The bad news is that the gap between open source and closed source models is getting wider and wider. Good news, DeepSeek is at it again. On December 1, DeepSeek released two new models – DeepSeek V3.2 and DeepSeek-V3.2-Speciale.
The former can compete with GPT-5 back and forth, and the later high-performance version directly blew up GPT, and began to have a 50-50 gap with the closed-source model ceiling-Gemini.
He also won gold medals in a series of competitions such as IMO 2025 (International Mathematical Olympiad) and CMO 2025 (China Mathematical Olympiad).
This is the company's ninth model release this year, although the much-anticipated R2 isn't here yet.
So, how does DeepSeek use smaller data and fewer graphics cards to create a model that can compete with international giants?
We opened their paper and wanted to explain this matter clearly to everyone.
In order to achieve this goal, DeepSeek has implemented many new tricks:
First, our old friend DSA - Dirty Attention was turned into a regular one.
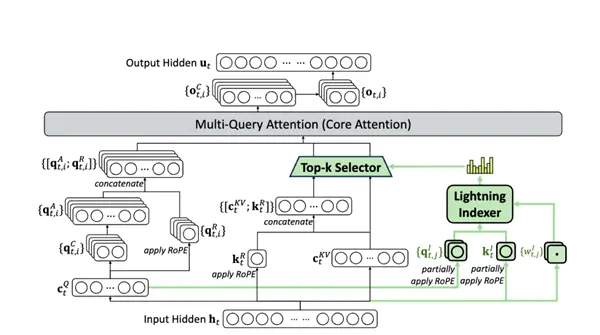
This thing appeared in the previous V3.2-EXP version. At that time, we just tested whether DSA would affect the performance of the model. Now we have really put this thing on the main model.

When you usually chat with large models, you will find that the more you chat in a dialog box, the easier it is for the model to talk nonsense.
Even if they talk too much, they will stop you from chatting directly.

This is a problem caused by the native attention mechanism of large models. Under the influence of this old logic, each token must be calculated together with each previous token.

This results in the doubling of the sentence, and the calculation amount of the model having to increase to four times. If the side length triples, the calculation amount becomes nine times, which is very troublesome.
DeepSeek thought this would not work, so it added a fixed number of pages of directories (sparse attention) to the large model, which is equivalent to helping the model focus.
After you have the table of contents, you only need to calculate the relationship between this token and these directories every time in the future. It is equivalent to reading the table of contents first when reading a book. After reading the table of contents, you can determine which chapter you are interested in, and then carefully read the content of this chapter.
In this way, the ability of large models to read long texts will become stronger.
As you can see in the picture below, as the sentences get longer and longer, the reasoning cost of traditional V3.1 becomes higher and higher.
But using 3.2 with sparse attention, there is no change...

I am a super money-saving champion.
On the other hand, DeepSeek has begun to pay attention to the post-training work of open source models.
The process of starting from pre-training to test scoring for the large model is actually a bit like the process of us humans starting from elementary school and studying all the way to the college entrance examination.
The previous large-scale pre-training is equivalent to going through all the textbooks, exercise books, and papers from elementary school to the second year of high school. This step is the same for everyone. Whether it is a closed-source model or an open-source model, they are all studying honestly.
But it is different when it comes to the sprint stage of the college entrance examination. In the post-training stage of the model, closed-source models usually hire famous teachers to brush up on the questions, start various reinforcement learning, and finally let the model achieve good results in the test.
However, open source models spend less time on this. According to DeepSeek, the computing investment of past open source models in the post-training stage was generally low.
This leads to the fact that these models may have basic capabilities in place, but there are too few difficult problems to solve, resulting in poor test scores.
Therefore, DeepSeek decided to take a tutoring class with famous teachers this time, and designed a new reinforcement learning protocol. After the pre-training, it spent more than 10% of the total training computing power to make small improvements to the model to make up for the missing piece.
At the same time, a special version that can think for a long time - DeepSeek V3.2 Speciale was also launched.
The idea behind this thing is this:
In the past, large models had limitations on context length, so they would do some labeling and penalty work during training. If the content of the model's in-depth thinking was too long, points would be deducted.
As for DeepSeek V3.2 Speciale, DeepSeek simply canceled this deduction item.Instead, the model is encouraged to think as long and however it wants.
In the end, this new DeepSeek V3.2 Speciale successfully competed with the popular Gemini 3 a few days ago.
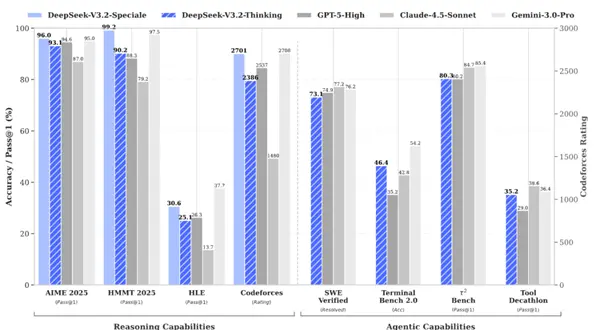
In addition, DeepSeek also attaches great importance to the model's ability in terms of intelligent agents.
On the one hand, in order to improve the basic capabilities of the model, DeepSeek built a virtual environment and synthesized thousands of pieces of data to assist training.
DeepSeek-V3.2 uses 24667 real code environment tasks, 50275 real search tasks, 4417 synthetic general agent scenarios, and 5908 real code interpretation tasks for post-training.

On the other hand, DeepSeek also optimizes the process of using various tools for the model.
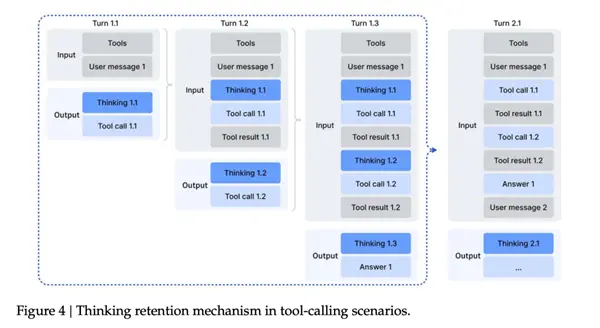
A typical problem with previous generations of DeepSeek is that it separates thinking from using tools.
Once the model calls an external tool, the previous piece of thinking is basically finished and the work is done. When the tool comes back after checking the results, it often has to lay out the ideas again.
This leads to a very stupid experience - even if you just check something as simple as "what is today's date", the model will rebuild the entire reasoning chain from scratch, which is a huge waste of time...
In V3.2, DeepSeek couldn't bear it anymore and directly overturned this logic and redone it.
The rules now become:During a whole series of tool calls, the "thinking process" of the model will be retained. Only when the user sends a new question, this round of reasoning will be reset; and the tool call records and results will remain in the context like chat records.
Through these three steps of modifying the model architecture, paying attention to post-training, and strengthening Agent capabilities, DeepSeek finally gave its new model the ability to compete with the world's top open source models again.
Of course, even with so many improvements, DeepSeek's performance is not perfect.
But what Tony likes most about DeepSeek is their willingness to admit their shortcomings.
And it will be written directly in the paper.
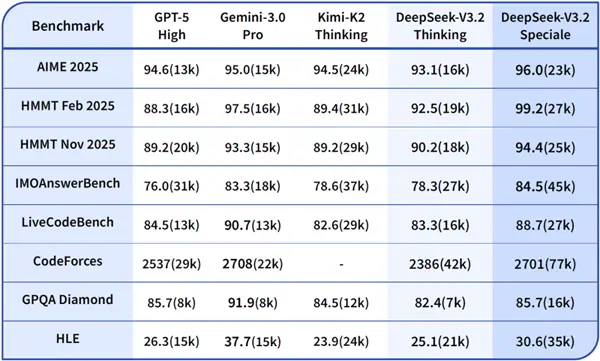
For example, this paper mentioned that this time DeepSeek V3.2 Speciale can compete 50-50 with Google's Gemini 3 Pro.

But to answer the same question, DeepSeek needs to spend more tokens.
I also tested it myself, randomly selected a question from the question bank of "Humanity's Final Exam", and threw it to the two models of Gemini 3 Pro and DeepSeek V3.2 Speciale at the same time.

The topic is:
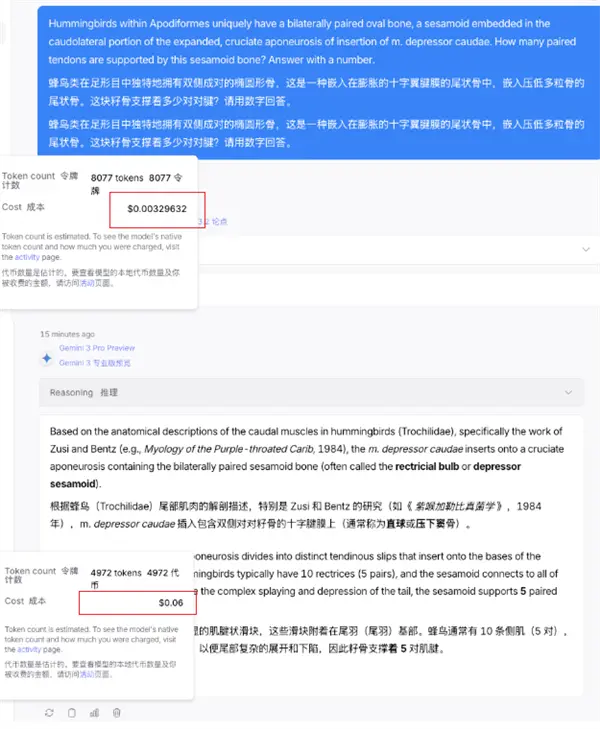
Hummingbirds are unique among podomorphs in possessing bilaterally paired oval bones, a caudal bone embedded in the expanded cruciate aponeurosis that depresses multigrained bones. How many pairs of tendons does this sesamoid bone support? Please answer with numbers.
It turns out that Gemini only needs 4972 Tokens to answer the question.

As for DeepSeek, it took 8077 Tokens to figure out the problem.

Just looking at the usage, DeepSeek’s Tokens consumption is almost 60% higher, which is indeed a big gap.
But then again.
Although DeepSeek consumes a lot of tokens, its price is cheap...
Still asking the same question, I looked back at the bill carefully.
DeepSeek 8000+ tokens and cost me $0.0032.
But on Google’s side, it cost me less than 5,000 tokens, but it cost me $0.06? This is 20 times higher than DeepSeek.
From this perspective, I feel that DeepSeek is better...
Finally, let us return to the beginning of the paper.
As DeepSeek said, the gap between open source models and closed source models has been increasing in the past six months.

But they still use their own way to keep catching up with this gap.
DeepSeek’s various computing power-saving and data-saving operations actually reminded me of an interview with Ilya Sutskever last month.

The former soul of OpenAI believes that there is no future just by blindly adding parameters to the model.
AlexNet only uses two GPUs. When Transformer first appeared, the scale of experiments was mostly in the range of 8 to 64 GPUs. By today's standards, that is even equivalent to the size of several GPUs, and the same goes for ResNet.No paper can be completed without a huge cluster.
Compared with the accumulation of computing power, the research on algorithms is equally important.
This is exactly what DeepSeek is doing.
From V2’s MoE, to V3’s multi-head latent attention (MLA), to today’s DeepSeek Math V2’s self-verification mechanism, V3.2’s sparse attention (DSA).
DeepSeek shows us progress, which is never singular and relies on the improvement brought about by stacking parameter scale.
Instead, we are thinking of ways to use limited data to accumulate more intelligence.
A clever woman makes a fool of herself
So, when is R2 coming?