At last week's Cloud Next conference, Google announced that the Gemini 2.5 Flash model is coming soon and will bring significant improvements. Today, Google announced the Gemini 2.5 Flash preview in the Gemini API via Google AI Studio and Vertex AI. This new model is also available to Gemini users through the model selector and works with Canvas to easily optimize documents and code.

Following the previous generation Gemini 2.0 Flash, Gemini 2.5 Flash has significantly improved inference capabilities while reducing cost and latency. Google claims that this new model has excellent value for money. The specific prices are as follows:
$0.15 per 1 million input tokens
per 1 million outputsword elementCharge $0.60 (no reasoning required)
$3.50 per 1 million output tokens (including inference)
This is an early version of Flash 2.5, but it already shows huge performance improvements over the Flash 2.0 version.
If desired, you can turn off the think feature entirely and use this model as a drop-in replacement for Flash 2.0.
It's available in Gemini API, AI Studio, Vertex, and Gemini apps!
— Logan Kilpatrick (@OfficialLoganK)
Gemini 2.5 Flash is Google's first fully hybrid inference model, allowing developers to choose to turn inference on or off. This is said to help developers optimize responses based on target quality, cost and latency. Check out the benchmarks for this new model below.
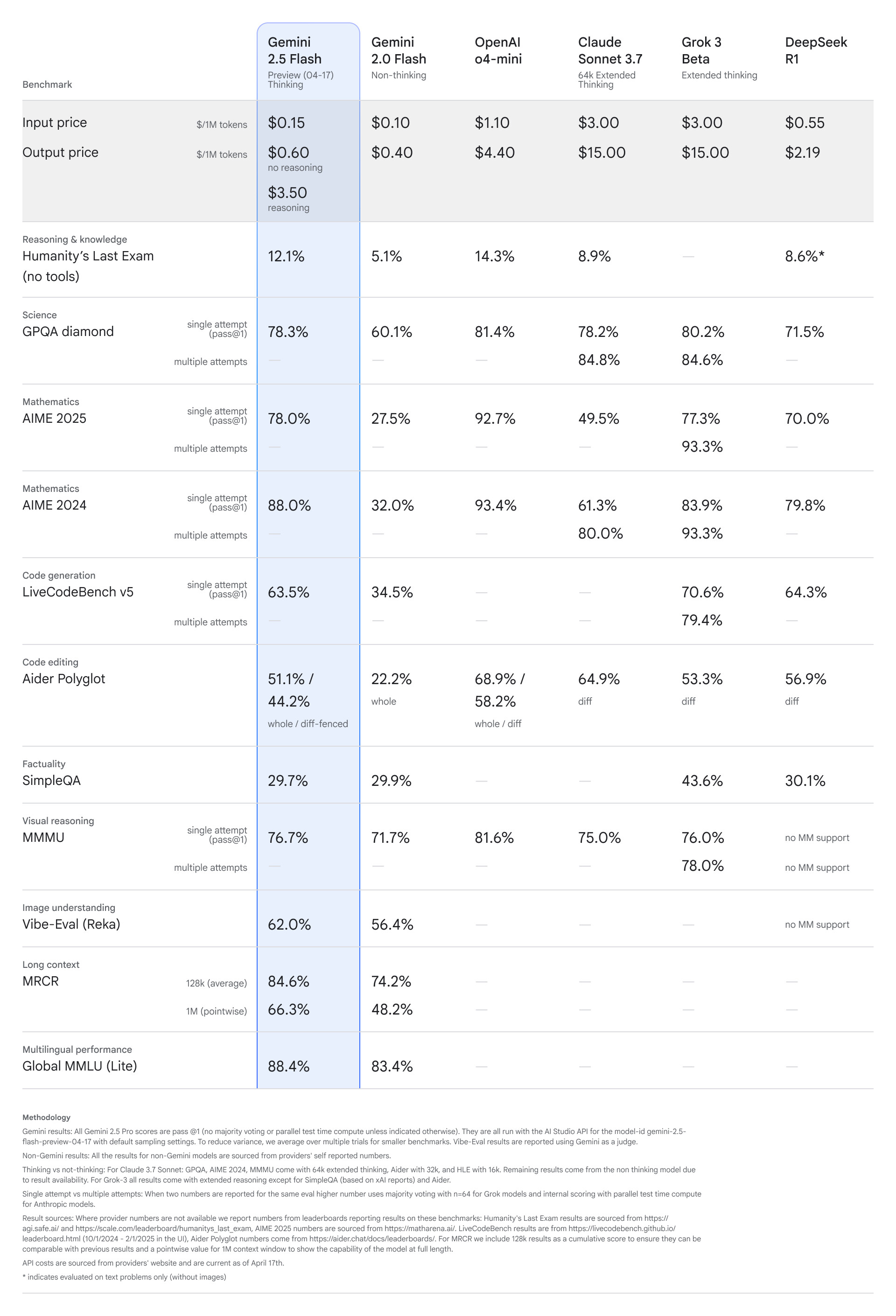
As the table above shows, despite its low cost, the Gemini 2.5 Flash still seems to hold its own against cutting-edge models from Anthropic and Grok. OpenAI's recently released o4-mini seems to perform better than the Gemini 2.5 Flash preview, but the price is much higher.