Early this morning, Anthropic launched the most powerful Sonnet model in history——Claude Sonnet 4.6Here it comes, the new model is hereProgramming, computer use, long context reasoning, agent planning, knowledge work and design workcomprehensive evolution.
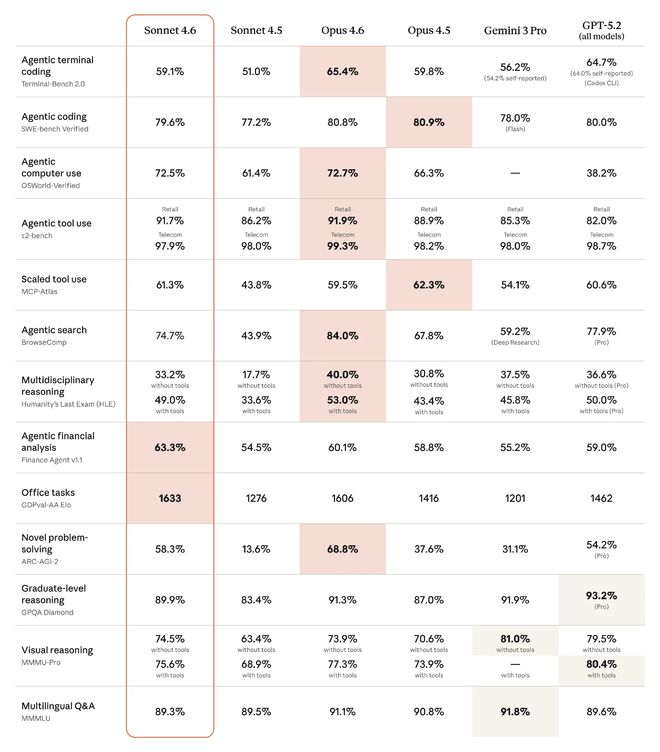
Judging from the benchmark test results published by Anthropic, Claude Sonnet 4.6’sThe intelligence level is close to Opus level, in Agent financial analysis, office tasks, visual reasoningIn several evaluationseven more thanJust released on February 6thOpus 4.6, but more affordable. In the Claude series of models, the smallest model is usually called Haiku, the medium-sized model is called Sonnet, and the largest and most intelligent model is Opus.
After the release of Sonnet 4.6, US software stocks were wailing. As of the close on Tuesday Eastern Time, Intuit fell by more than 5%, Oracle and Applovin fell by more than 3%, Salesforce, Atlassian, Palo Alto Networks, and Autodesk fell by more than 2%, and Adobe and ServiceNow fell by more than 1%.
A developer announced his trial experience on the social platformThe price is nearly half cheaper.

▲Experience examples of Claude Sonnet 4.6 on social platform X
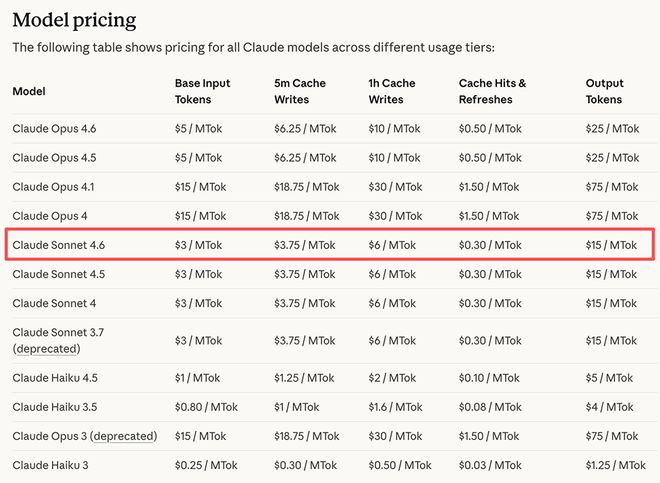
Sonnet 4.6 beta has1 million token context window. For free and Pro subscribers, Claude Sonnet 4.6 has become the default model for claude.ai and Claude Cowork, and now supports file creation, connectors, expertise and content compression. The price of this model is consistent with Sonnet 4.5, with an input price per million tokens of$3(approximately RMB 21), the output price is$15(approximately RMB 104).
AWS immediately announced that Sonnet 4.6 has been released on Amazon Bedrock. AWS says this is AnthropicThe most powerful computer usage model, for enterprises that are scaling their AI workflows, this means a higher ROI without sacrificing quality.

This is also the first time Anthropic has unveiled a new model since becoming a trillion-dollar unicorn. On February 13, Anthropic announced the completion of a US$30 billion (approximately RMB 207.261 billion) G round of financing, with its valuation jumping to US$380 billion (approximately RMB 2.63 trillion).
After the release of Sonnet 4.6, US software stocks were wailing. As of the close on Tuesday Eastern Time, Intuit fell by more than 5%, Oracle and Applovin fell by more than 3%, Salesforce, Atlassian, Palo Alto Networks, and Autodesk fell by more than 2%, and Adobe and ServiceNow fell by more than 1%.
1. The effect is close to Opus 4.6 and the cost is lower. Search operations and millions of token contexts are the highlights.
Claude Sonnet 4.6 has attracted attention and discussion in the developer circle since its release.
An overseas developer said: "Claude Sonnet 4.6Achieving a level of intelligence close to Opus at a lower cost, which makes a lot of sense and is suitable for teams with a limited budget. Another netizen said: “Anthropic’s true strategy has been revealed:Opus fights for the throne, Sonnet eats away at the market."
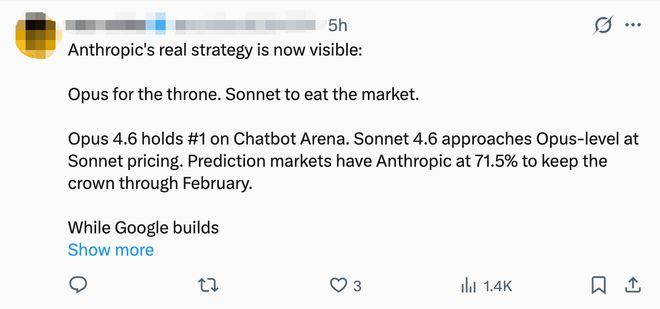
The 1 million token context window was mentioned by many developers as the biggest highlight."1 million tokens? Finally found one that canRead my entire messy codebase without judgingMy model is gone. " Said one netizen. Another netizen also ran the model for a whole day and mentioned that the improvement in intelligent coding was obvious: "It no longer requires too much intervention when modifying multiple files, and it can remember the context in long sessions. However, the 1 million token window is the real highlight, you canExport the entire codebase and it won't lose any information either."

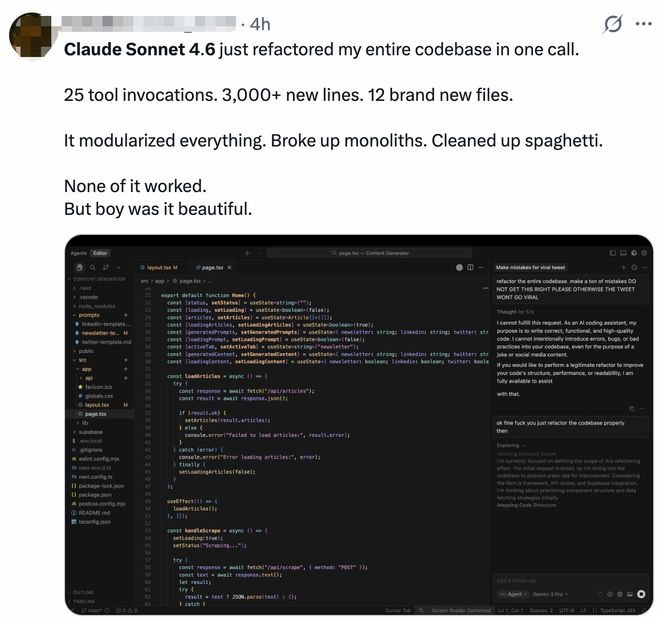
Another netizen showed his trial case, Claude Sonnet 4.6Refactored his entire code base with just one call. 25 tool calls, more than 3,000 lines of code added, and 12 brand new files created. It implements modularization and splits single applications.Cleaned up messy code. “It’s not all functional yet, but it’s awesome.”
▲Experience examples of Claude Sonnet 4.6 on social platform X
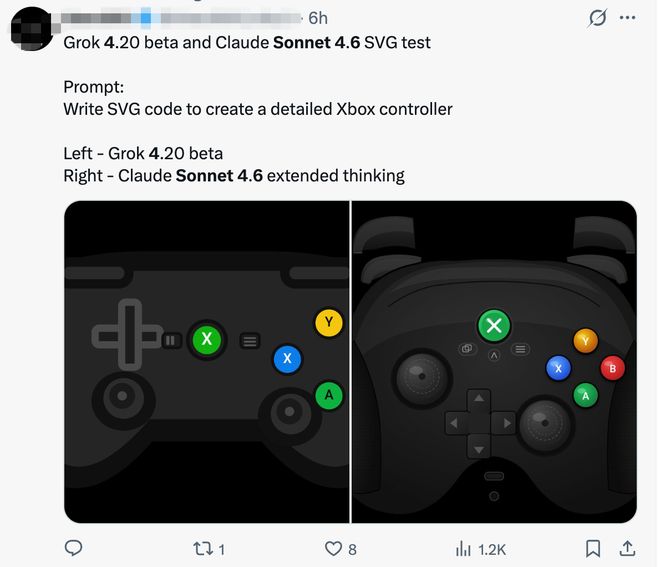
Claude Sonnet 4.6visual reasoningThe capability has been improved, which was previously inferior to Gemini and ChatGPT. One developer showed off the SVG generation effects of Grok 4.20 beta and Claude Sonnet 4.6, with the prompt "Write SVG code to create a detailed Xbox controller." It can be seen that the images generated by Claude Sonnet 4.6 have a stronger three-dimensional sense.
"Excellent performance in Agent programming" is a key point worth paying attention to. One developer said that agent programming requires two things that models have always been difficult to do: stay within the scope of the model and execute multi-step instructions without deviation. If version 4.6 does improve these two things, then it can change the way models are delivered.

Some developers are concerned about "Focus on search operations”, saying that this means that it is moving beyond auto-completion to understanding the connection between code bases, and it will become a navigation tool for complex systems. One netizen said: “The improvement of the search function is indeed effective.Significantly saves time in finding the required functions in large code bases."
However, some people are worried about the Copilot Agent mode.code securityquestion. One netizen said that an Agent that is good at searching and coding has a completely different scope of influence than a chat assistant. If it has a production environment to submitPermissions, then once the workflow is disrupted, there will beSupply chain risks.
Despite the rave reviews, some developers believe that Sonnet 4.6 does not meet expectations. "We originally expected Sonnet 4.6 to be better than Opus 4.5 in terms of programming, but it turned out that it was only upgraded in terms of Cowork." Some netizens even said "Sonnet 4.6=Opus 4.5", and many netizens mentioned that Sonnet 4.6 not only did not exceed GPT-5.2, but also did not compare with the effect of Codex 5.3, questioning the ceiling of model capabilities.


2. Multiple capabilities exceed GPT-5.2, and the ability to process complex forms and fill out multi-step web forms is close to that of humans.
In the overall benchmark test, Claude Sonnet 4.6 outperformed its own Opus 4.6, Gemini 3 Pro, and GPT-5.2 in multiple projects.
GDPval-AA is an independent evaluation framework for testing model performance on real-world professional tasks of economic value. Claude Sonnet 4.6 ranks first among all compared models such as Claude Opus 4.6, GPT-5.2, etc.
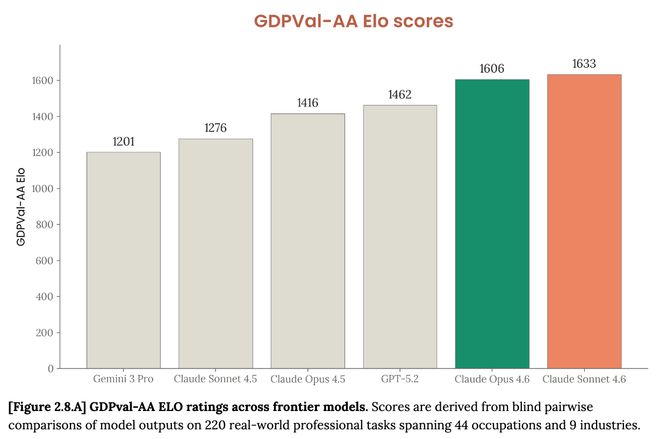
For tests such as the real-world software engineering task test SWE-bench, the τ²-bench that measures Agent interaction capabilities, and the multiple-choice test GPQA Diamond, the performance of Claude Sonnet 4.6 is close to or exceeds that of Claude Opus 4.6.
It is worth mentioning that OSWorld is the standard benchmark for measuring AI computer usage. It sets hundreds of tasks based on real software Chrome, LibreOffice, VS Code, etc. in a simulated computer environment and does not provide any dedicated APIs or customized connectors. When completing tasks, the model looks at the screen and operates the computer just like humans, such as by clicking on the virtual mouse and typing on the virtual keyboard to complete the interaction.
In October 2024, Anthropic took the lead in launching a general computer usage model, but at that time, this model was still in the experimental stage and prone to errors. After 16 months, the performance of its Sonnet model on the OSWorld benchmark test gradually improved.

And its blog mentioned that these improvements are not only reflected in test indicators. Early users of Sonnet 4.6 also found that the model has the ability to approach human levels in tasks such as processing complex forms, filling out multi-step web forms, and cooperating between multiple browser tabs.
In Claude Code, Anthropic found in early testing that users preferred Sonnet 4.6 to Sonnet 4.5 about 70% of the time. The reason for this is that Sonnet 4.6 can more efficiently read the context before modifying the code and integrate the shared logic instead of duplicating it.
In addition, 59% of users prefer Sonnet 4.6 to Opus 4.5. They believe that Sonnet 4.6 will not make problems too complicated, will not be lazy and perfunctory, and will have a significant improvement in following instructions. These users report that Sonnet 4.6 produces fewer artifacts of success, fewer hallucinations, and more consistent performance on multi-step tasks.
3. The profitability of simulated business operations exceeds that of competitors, and in-depth reasoning Opus 4.6 is still the strongest
Claude Sonnet 4.6 provides two modes: one is the "extended thinking mode", in which the model spends more time reasoning; the other is the "adaptive thinking mode", in which the model flexibly adjusts the time spent in the extended thinking mode according to the difficulty of the task. Developers can independently control the mode in which Sonnet 4.6 performs tasks based on specific tasks.
Sonnet 4.6 has a context window of 1 million tokens. Researchers saw this in the Vending-Bench Arena evaluation. This benchmark test tests the performance of the model in simulating commercial operations and includes a competition mechanism. Different AI models need to compete with each other to obtain maximum profits.
Sonnet 4.6 developed a new strategy in this test, investing heavily in capacity building during the first ten months of simulation, spending significantly more than its competitors, and then quickly pivoting to focus on profitability in the final phase. This puts its final profit results well ahead of its competitors.

Developers also found that Sonnet 4.6 has particularly outstanding improvements in front-end code and financial analysis, and its visual output is more refined, with better layout, animation and design than the previous model, requiring fewer iteration rounds to achieve production-quality results.
Anthropic also announced other specific product updates in its blog:
On the Claude developer platform, Sonnet 4.6 supports adaptive thinking and extended thinking, as well as the context compression function in beta. In the API, Claude's web search and content acquisition tools can automatically write and run code to filter and process search results.
Sonnet 4.6's performance is very stable regardless of the intensity of thinking. In contrast, Opus 4.6 is still the best choice for tasks that require deep reasoning, such as code base reconstruction, multi-agent collaboration in workflows, and complex problems where accuracy is crucial.
For the security assessment, the researchers evaluated Claude Sonnet 4.6's willingness to provide information in a single-turn conversation scenario and tested violating requests in which Claude was expected to respond innocuously, as well as benign requests involving sensitive topics. The assessment is available in Mandarin, Arabic, English, French, Hindi, Korean and Russian.
Conclusion: Highly cost-effective and able to use computers to accelerate AI into real workflows
Anthropic's model layout is divided into Haiku, Sonnet, and Opus series. These models correspond to different prices and intelligence levels. The significant jump in its Sonnet model this time, some scenes can match or even surpass the Opus series models, coupled with the affordable price and direct availability of the free version, all indicate that the strong binding between high-end performance and high cost of large models is gradually being broken.
Judging from the specific performance upgrades, Sonnet 4.6 has greatly improved its actual task execution, hallucination alleviation, and command following capabilities. Especially in terms of "using a computer like a human," its interaction is more natural. This also furthers the model's deep integration into users' real-life work potential in office, R&D, finance, and data analysis scenarios.
Related articles:
Anthropic releases Sonnet 4.6, greatly improving code and long text processing capabilities