This time, human software engineering was done "in reverse"! Just now, OpenAI's official blog exposed one of their internal experiments: an initial team of three engineers used the Codex agent to create a "million-line code product" from scratch in five months. During the entire process, humans do not write manual code, but focus on "thinking clearly about what they want and establishing rules", and leave everything else to AI.
Each person can push an average of 3.5 PRs (Pull Requests, code merge requests) every day, and the entire PR execution process (implementation, testing, documentation, CI configuration) is handled by agents.
OpenAI gave this workflow a very vivid name: "Harness Engineering".

https://openai.com/index/harness-engineering/
In the experiment, programmers are no longer the "coders" who stay up late writing bugs and then staying up late fixing bugs, but the original "executors" become "drivers".
This is not only a "productivity revolution" with a 10-fold increase in efficiency, but a subversion of the definition of "software engineering" and directly declares the end of mankind's "manual coding era."
Change
Start with an empty git repository
This experiment started with the first submission of AI.
In late August 2025, when the first commit fell into the empty warehouse, it was no longer written by humans - there was no existing human code that could serve as an "anchor".
Even more magical: Even the first version of the instruction manual AGENTS.md used to guide AI how to work was written by AI itself.
From day one, this warehouse has been shaped by agents.Humans are not allowed to write code, which has become an insurmountable iron rule for this project.
This is not for laziness, but a kind of "deliberate practice" that is almost masochistic. Only by cutting off the escape route for humans to "get started" can the team be forced to solve the ultimate problem of building code without anyone at all.
As a result, this small team of 3 people (later expanded to 7 people) suddenly seemed to be a shepherd holding a whip, driving a group of tireless Codex agents to run wildly on the code grassland.
The results are stunning:5 months, 1 million lines of code.
Redefining the role of the engineer
Early progress on the experiment has been slower than OpenAI's researchers expected.
It's not that Codex doesn't work, it's that the environment is not clearly defined enough: the agent lacks the tools, abstractions, and internal structures needed to achieve high-level goals.
As a result, the main job of the OpenAI engineering team became one thing:Give the agent the ability to complete valuable work.
They break large goals into smaller building blocks (design, code, review, test, etc.), prompt the agent to put these blocks together, and then use them to unlock more complex tasks.
When things fail, the answer is almost never "try again." The only way to move forward here is to let Codex do the work. Human engineers usually take a step back and ask themselves:
What ability is missing? How to make it both visible to the agent and enforceable?
Throughout the process, humans interact with the system almost entirely through prompt words: the engineer describes the task, runs the agent, and lets it initiate a PR.
To advance the PR, researchers will have Codex self-review the changes locally, request additional local and cloud agent reviews, respond to human or agent feedback, and then iterate in a loop until all agent reviewers are satisfied.
Over time, almost all review work was moved to "agent versus agent".
Improve application readability
As code throughput increased, OpenAI found:The bottleneck of AI coding becomes the ability of manual quality inspection (QA).
Human time and attention thus become real constraints.
In order to break through this bottleneck, OpenAI's approach is to enable Codex to directly read the application's user interface, logs, application indicators, etc.
They integrated the Chrome DevTools protocol into the agent runtime and developed skills for handling DOM snapshots, screenshots, and navigation.
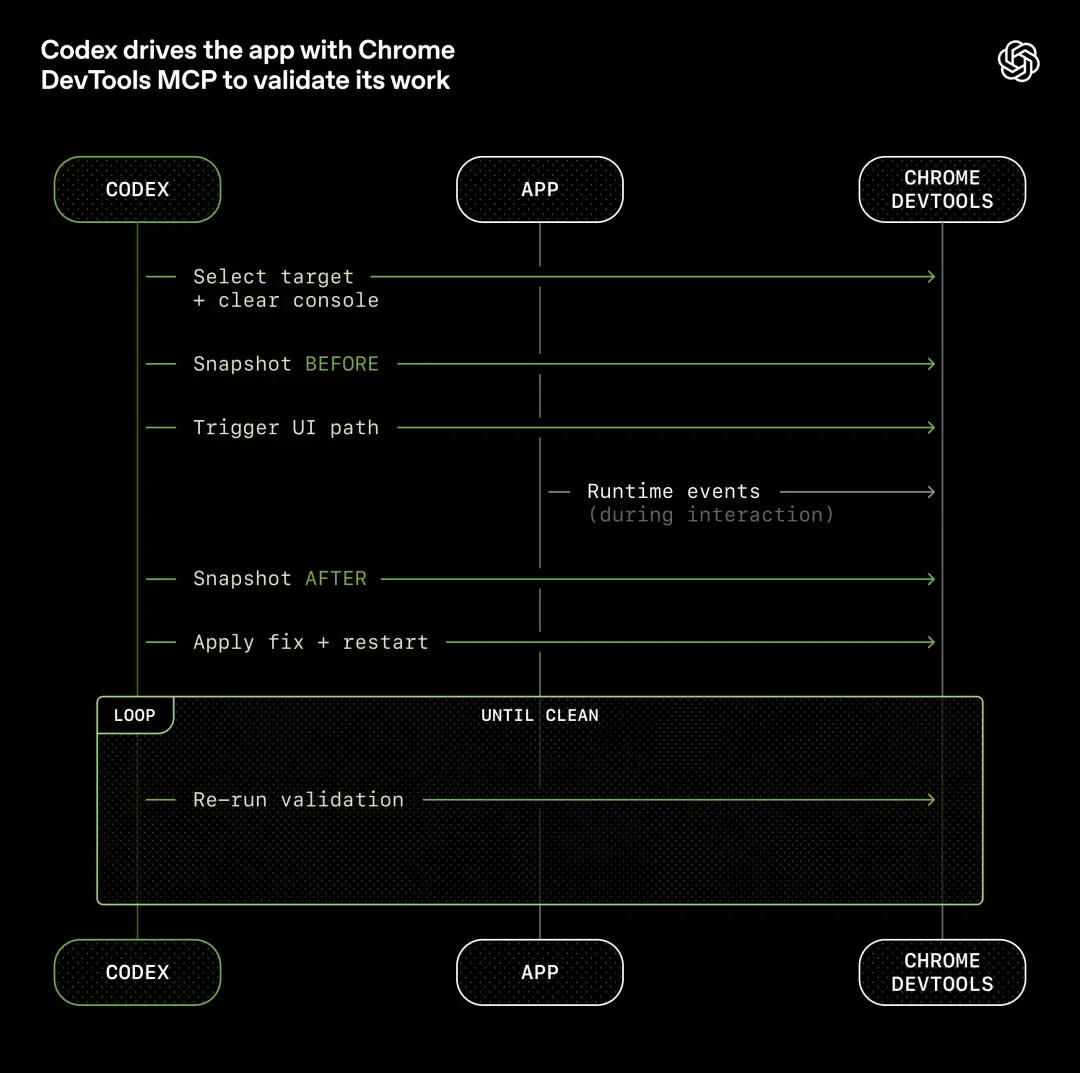
As a result, Codex can reproduce bugs, verify repairs, and reason about UI behavior on its own.
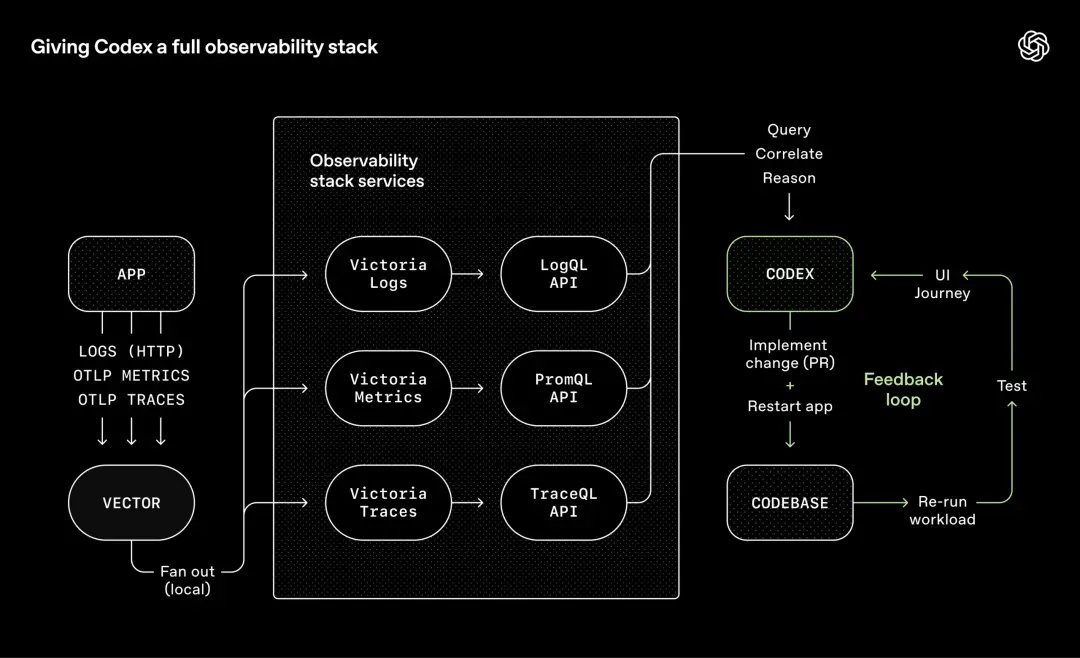
OpenAI takes the same approach with observability tools.
Logs, metrics, and traces are exposed to Codex through a local observability stack and are isolated, temporary environments for each worktree (workspace).
After the task is completed, the environment will be destroyed.
Agents can use LogQ to check logs and PromQL to check indicators.
As a result, prompts such as "Make sure the service startup is completed within 800ms" or "No span among the four key user paths exceeds two seconds" becomes truly executable.
After doing this, OpenAI researchers often seeCodex works continuously for more than six hours at a time, usually while humans are sleeping.
Give Codex a map
Rather than a 1,000-page manual
Context management is one of the biggest challenges when letting agents handle large and complex tasks.
A simple lesson OpenAI researchers learned early on is this:
Give Codex a map, not a 1,000-page manual.
At the beginning, the team tried to write a very large AGENTS.md file and stuff all the rules, logic, and precautions into it. It turned out to be a disaster.
Because AI’s attention is also a scarce resource.
Give it a 1,000-page instruction manual and it will get lost in details, miss key constraints, or get the goals wrong.
Moreover, maintaining such a single large document is a nightmare and will soon become a "graveyard of old rules."
As a result, the team quickly adjusted their strategy and turned AGENTS.md into a "treasure map."
This file is only about 100 lines long and contains no specific knowledge, just a table of contents, like a navigation map that points to deeper sources of truth deep within the warehouse.
Design documents are cataloged and indexed, including validation status and a set of core beliefs that define "agent-first" operating principles.
The real knowledge base is in the structured docs/ directory and is the system's single source of truth.
This is "progressive disclosure": the agent starts with a small and stable entrance and is taught where to look next, rather than being overwhelmed with information from the beginning.
OpenAI researchers also have tools to enforce this.
Verify whether the knowledge base is up-to-date, cross-linked, and has a correct structure through specialized lint and CI tasks.
Architecture documents give a top-level view of domain partitioning and package layering. Quality documentation scores each product area and architecture layer and continuously tracks gaps.
In order to ensure that the AI does not read outdated information, the team even specially arranged a "document gardener" agent.
It has only one job: scan documents regularly, find out-of-date descriptions that are inconsistent with code implementation, and then automatically initiate a fix PR.
Let the intelligent agent “understand”
Since the warehouse is completely generated by the agent, one of the goals of OpenAI researchers is to allow the agent to understand the complete business domain only by relying on the warehouse itself.
From an agent's perspective, any knowledge that it cannot access in the runtime context does not exist.
For example, knowledge placed in Google Docs, chat records, and human brains are all invisible to the system.
All it can see are versioned artifacts in the warehouse, such as code, Markdown, schema, and executable plans.
If agents cannot find this contextual knowledge, they will be as clueless as their new colleagues on the job and have no idea what is actually going on in the business.
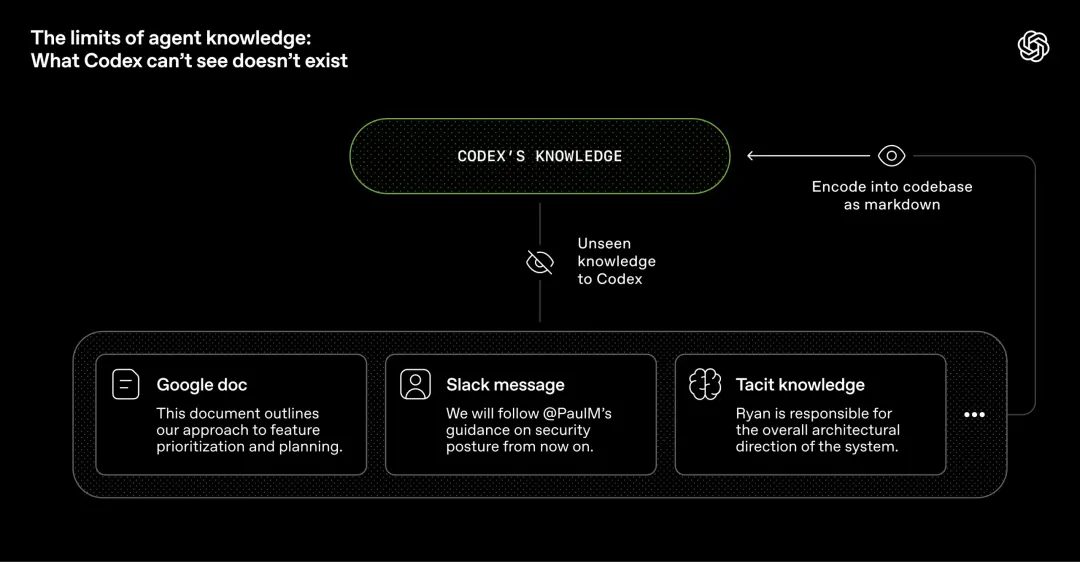
Therefore, more and more context has to be pushed back to the warehouse.
Of course, giving Codex more context does not mean giving it more scattered instructions, but organizing and structuring the information so that it can be reasoned.
Automated fence
Let programmers become the "shepherds" of the code world
Documentation alone is not enough to make a fully agent-generated code base consistent.
After all, AI is a probabilistic model. It can hallucinate, be lazy, and write code that "seems to run but is actually a mess."
How to solve it?
Agents work best in environments with clear boundaries and predictable structures.
By enforcing "invariants" rather than micromanaging implementation details, OpenAI allows agents to move forward at high speed without breaking the foundation.
This is like putting on the reins and saddle for an AI horse like Codex that travels thousands of miles every day.
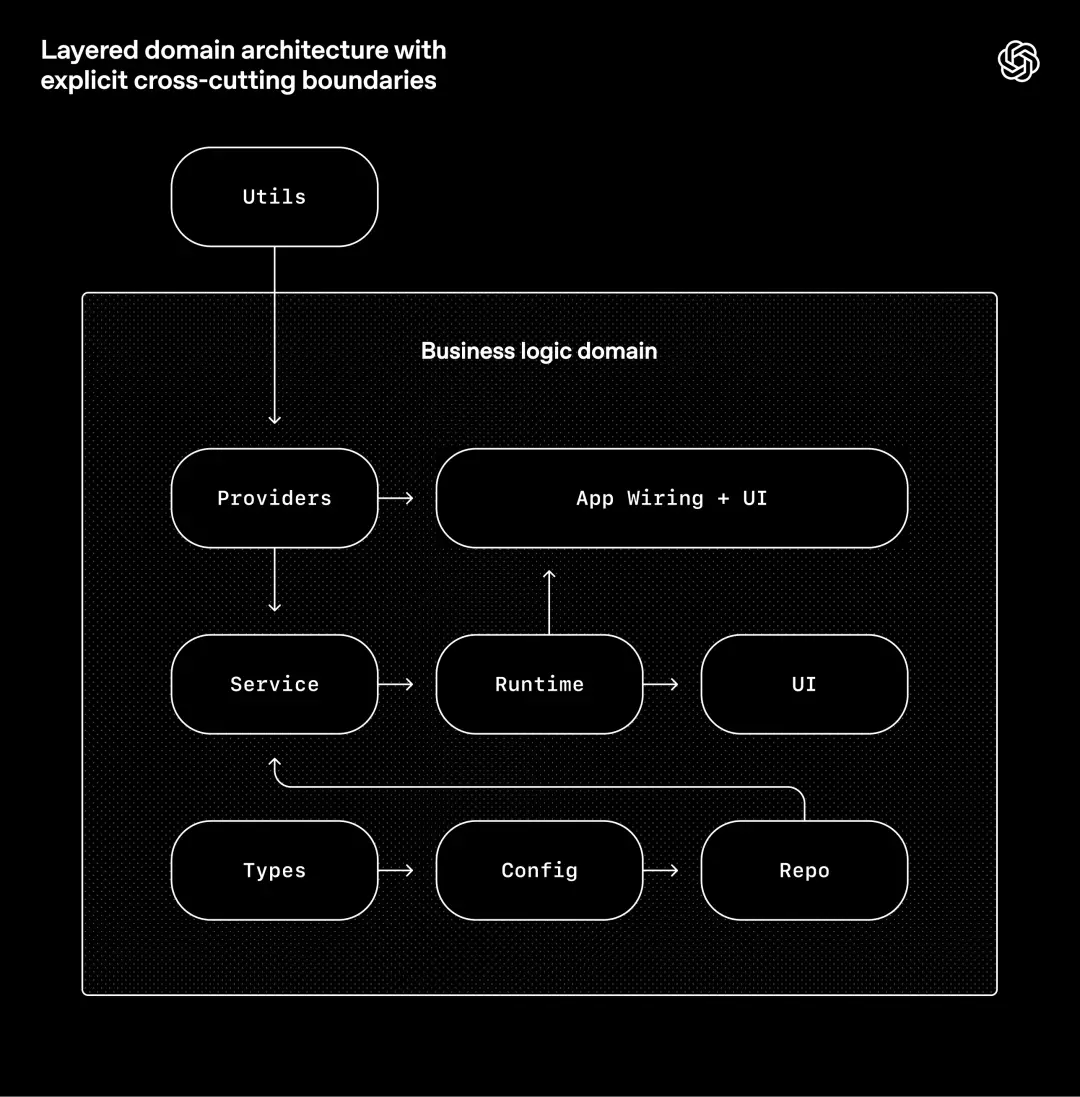
OpenAI builds systems around a rigorous architectural model. Each business area has a fixed hierarchy, and dependency directions are strictly verified, allowing only limited legal boundaries.
The rule is simple: within each business area (such as App Settings), code can only depend on "forward" along a fixed hierarchy:
Types→Config→Repo→Service→Runtime→UI
Cross-cutting concerns (authentication, connectors, telemetry, feature switches, etc.) are only available through one explicit interface: Providers.
Other dependencies are prohibited and enforced through custom lint (also generated by Codex) and structural testing.
This kind of architecture is usually carefully designed only when the company scale reaches hundreds of people.But in the case of coding agents, this is a prerequisite.
Additionally, OpenAI researchers defined a set of “taste invariants” such as:
Force structured logging
Schema and type naming conventions
Maximum file size
Platform-level reliability requirements
In this process, a clear distinction must be made between where strictness is required and where authority can be delegated.
This is like managing a large engineering platform: centralized control at the borders and a high degree of internal autonomy.
The code generated by AI may not conform to human aesthetics, but as long as it is correct, maintainable, and readable by the intelligent agent, it is OK.
In this process, human taste will not disappear, but will continue to be "encoded" into the system.
Review comments, refactoring PRs, and user bugs will be converted into document updates, or directly upgraded to tool rules.
When documentation is not enough, rules need to be written into code.
Throw away the keyboard
Be brave to control AI
This experiment from OpenAI announced:A large number of CRUD-based jobs are being reshaped.
If a system started from scratch can be built to a scale of one million lines by three people (without writing a line of code) within 5 months, is it still necessary for the huge development teams in traditional software companies to exist?
In this coming new era, the definition of an engineer will be completely rewritten.
What you need is strong "architectural capabilities" to be able to define the boundaries of the system, design constraints between modules, and build the "fence" that keeps AI from going astray.
At the same time, you also need accurate "expression skills" and learn to describe your intentions to AI in the clearest language (whether it is natural language or structured documents).
Those who refuse AI programming and insist on coding by hand will eventually be swallowed up by the wave. Only those programmers who know how to control AI are likely to become winners in the AI era.