July 24 Bytedance today officially launched the end-to-end simultaneous interpretation model Seed LiveInterpret 2.0. This model focuses on two-way translation between Chinese and English, and its translation accuracy and response latency are close to the level of professional human simultaneous interpreters.
Seed LiveInterpret 2.0 is based on a full-duplex speech generation and understanding framework, which can process speech input in real time and output target language translation almost simultaneously.

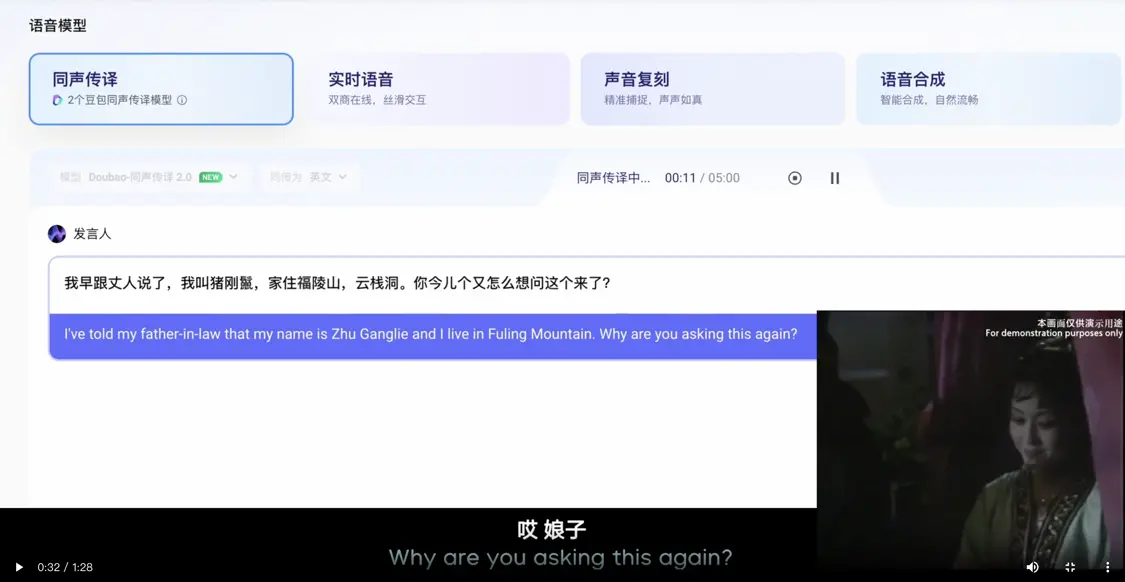
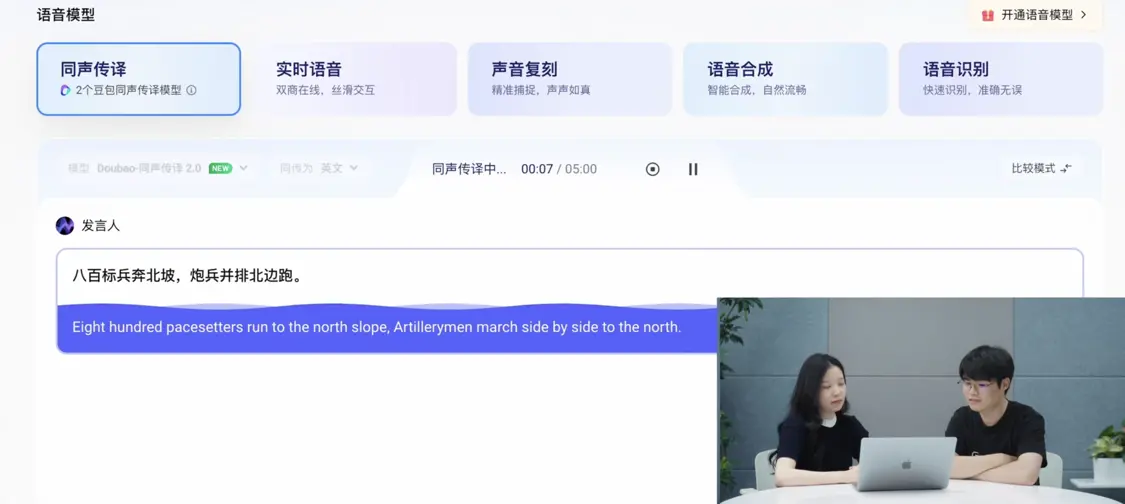
The official website shows the usage process of Seed LiveInterpret 2.0
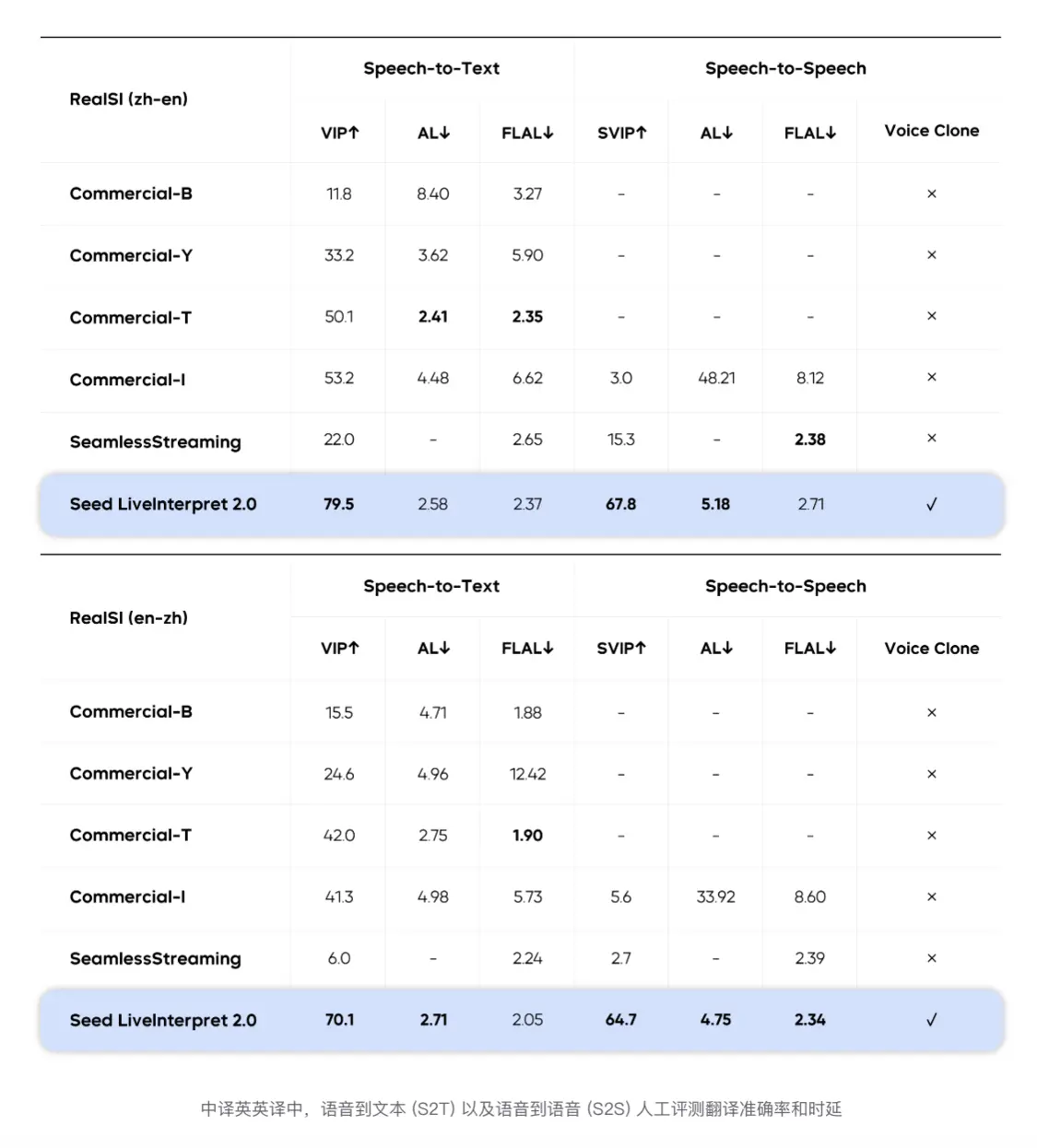
The model achieves an average speech-to-speech delay of 2-3 seconds, has the ability to imitate the timbre of different speakers in real time to preserve identity characteristics, and supports the understanding and translation of context, cultural background, and complex expressions including tongue twisters, poetry, and food culture.
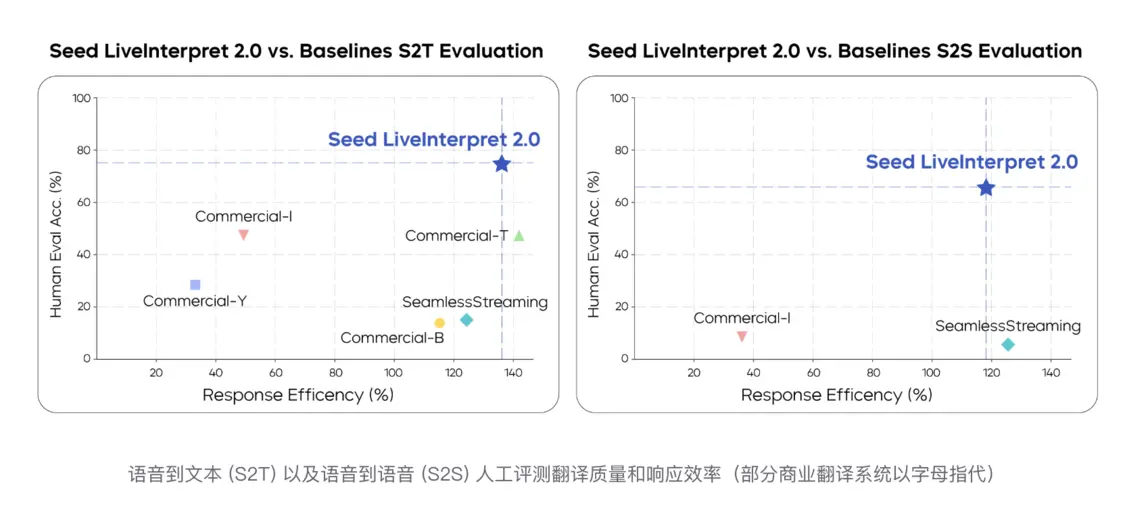
Model evaluation showed that in the speech-to-text simultaneous interpretation task, the Chinese-English translation quality score was 74.8 (out of 100), 58 percentage points ahead of the second-place system. In the more difficult speech-to-speech task (supported by only 3 companies in the industry), its overall quality score reached 66.3 points, which is also far higher than the benchmark system. At the same time, the model's initial word/initial sound output delay in speech-to-text and speech-to-speech scenarios is only 2.21 seconds and 2.53 seconds respectively.