GPT-5.6 is here, but... what model is it? This time OpenAI did not use the familiar names of Pro, Mini, and Instant in the past. Instead, it came up with three names at once:GPT-5.6 Sol, GPT-5.6 Terra, GPT-5.6 Luna.Sol is the sun, Terra is the earth, and Luna is the moon.
Sounds fancy, like a new model universe. But it is actually the product layering we are familiar with: the strongest flagship model, a balanced model for daily use, and a lightweight model that is cheap, fast, and suitable for large-scale calls.
The official statement from OpenAI is:The GPT-5.6 series will be fully open in the coming weeks, but is currently in limited preview to a small group of "trusted partners" in the Codex and API at the request of the US government.
Let's first take a look at the publicly available intelligence.

The highest grade is the same price as GPT 5.5
OpenAI assigned GPT-5.6 three levels this time: Sol, Terra, and Luna.
According to the official statement, Sol is the flagship model, Terra is a balanced model for daily work, and Luna is a fast, cheap and lightweight model.
The three-level models were released in one go, basically corresponding to the most common three-tier structure in large model products: the strongest model is responsible for the upper limit of capabilities, the intermediate model is responsible for most daily tasks, and the lightweight model is responsible for speed, cost and high concurrent calls.
The level of the three can be seen from the price.
According to the API price announced by OpenAI,GPT-5.6 is charged per 1 million tokens: Sol costs US$5 for input and US$30 for output; Terra costs US$2.5 for input and US$15 for output; and Luna costs US$1 for input and US$6 for output.
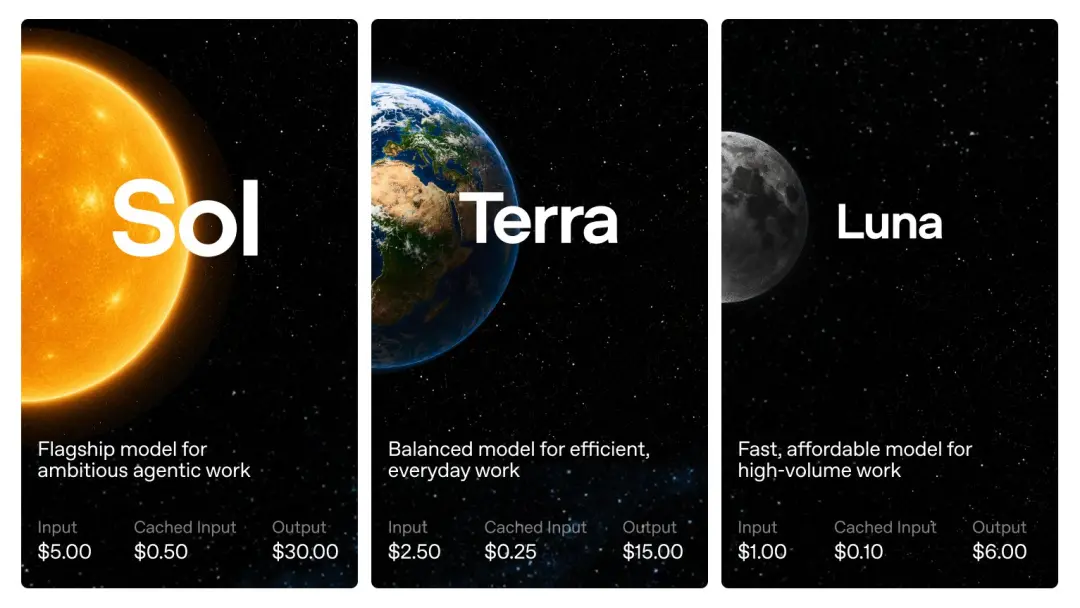
I believe you may have noticed: Although the GPT-5.6 Sol is a new generation flagship model, the price is aligned with the GPT-5.5 standard version, not the GPT-5.5 Pro.
Terra dropped directly to half of GPT-5.5, and Luna was only one-fifth of GPT-5.5.
GPT-5.5 Pro is still the most expensive model of OpenAI at present. The price is USD 30/million tokens for input and USD 180/million tokens for output. The price is 6 times that of GPT-5.5 standard version and GPT-5.6 Sol. I don’t know if there will be another GPT-5.6 Universe that is “more suitable for professional tasks” in the future (just kidding).
Sol is the highest-end model in this GPT-5.6 series, and it is also the model that spends the most time introducing in the official announcement.
OpenAI calls GPT-5.6 Sol the strongest model currently, focusing on its capabilities in coding, biological research, and network security.
To put it simply, Sol is positioned as “the best model”. It does not correspond to ordinary chat scenarios, but to tasks that are more complex and closer to real work.
For example, in a code scenario, it can continue to advance around a goal: first understand the problem, then break down the steps, then call tools, run commands, check the results, and make corrections if errors occur until the task is completed.
In order to support Sol in processing more difficult tasks, OpenAI introduced two new mechanisms to GPT-5.6.
The first one is calledmax reasoning effort, which can be translated as "maximum reasoning strength".
Popular understanding means that Sol has more time to think clearly about the problem and takes longer to conduct in-depth reasoning. It is suitable for complex tasks that cannot be solved by first reaction.
The second one is calledultra mode,It can be understood as "super mode".
The focus of this model is to allow multiple sub-agents to participate in complex tasks together. It can be understood as: in the past, an AI assistant worked on its own, but now an "AI manager" leads several assistants to handle problems separately, thereby accelerating the advancement of complex work.
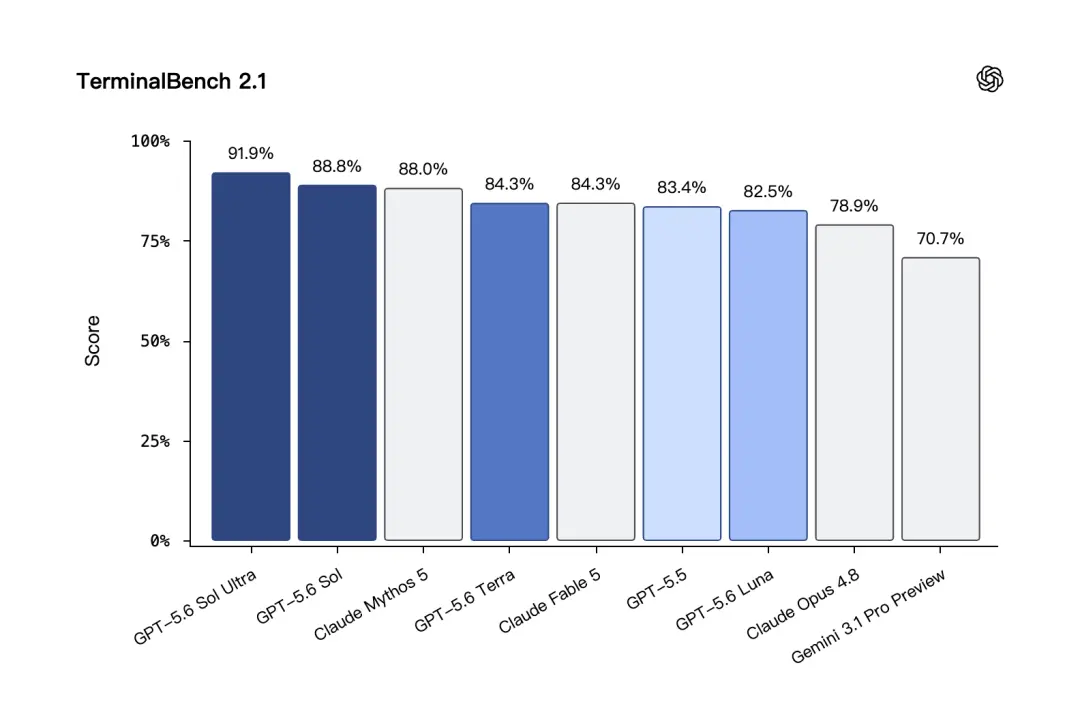
Terminal-Bench 2.1 is a test that is closer to the real development process. It tests whether the model can solve the problem step by step in the command line environment. GPT-5.6 Sol achieved a high score of 88.8% in this test, and the score was even higher in Ultra mode.
OpenAI specifically mentioned that when the model is more widely open, a more complete set of evaluation results will be released.
Terra is the middle range.
OpenAI’s introduction to Terra is not that long, but its positioning is clear: it is a balanced model for daily work.
That is to say, it does not necessarily pursue the strongest, but strikes a balance between effect, speed and cost. Officials emphasized that Terra’s capabilities are close to GPT-5.5, but the price is half the price.
In OpenAI's vision, Terra is likely to be the most commonly used one in the GPT-5.6 series. Ordinary office tasks often do not require the highest capabilities like Sol, but they need to be stable, cheap, and easy to use.
In the Terminal-Bench 2.1 test,GPT-5.6 Terra got 84.3%, which is the same as Claude Fable 5.
Luna is the lowest cost bracket.
OpenAI's positioning of Luna is also very simple: fast, cheap, and suitable for large-scale, high-frequency, cost-sensitive tasks.
For example, batch summarization, text classification, information extraction, simple question and answer, etc. These tasks themselves are not necessarily complex, but the call volume may be very large. The role of Luna is to run these lightweight tasks at a lower cost.
Among these three models, Sol is responsible for the highest capabilities, Terra is responsible for daily work, and Luna is responsible for speed and cost. It sounds fancy, but OpenAI just repackages the already mature layers of the large model industry.
But I think the name is not important, as long as it is cheap and easy to use.

Value for money
Just looking at the official announcement, the benchmarks released by GPT-5.6 Sol this time are not many. OpenAI itself said that now it is just to let the outside world know the model performance in advance, so it will share a set of evaluation results first.
But the released set of benchmarks has a clear direction, focusing on three areas: code, biology, and network security.
The aforementioned Terminal-Bench 2.1 belongs to the code direction. It tests whether the model can complete the real development process in the command line environment, including planning, repeated modifications, calling tools and verifying results.
In addition to the code, OpenAI also highlighted a biological benchmark: GeneBench v1.
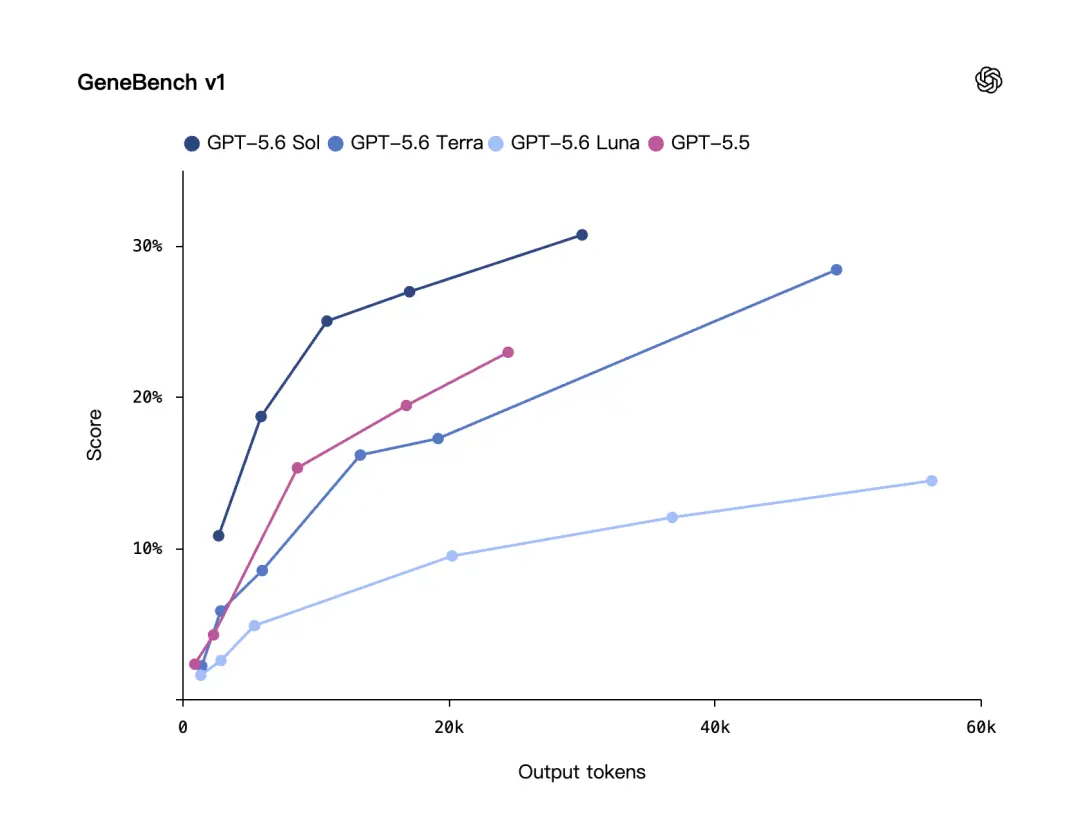
GeneBench v1 evaluates long-term genomics and quantitative biological analysis tasks, focusing on whether the model can handle analysis problems that are closer to the real scientific research process.
According to OpenAI, GPT-5.6 Sol performs better than GPT-5.5 on GeneBench v1, andUse fewer tokens.
The third key direction is network security. OpenAI claims that GPT-5.6 Sol is its current strongest network security model, especially for long-term security tasks (including vulnerability research and vulnerability exploitation related tasks).
There is a benchmark here called ExploitBench - it is not a general security question and answer, but an assessment closer to vulnerability exploitation scenarios.
OpenAI said that on ExploitBench,The performance of GPT-5.6 Sol is comparable to Mythos Preview, but only uses about one-third of the output tokens.
Although, there is still a certain gap in the official picture.
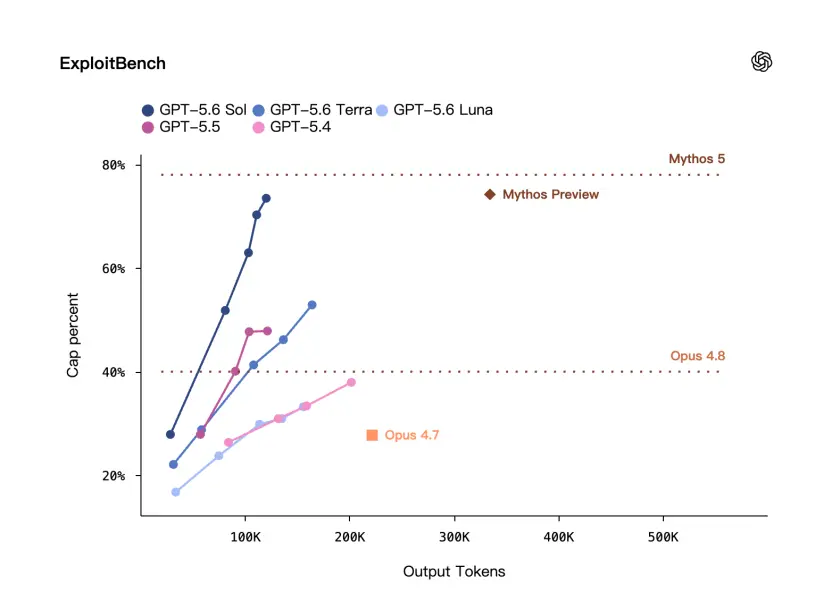
It can be seen that OpenAI repeatedly emphasized this time:While they are highly capable, they are also extremely efficient.
Fewer output tokens mean that the model may be more concise and have fewer detours when completing similar tasks, and it may also mean that the actual call cost is more controllable.
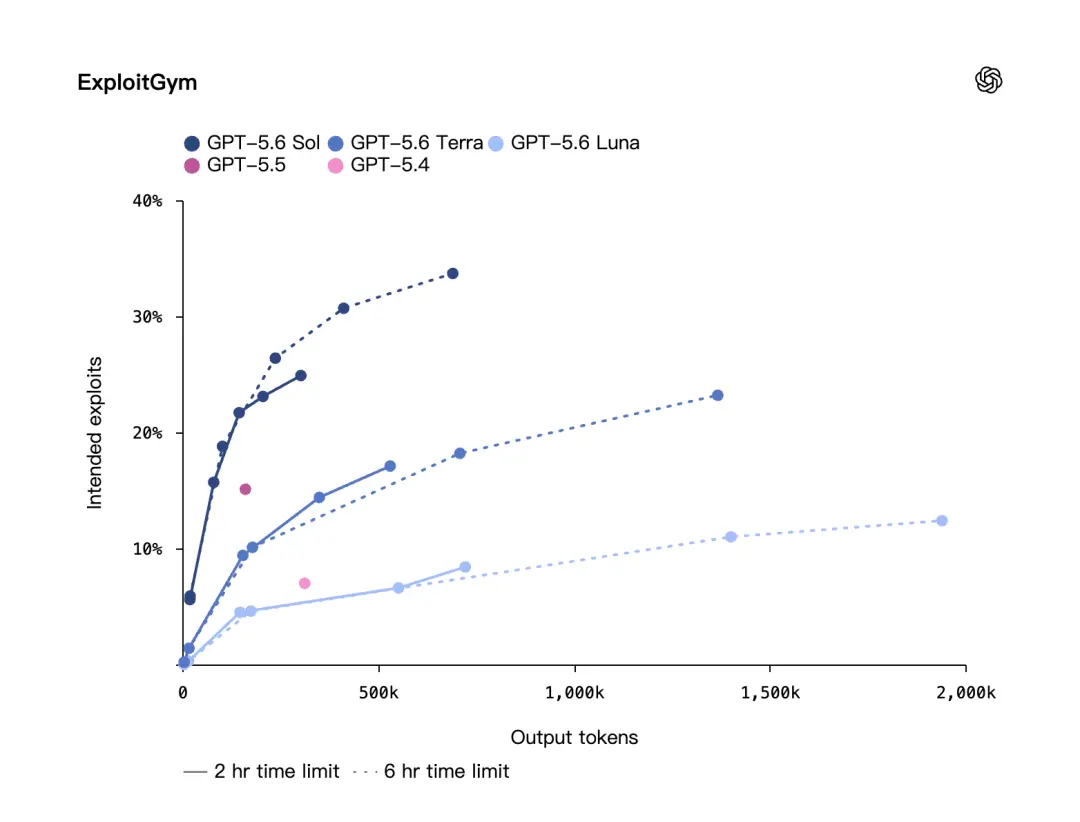
OpenAI also mentioned another cybersecurity benchmark: ExploitGym.
This benchmark was created by UC Berkeley researchers in collaboration with OpenAI and other cutting-edge laboratories. OpenAI said that on ExploitGym, the GPT-5.6 Sol, Terra, and Luna models all show significant improvement in network security capabilities, and as the inference intensity increases, the performance will become stronger.
This means that the improvement of GPT-5.6 is not only about the stronger model body, but also about the reasoning method. Give the model more time to think and let it do a longer chain of reasoning, and the results will be better.

About limited preview
If Sol, Terra, and Luna are the superficial changes of GPT-5.6, then what deserves more attention is that OpenAI has not been fully opened this time.
According to the official announcement, currently GPT-5.6 will only be available for limited preview in the Codex and API to a small group of "trustworthy partners".
Moreover, this limited preview was conducted “at the request of the U.S. government,” and the list of partners participating in the preview has been shared with the U.S. government.
In recent times, the U.S. government has significantly increased its involvement in cutting-edge AI models, especially those with stronger code, network security, and agent capabilities.
In June this year, the U.S. government issued a new executive order related to AI cybersecurity, proposing to establish a voluntary framework to allow cutting-edge model developers to contact and evaluate the model before it is more widely released.
The interpretation of this administrative order by the legal community is that it is not a compulsory license in name, nor is it a formal approval system, but it has set up an institutional framework for government participation in model pre-release evaluation.
GPT-5.6 Sol’s release model of “first previewing on a small scale and sharing the list with the government” can be seen as the first clear trace of government intervention in the release process of the cutting-edge model.
OpenAI itself also explained in the announcement that the reason for taking this approach is to explore a repeatable process with the government to support future model releases.
The core reason behind government intervention is network security.
In the official announcement, network security takes up a lot of space: OpenAI emphasizes that GPT-5.6 Sol is its strongest network security model currently and can provide stronger help in long-term tasks such as vulnerability research, vulnerability analysis, and security defense; on the other hand, it spends a lot of space explaining that it has not crossed its own Cyber Critical threshold.
In OpenAI’s preparation framework, high-risk capabilities are divided into different levels. Reaching High means that the model may amplify existing serious risks; reaching Critical means that the model may bring about new and unprecedented serious risks.
OpenAI has repeatedly emphasized that GPT-5.6 Sol does not reach Cyber Critical. In fact, it is telling the government, customers and the public: This model is very strong, especially in network security tasks, but it is not strong enough to independently complete the most dangerous network attack chains.
Network security capabilities are like a double-edged sword. The stronger they are, the more they can help defenders find vulnerabilities, write patches, and conduct security tests; but precisely because they are so strong, the government will also worry about its abuse.
Although OpenAI admitted that this release requires exploring the process with the government, it also made it clear in the official announcement that they do not believe that this government access process should become the long-term default mechanism.
The rationale: If the most powerful tools are delayed, users, developers, businesses, network defenders, and partners around the world will be delayed in getting the best tools.
In a sense, cutting-edge models are entering a new release phase.
When the capabilities of large models are concentrated in areas such as code, biology, network security, and agent execution, it will begin to be regarded as a technology that has the potential to impact real-world security.
Once the technology is viewed in this way, it is difficult for the publishing rights to remain completely in the hands of the company itself.