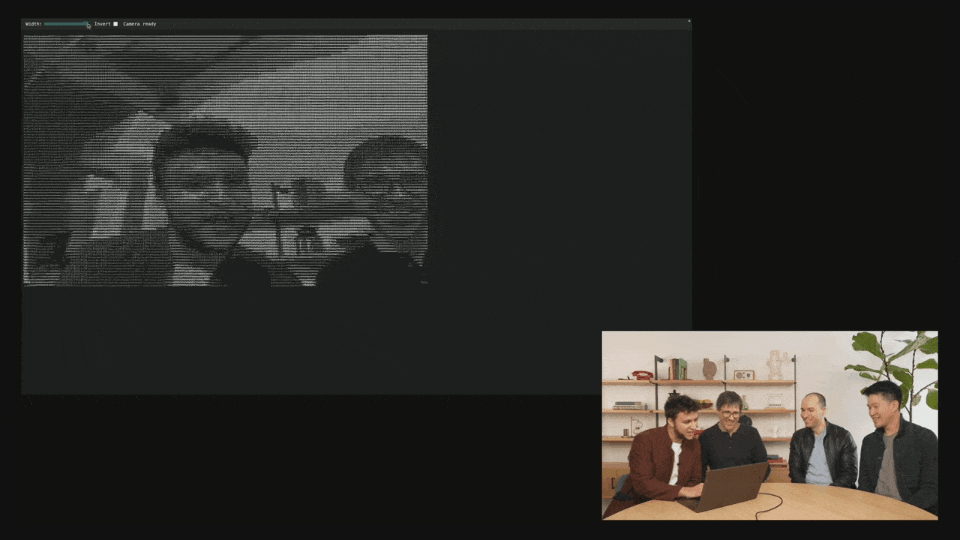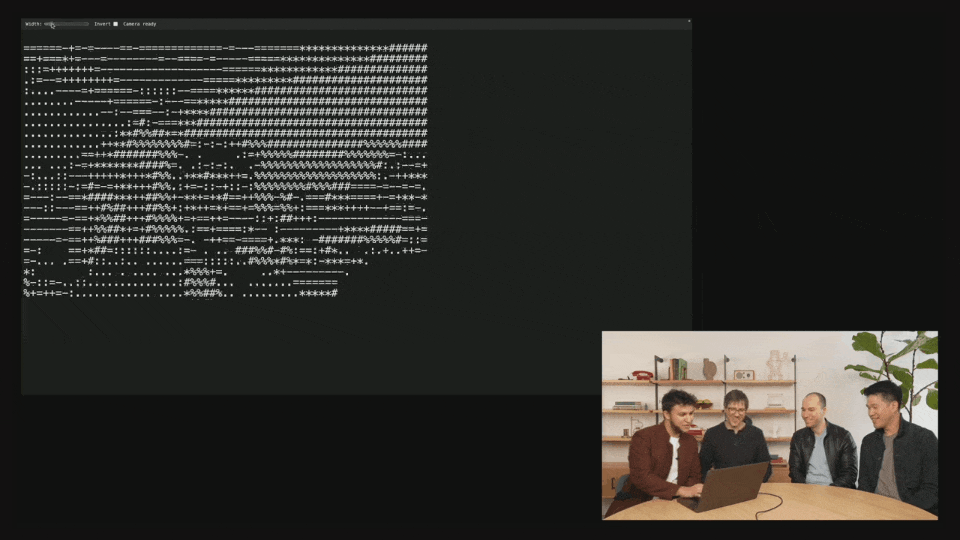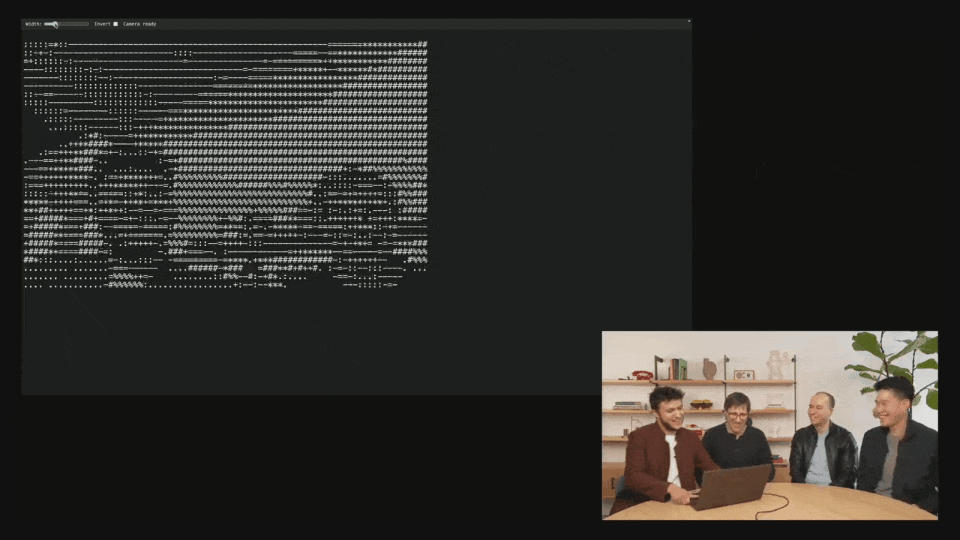
At the scene, the OpenAI demonstrator referred to online posts and used Codex and o4 Mini to make a cool image-to-ASCII generator.
Just take a screenshot, drag it into the terminal, and then give it to Codex.
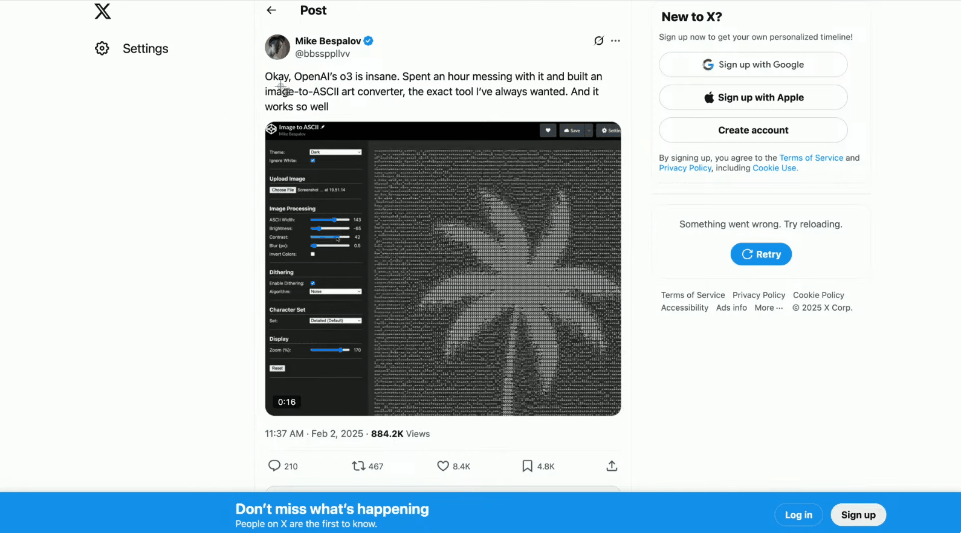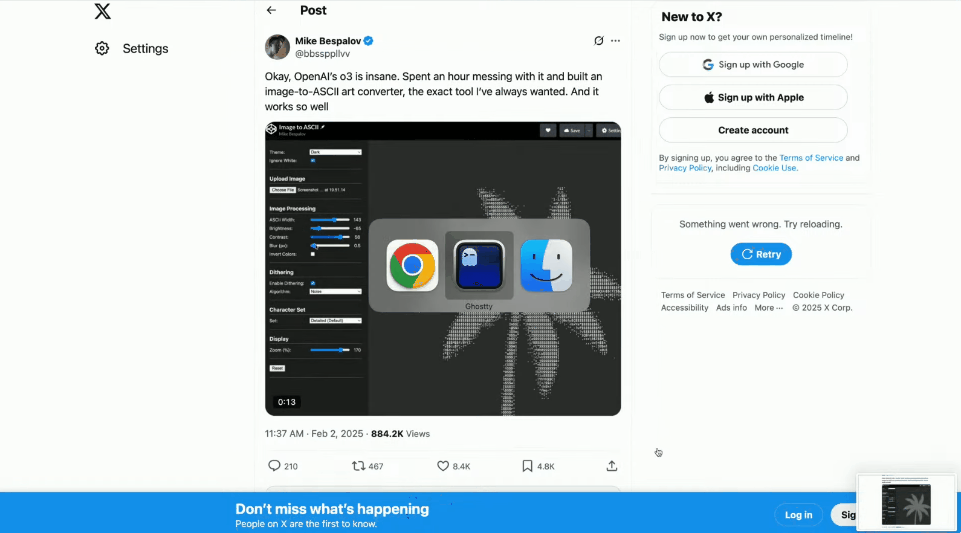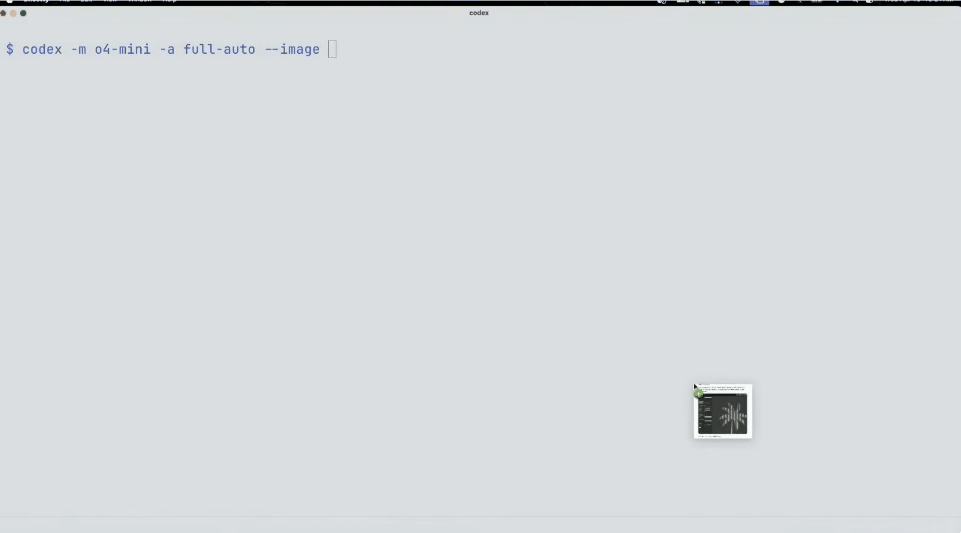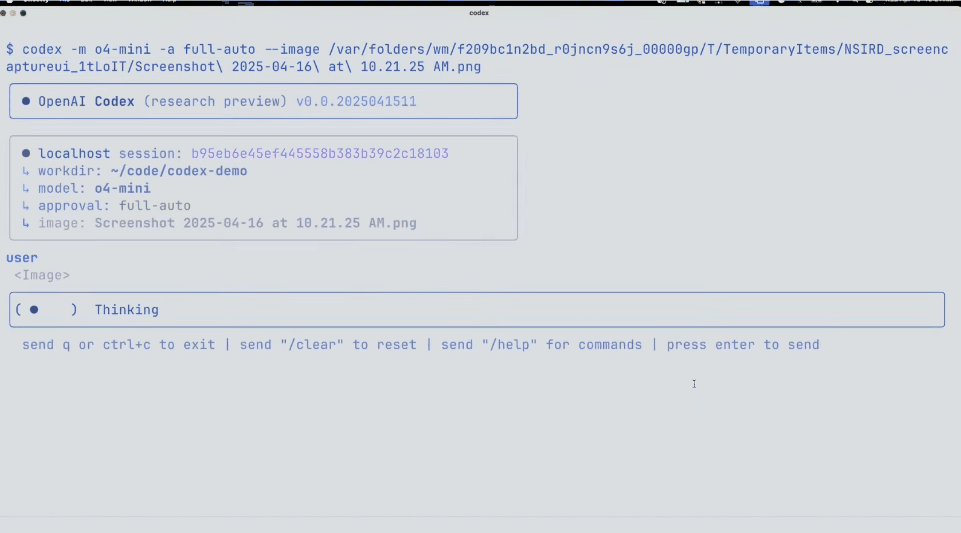
What's amazing is that you can actually see it think and run the tools directly.

Once completed, Codex created an ASCII HTML file and even generated a slider to control the resolution.
In other words, from now on, any files on your computer, as well as the code library you are working on, can be put into Codex!
At the site, the researchers also successfully added a webcam API.
Scaling reinforcement learning is still effective
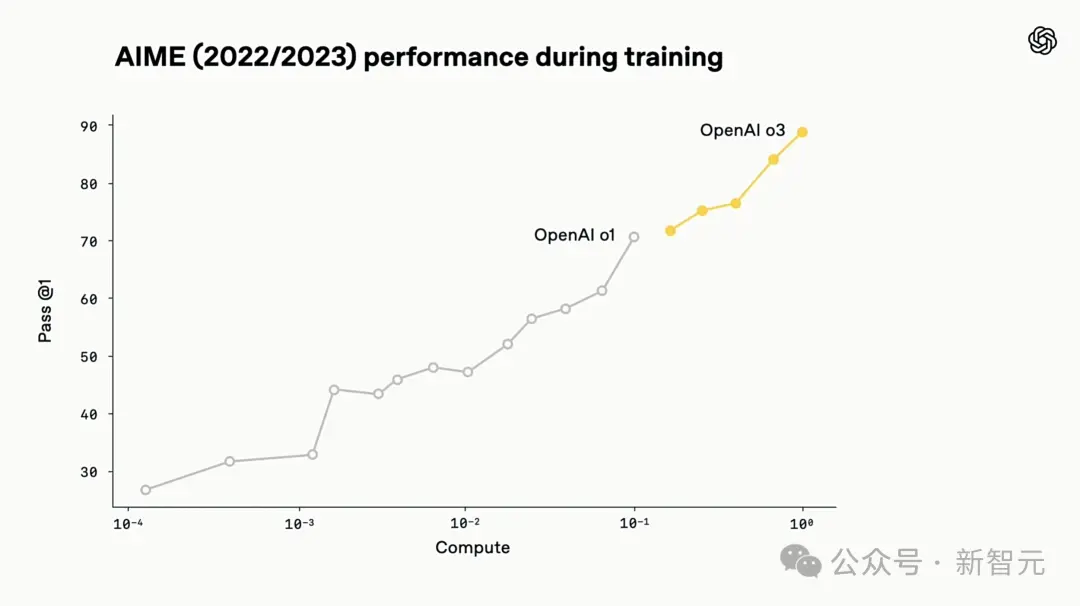
Throughout the development process of OpenAI o3, researchers observed a phenomenon: large-scale reinforcement learning also follows the rules that emerged during the pre-training of the GPT series - that is, "the more computing resources you invest, the better performance you can obtain."
They followed this Scaling path, this time focusing on reinforcement learning (RL), and increased the amount of training calculations and the amount of thinking in the inference stage (or inference calculation amount) by an order of magnitude. As a result, significant performance improvements were still observed.

Technical report: https://cdn.openai.com/pdf/2221c875-02dc-4789-800b-e7758f3722c1/o3-and-o4-mini-system-card.pdf
This verifies that as long as the model is given more time to "think", its performance will continue to improve.
Compared with the previous generation o1, o3 shows higher performance at the same latency and cost. Even more exciting is that when allowed to think for longer periods of time, its performance continues to climb.
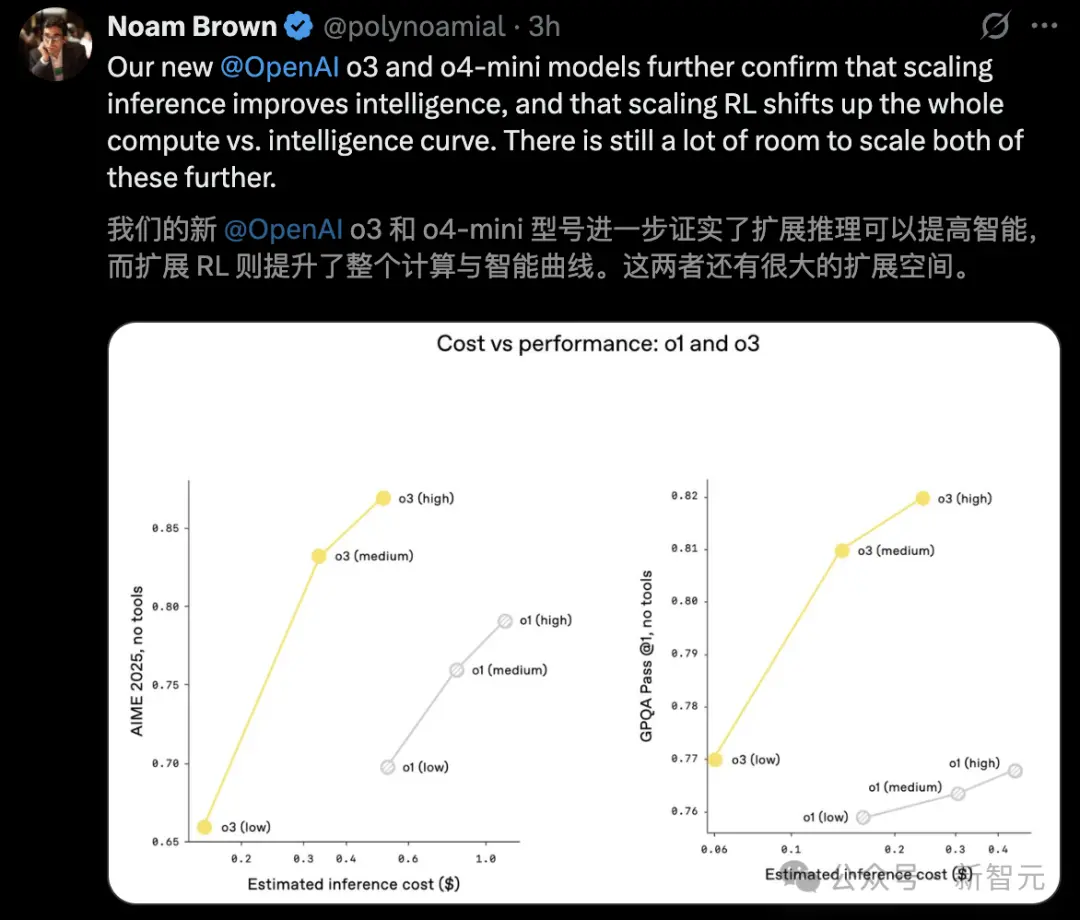
In addition, OpenAI allows o3 and o4-mini to master the wisdom of using tools through reinforcement learning training - not only learning "how to use", but also knowing "when to use".
Not only can they fully access ChatGPT's built-in tools, but they can also access user-defined tools through the function calling function in the API.
This capability makes the model more capable in open scenarios, especially in complex tasks that require visual reasoning and multi-step workflows.
Moreover, from many previous cases, we have gained a key insight into the ability to call model tools.
The big guys who had qualified for the closed beta in advance were shocked by o3.
Especially in the clinical and medical fields, its performance is phenomenal. Whether it is diagnostic analysis or treatment suggestions, it seems to be written by top experts.

Whether it is accelerating scientific discovery, optimizing clinical decision-making, or reasoning about cross-field innovation, o3 is becoming the leader of this change.
References:
https://openai.com/index/thinking-with-images/
https://openai.com/index/introducing-o3-and-o4-mini/