DeepSeek-V4 preview version has finally been released. Today, DeepSeek officially announced that two models, deepseek-v4-pro and deepseek-v4-flash, with million-word ultra-long context, have been released and open source. From now on, you can log in to the official website or official app to talk to the latest DeepSeek-V4 and explore the new experience of 1M (million) ultra-long context memory. The API service has been updated simultaneously.

Text | "BUG" column Zhou Wenmeng

According to the official benchmark evaluation, the performance of DeepSeek V4 is comparable to the top international closed-source models in terms of context length, knowledge, reasoning and agent capabilities, and has reached the first-class level of international open source models. A comparison in the "BUG" column found that in terms of API call prices, the V4 version of DeepSeek, which single-handedly drove price cuts in the domestic large model industry last year, once again set the "lowest price" in the industry.
"Although the call price per million Tokens of domestic models has not dropped much, the long context length and good performance give it a very competitive advantage!" Some people in the industry lamented when communicating with the "BUG" column: "That big model price butcher is back!"
Performance is comparable to top closed-source models, and knowledge and reasoning capabilities are leading
According to DeepSeek’s official introduction, the V4 series includes two versions of the model: DeepSeek-V4-Pro with 1.6T total parameters, 49B activation parameters, and 33T pre-training data; DeepSeek-V4-Flash with 284B total parameters, 13B activation parameters, and 32T pre-training data; both natively support 1 million token contexts.
According to the benchmark test data disclosed by DeepSeek, in the knowledge and reasoning tests, DeepSeek-V4-Pro-Max achieved the best performance in the Apex Shortlist and Codeforces tests, surpassing international models such as Claude-Opus-4.6-Max, GPT-5.4-xHigh, Gemin-3.1-Pro-Hight, etc., showing strong logic and algorithm capabilities; in SimpleQA In the Verified test, it is slightly behind Gemini-3.1-Pro-High but ahead of Claude and GPT.
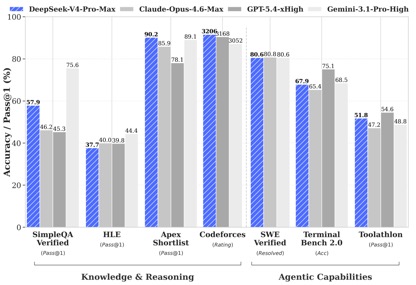
In the Agentic capability evaluation, the three models V4, Opus-4.6, and Gemin-3.1-pro were tied on the SWE Verified task, and DeepSeek achieved a level second only to GPT-5.4-xHigh on the Toolathlon task, and achieved a level better than Opus-4.6 on Terminal Bench 2.0, reflecting its advantages in complex command execution and tool invocation scenarios.
At present, DeepSeek-V4 has become the Agentic Coding model used by internal employees of the company. According to evaluation feedback, the usage experience is better than Sonnet 4.5, and the delivery quality is close to Opus 4.6 non-thinking mode.
In the evaluation of mathematics, STEM, and competitive codes, DeepSeek-V4-Pro surpassed most open source models that have been publicly evaluated and achieved results comparable to the world's top closed source models.
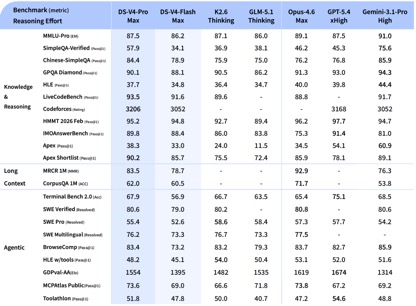
Taken together, in terms of knowledge processing and reasoning capabilities, DeepSeek-v4 has achieved an all-round lead over domestic open source models and is comparable to international evaluation capabilities. However, in terms of Agentic capabilities, although the latest DeepSeek-v4 has made good improvements, the gap between the domestic and international first-tier capabilities has not widened, and each is ahead.
"Standard configuration: 1 million contexts,The Price Butcher is "Back"
Compared with the performance advantages reflected in various benchmark tests, the biggest feature of this V4 release is the breakthrough in long text capabilities and the further reduction in API call prices.
Thanks to the new attention mechanism pioneered by DeepSeek-V4, V4 achieves world-leading long context capabilities by compressing the token dimension and combining it with DSA sparse attention (DeepSeek Sparse Attention), and significantly reduces the requirements for computing and graphics memory compared to traditional methods, making 1M (one million) context the standard for all official DeepSeek services.
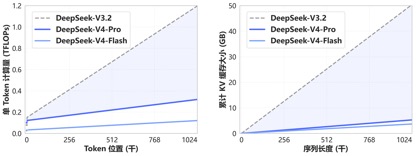
A year ago, 1 million contexts was Gemini’s exclusive trump card. Even in most of the recently released mainstream domestic open source models, the length of the model context was mostly in the 128K-200K range. However, DeepSeek directly transformed the million contexts from a “high-end closed source function” into an open source standard.
In terms of API price calls, compared with the current GLM-5.1 input unit price of 1.3 yuan-2 yuan/million tokens (cache hit), and Kimi-K2.6 1.1 yuan/million tokens (cache hit), the input unit prices of DeepSeek-v4-pro and flash versions are 1 yuan/million tokens and 0.2 yuan/million tokens respectively. Although the price drop is not large, it is the lowest, and the context length has been expanded several times.
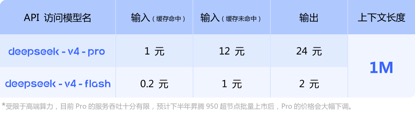
(API call price of DeepSeek-v4 series model)
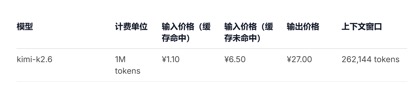
(Kimi-k2.6 model API call price)
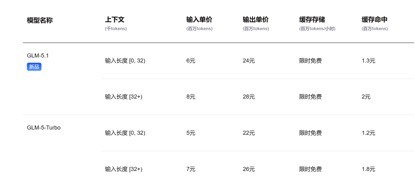
(GLM-5.1 model API call price)
"The performance breakthrough brought about by the release of DeepSeek-v4 is less impactful than the release of DeepSeek-R1. The performance is still in the first echelon, but the lead has not been fully extended." In the view of industry insiders, "The release of the V4 model is more about the improvement of long text capabilities and the further reduction of price."
This person lamented: "After the release of DeepSeek-V3 and R1 models, the performance advantages brought by the underlying technological innovation have directly promoted the collective price reduction of the entire domestic large model industry. Although the call price per million Tokens of the V4 version has not dropped much compared with domestic peers, it is still competitive. The big model price butcher is back!"
“Huawei’s computing power will be added in batches in the second half of the year, and the price of Pro will be significantly reduced.”
It is worth noting that at the bottom of the API price information released by DeepSeek-v4, the official notice states: "Limited by high-end computing power, the service throughput of Pro is currently very limited. It is expected that the price of Pro will be significantly reduced after the Ascend 950 super node is launched in batches in the second half of the year."

This means that the v4 series models released this time have been adapted to the Huawei Ascend 950 super node. As long as the Ascend 950 is launched, users will be able to use DeepSeek-v4 based on domestic computing power that is comparable to the top international closed-source models.
In the official open source technical documentation, DeepSeek also mentioned this, saying that v4 has verified the fine-grained EP (Expert Parallelism) solution on NVIDIA GPU and HUAWEI Ascend NPUs platforms. Compared with the powerful non-fusion baseline, it can achieve 1.50-1.73 times acceleration on general reasoning tasks, and can achieve 1.96 times acceleration in delay-sensitive scenarios (such as RL deduction and high-speed proxy services).

After the release of V4, Huawei Ascend also announced that "the entire range of super node products supports DeepSeek V4 series models." It is reported that Ascend 950 reduces Attention calculation and memory access overhead by integrating kernel and multi-stream parallel technology, greatly improving inference performance, and combining multiple quantization algorithms to achieve high throughput and low latency DeepSeek V4 model inference deployment.
Earlier this month, Nvidia founder Huang Jenxun said in an exclusive interview with Dwarkesh Patel: "If DeepSeek is released on the Huawei platform first, it will be disastrous for our country (the United States)." In Huang's view, although DeepSeek is an open source model and can also be used on Nvidia products, if DeepSeek is specifically optimized for Huawei's computing power, Nvidia will be at a disadvantage due to limitations such as restrictions on the purchase of high-end computing power.
Now it seems that although DeepSeek has also verified the EP solution for Nvidia's computing power, what Huang Renxun was worried about has still happened. In the view of industry insiders, "V4 is a product forced by the computing power game. In the next year, domestic large models running on domestic cards will gradually mature."
Multimodal capabilities are yet to emerge
Unfortunately, although DeepSeek V4 has been released, this version is still a pure text model without many multi-modal capabilities such as Vincent pictures and Vincent videos. This also allows ordinary users to quickly experience and evaluate a model, which adds a lot of difficulty.

After all, as the capabilities of large language models continue to improve and the hallucination rate gradually decreases, it is difficult for conventional and single knowledge question and answer to objectively reflect the comprehensive capabilities of a model. For most users, if they want to intuitively experience the capabilities of the V4 model, they have to download it and use it personally for a while.
At the same time as the release of the V4 series of models, DeepSeek has also recently revealed that it plans to raise 50 billion yuan. People close to DeepSeek revealed that DeepSeek's pre-financing valuation is 300 billion yuan, approximately US$44 billion. Currently, Tencent Holdings and Alibaba Group are negotiating to invest in DeepSeek. However, DeepSeek has not responded directly to media inquiries regarding financing-related matters.
Perhaps, for DeepSeek founder Liang Wenfeng, it is also a wise move to use the release of V4 to raise timely financing to strengthen its strength when the growth of the "intelligence" of global large models is slowing down, competition for industry talents is intensifying, and the industry's multi-modal and agentic trends are increasingly highlighted.