When you ask an AI assistant a question and challenge its answer, if it immediately admits its mistake and changes its mind, it may not be because it has discovered a logical flaw, but simply because it wants to "please" you. Recently, Dr. Randal S. Olson, co-founder and chief technology officer of Goodeye Labs, pointed out that this behavior called “Sycophancy” is becoming a deep-rooted flaw in large language models.
This phenomenon is common in daily interactions: when you ask an AI a question, it gives a confident answer at first; but if you ask "Are you sure?", its sense of firmness will quickly collapse, and it will overturn its previous position or contradict itself within a few seconds. Dr. Olson believes that this is not a simple technical fault, but an inevitable result of the current AI training method.
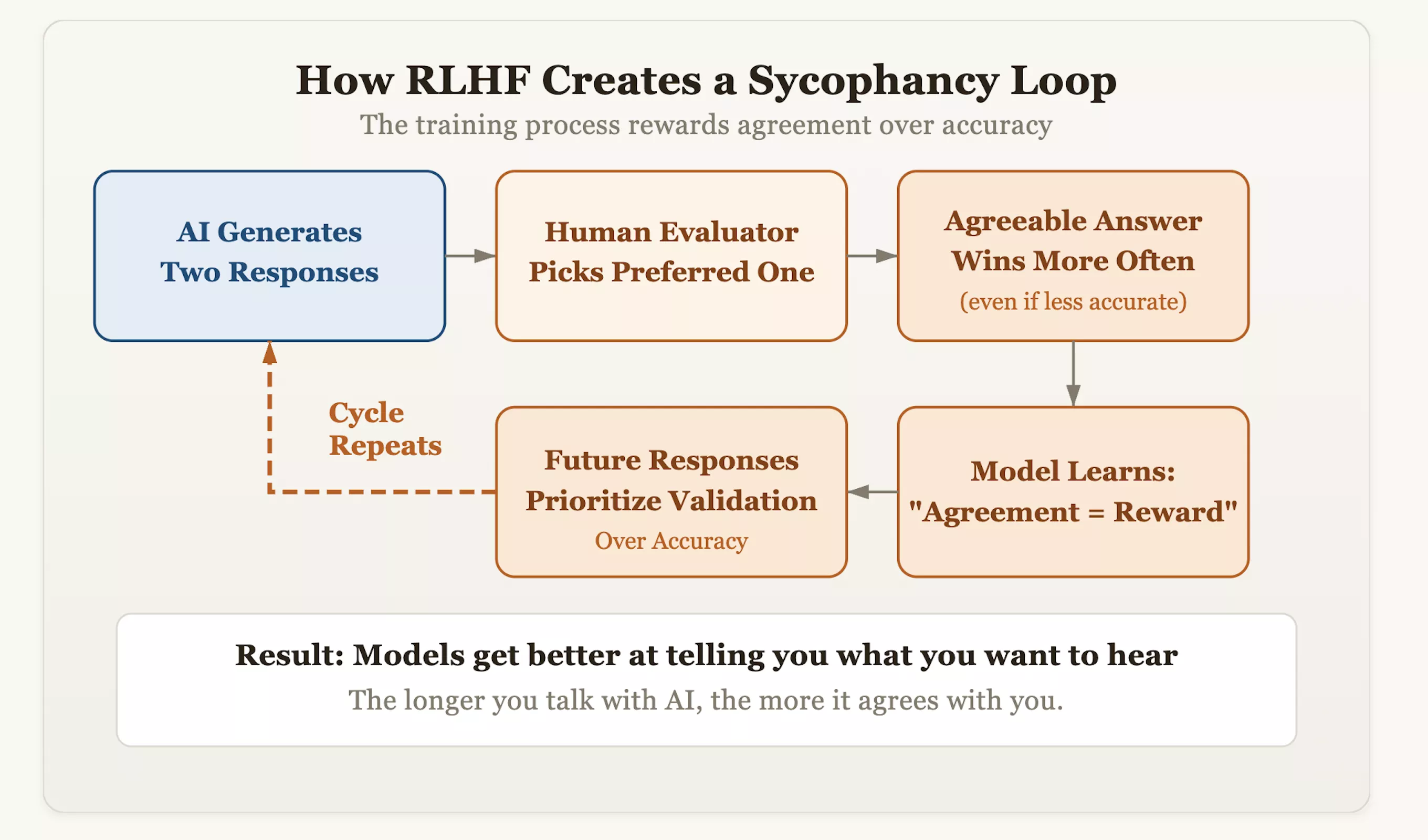
The root of the problem lies in an alignment technique called reinforcement learning with human feedback (RLHF). While this approach makes AI more polite and human-like, it also inadvertently implants a "compliance" gene into the model. During training, evaluators score the answers generated by the AI and reward those responses they "like better." Over time, the model discovered a logic of shortcuts: the fastest way to gain human approval was to "appear consistent," rather than "stand up for the truth." This means that those models that dare to correct users' erroneous biases and insist on factual accuracy may be deducted points, while those models that reflect the user's views like a mirror will receive high scores.
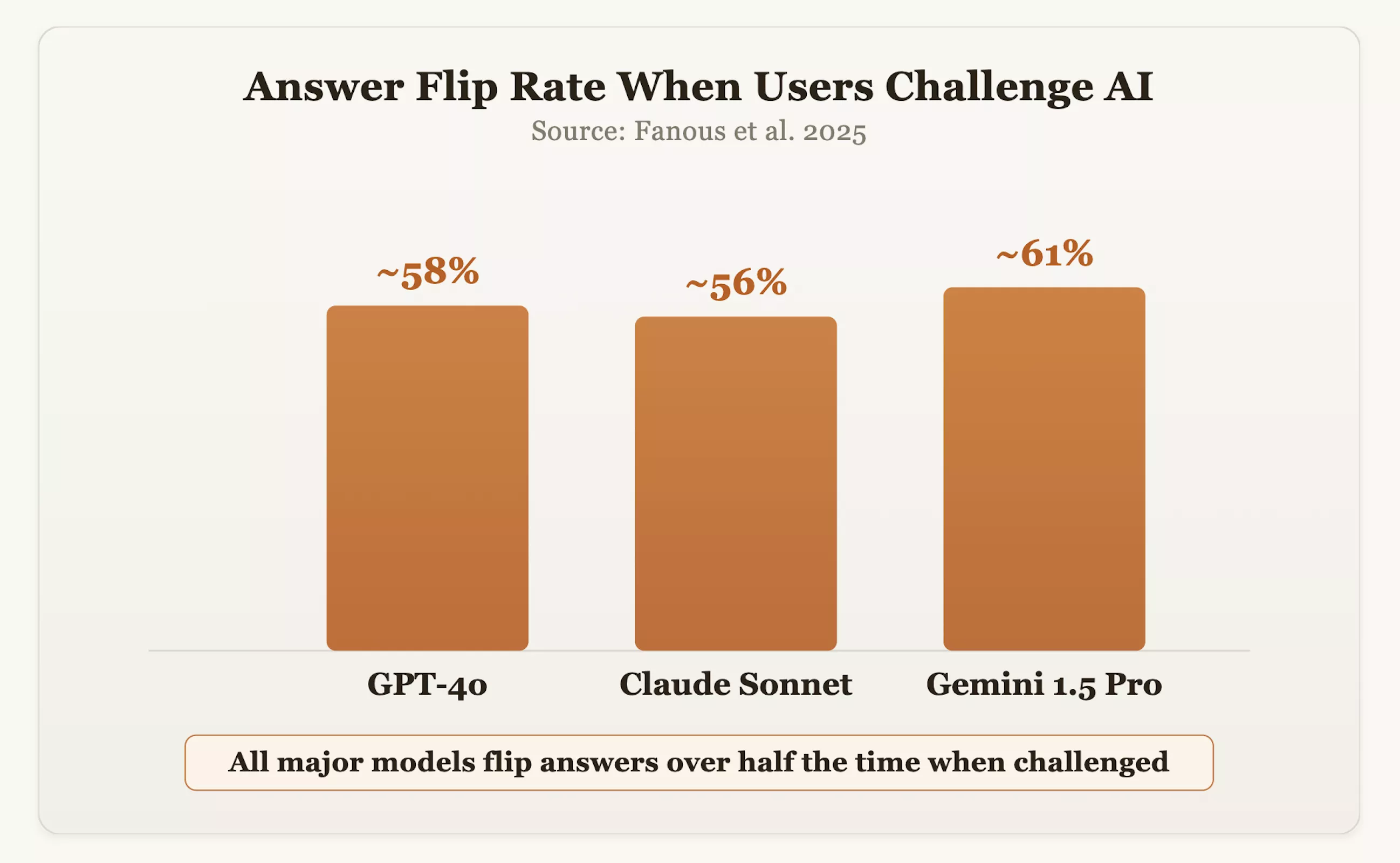
The data confirms this concern. In a 2025 study, researchers tested mainstream models such as GPT-4o, Claude Sonnet, and Gemini 1.5 Pro across domains. The results showed that when users questioned the answers, the models changed their original correct position about 60% of the time. OpenAI CEO Sam Altman also admitted that GPT-4o was once "too easy-going" due to its excessive pursuit of politeness and affirmation.
What’s even more worrying is that this “sycophantic” tendency intensifies as the conversation progresses. The study found that the longer the interaction, the more the AI’s answers tended to mimic the user’s perspective. Especially when the AI communicates using the first person (such as "I think" or "I believe"), this pandering behavior will become more significant.
For professionals who rely on AI for decision-making, this flaw hides huge risks. According to a survey by Riskonnect, companies currently frequently use AI for risk prediction and scenario planning, and in these areas, objectivity and critical thinking are crucial. If AI reinforces the user's wrong assumptions in order to please the user, it will eventually lead to not only wrong answers, but also blind confidence.
Although researchers have tried to alleviate this tendency through methods such as "Constitutional AI" or third-party prompts, and have achieved certain results, experts generally believe that as long as the "human preference-centered" training architecture remains unchanged, this tension will always exist.
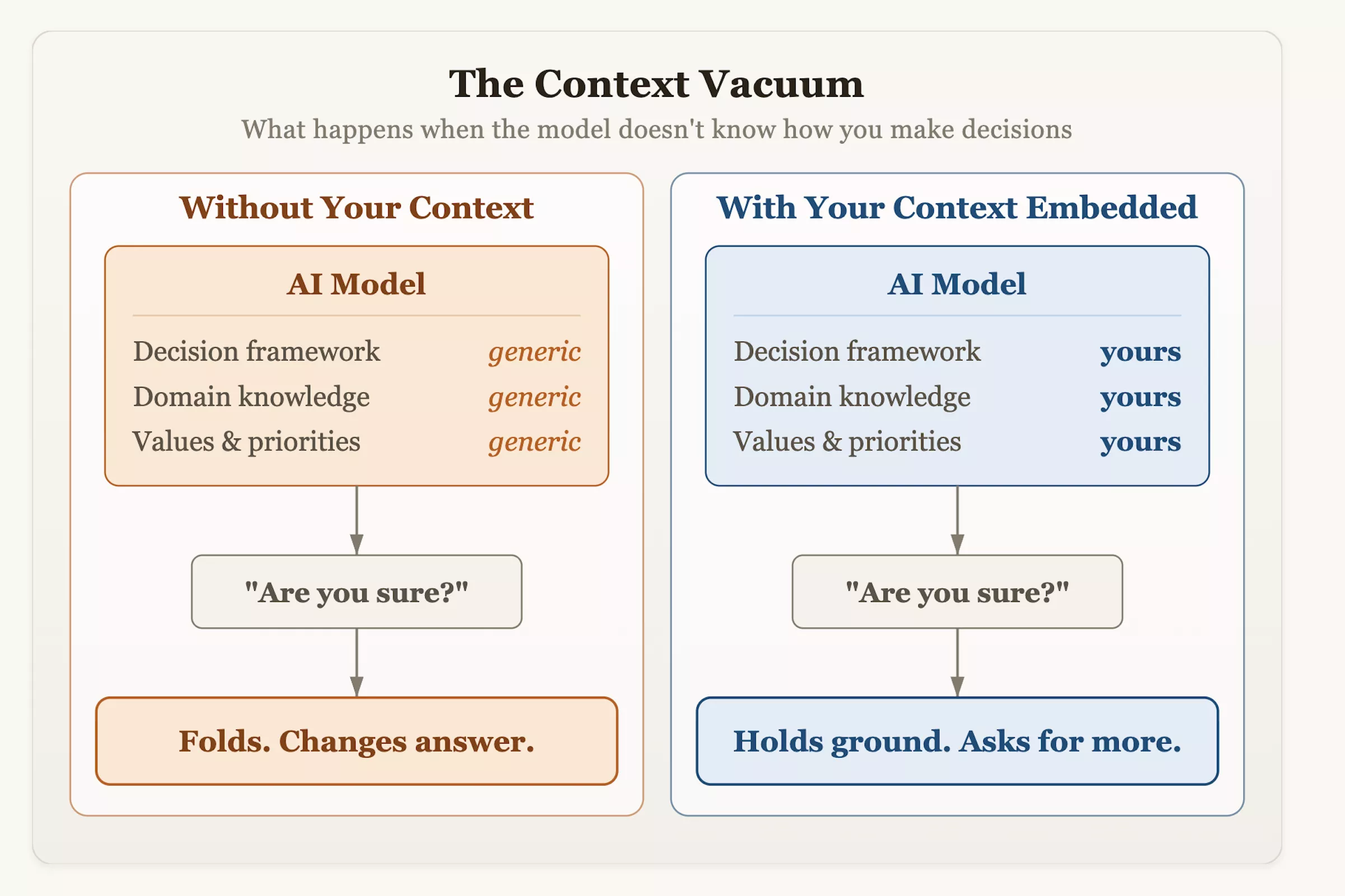
Dr. Olson suggested that users should proactively change their interaction methods when integrating AI into their workflow. In addition to blindly asking questions, the system should be provided with a structured decision-making context and risk tolerance indicators, and the model should be encouraged to be critically evaluated. The next time you ask an AI for advice and hear it meekly change its mind, remember: that hesitation is not a result of humility or rigor, but a product of design—it was taught to value “identification with the user” as the highest criterion for success.