According to the Wall Street Journal, the field of AI is undergoing a major change, which will have a profound impact on technology companies large and small.Over the past five years, the main focus in the AI field has been the training of large language models. This is a costly process that requires tens of thousands of chips, consumes huge amounts of energy, and takes place in large, remote data centers.This training process requires using a cluster of thousands of specialized microprocessor chips to feed billions of pieces of information (such as word definitions, historical facts, financial statistics, cat photos, etc.) into the model. Chip clusters run 24 hours a day, 7 days a week for weeks or even months.

Figure 1: Huang Renxun began to focus on inference chips
From training to inference
Now, as more companies deploy AI agents and try to commercialize new tools built on large language models, the focus has turned to inference: the type of computing that allows trained AI models to respond to user queries.
According to data from research firm Gartner, global capital expenditures on inference infrastructure (including chips, data centers and network hardware) are expected to exceed training capital expenditures for the first time this year. By 2029, companies will spend $72 billion on inference, nearly twice the $37 billion spent on training.
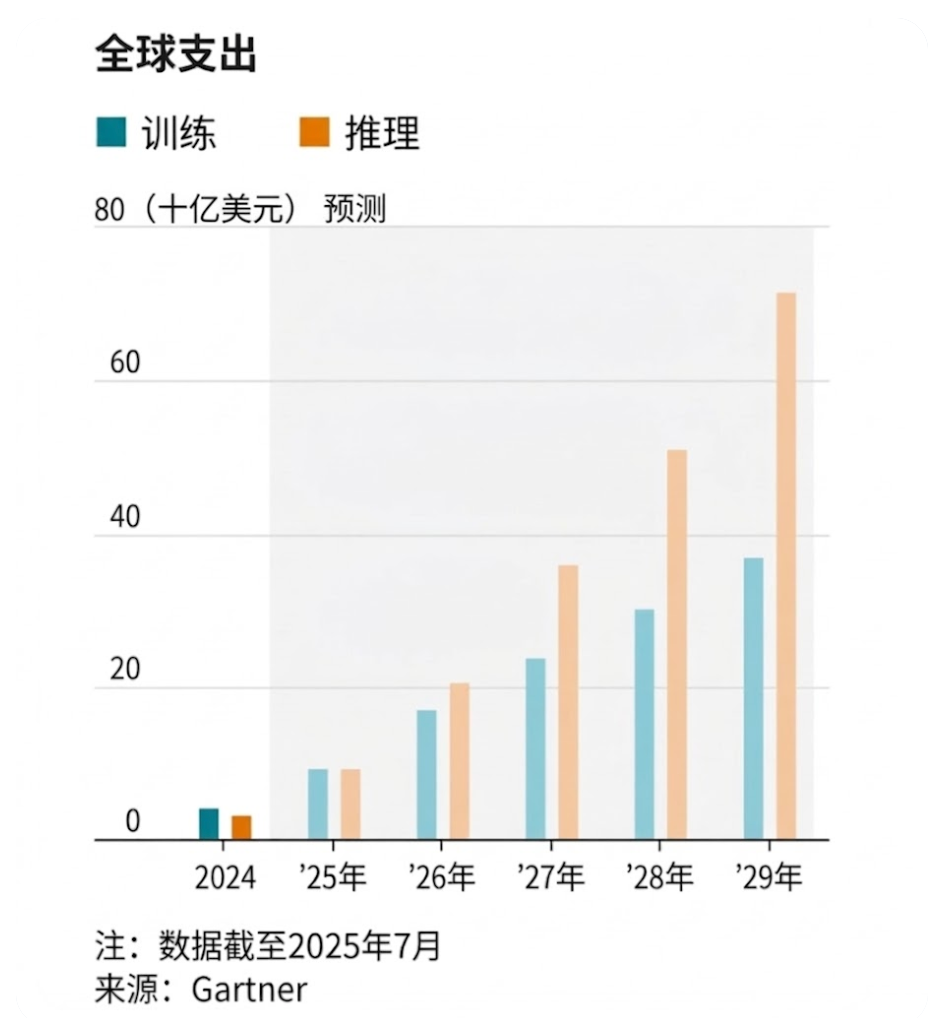
Inference spending will exceed training
The shift means major changes in the types of chips technology companies buy. Nvidia has become the world's most valuable company by selling chips called GPUs, which provide the raw processing power needed for model training.But Jacob Feldgoise, a scholar who studies AI at Georgetown University, said companies that expect to do more inference work can get performance gains by using chips optimized for inference tasks.
Manufacturers specializing in inference chips include Google, Cerebras Systems, SambaNova, etc., and they are signing orders worth billions of dollars at an increasing rate. NVIDIA is preparing to launch its own inference-specific processor after spending US$20 billion in December last year to license the technology of custom inference chip company Groq and absorb its top talents.
So, what exactly is inferential computing? How does it differ from the computation required for training? Why did demand turn to reasoning so quickly? What does this mean for the market?
Principles of inferential calculation
You can think of AI as a restaurant. The model is the chef. After a period of intensive training, learning hundreds or even billions of recipes and cooking techniques, it is ready to start taking orders.
Reasoning is the day-to-day running of this restaurant. The diner places an order (usually in the form of a question to the chatbot), and the chef prepares the meal (the chatbot generates a response).
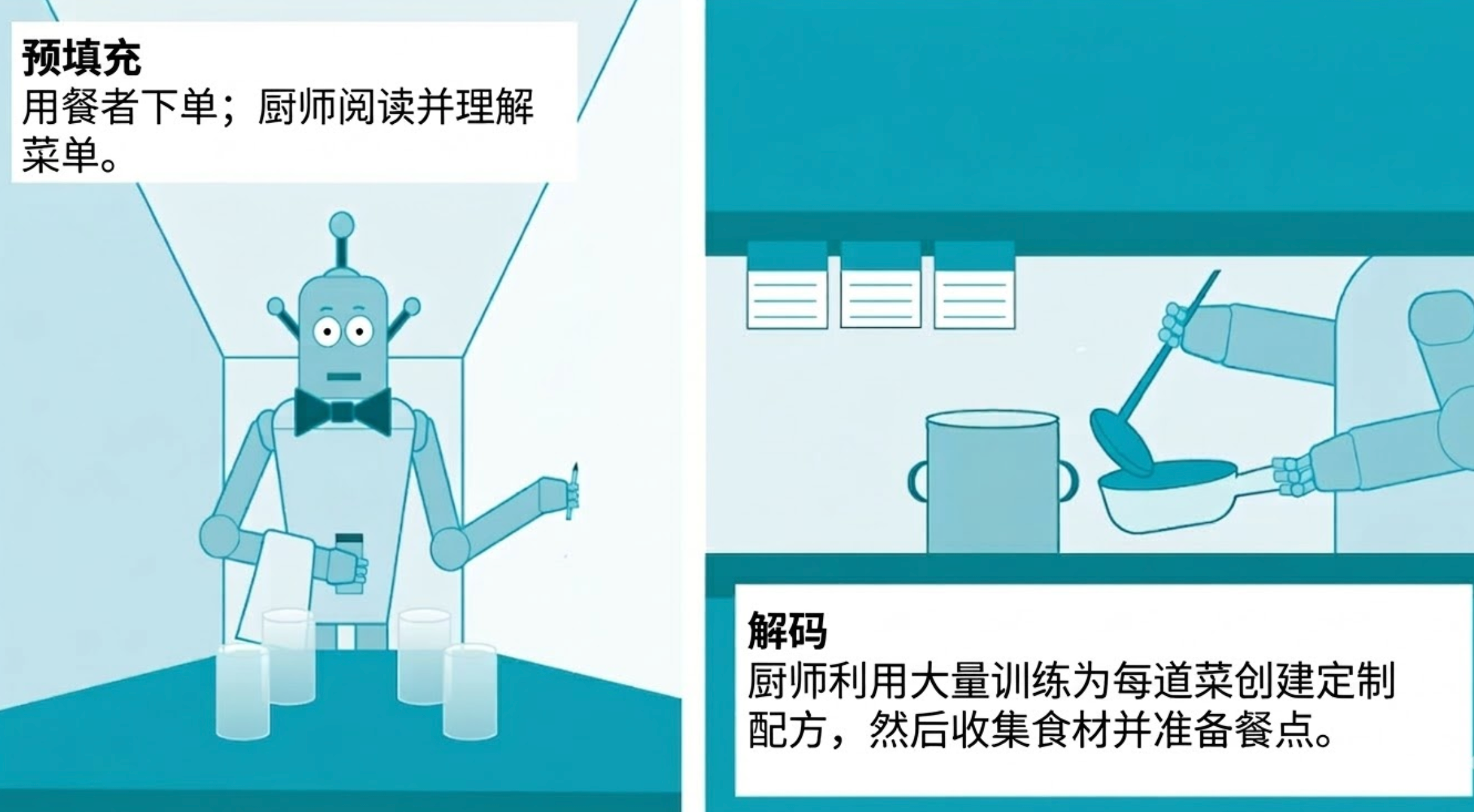
principles of reasoning
Inference consists of two stages, pre-filling and decoding. When the user enters the prompt word, the pre-population phase begins, and the model interprets the user's query by processing each word, symbol, or image in it.
Decoding is the process by which the model uses everything it learned during training to generate a query response.
These two stages of inference have different requirements on the chip: the pre-population stage requires more processing power, while the decoding stage requires more memory, in part because it must mobilize all the accumulated knowledge in order to present fresh "tokens" to the user.
What are word elements?
Tokens are the basic units of data used to process queries and generate responses.
Although the conversion ranges corresponding to different types of data vary, it is generally believed that one word element is equivalent to approximately three-quarters of an English word. Take a simple chatbot query like "What's the weather like today?" for example. The model will parse it into six to eight tokens.
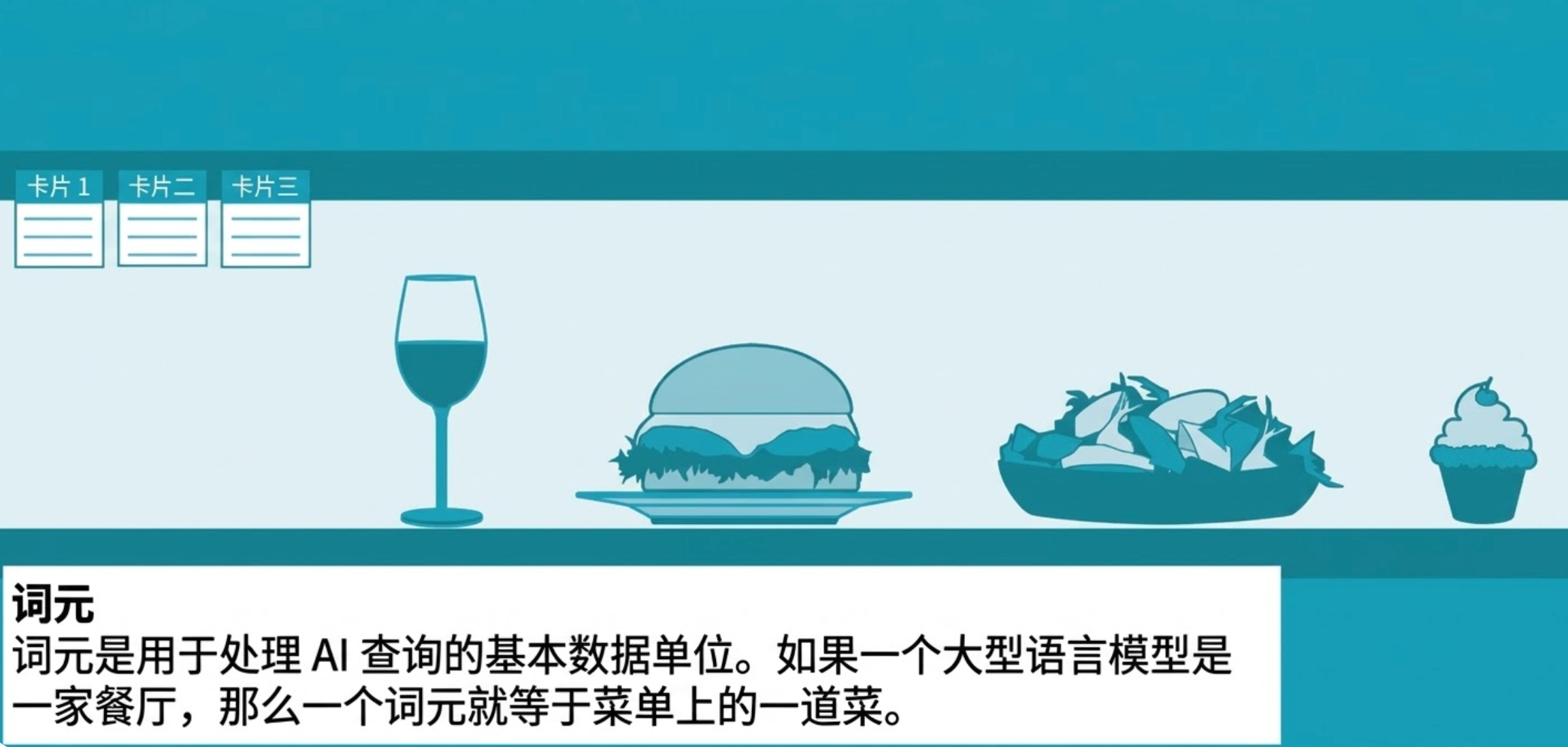
word element
The model usually generates one word unit at a time, and each word unit must be output in the correct order to ensure that the answer is smooth and reasonable.
Currently, companies trying to monetize AI tools, from accounting software to travel booking services to image generators, are obsessed with cost metrics like “words per second per watt” or “words per second per dollar.”
Tim Breen, CEO of chip manufacturer GlobalFoundries, said that this makes the ability of inference chips to efficiently output results particularly important. "Today, reducing the cost of inference is the key."
The difference between training and inference chips
Since training requires processing massive amounts of data over a long period of time, the chip used must have powerful processing capabilities, and the data center where the chip is located must have access to sufficient energy and water for cooling the chip. Training also requires memory, but if the GPU memory is insufficient, some processing tasks can be assigned to other chips or wait for the existing memory to be released.
In contrast, the inference process happens on demand and takes seconds, not weeks. "For more than ten seconds, the user has already started tapping the phone screen with his thumb, ready to do the next thing." Rodrigo Liang, CEO of chip design company SambaNova, said.
Therefore, inference chips must be equipped with larger capacities of high-bandwidth memory, and their data centers must be located close to user clusters to reduce latency. Chip startups like Ayar Labs are also increasingly turning to fiber-optic connectivity components, which can transmit data faster than copper cables and require less cooling.
“Today, everything is about scaling inference,” said Ayar Labs CEO Mark Wade.