On June 29, an upgrade reminder email sent by DeepSeek to users showed that the official version of DeepSeek V4 is scheduled to be officially launched in mid-July, and with it will come more feature optimizations and performance improvements, as well as a peak and valley pricing mechanism. According to the email, 9:00 to 12:00 and 14:00 to 18:00 Beijing time every day are listed as peak hours, and the call price is twice the usual price. At the same time, DeepSeek stated that it will notify users via email 24 hours in advance before relevant adjustments occur.
"Permanent price reduction" before "price increase"
It is reported that this is not the first time DeepSeek has adjusted prices this year. The official API document shows that DeepSeek is billed per million tokens and charged separately based on cache hits, cache misses and output tokens. At the same time, the DeepSeek V4 series itself has high computing power requirements.
On April 24, when DeepSeek released V4 Preview, it stated that V4 Pro has 1.6 trillion total parameters and 49 billion activation parameters, and V4 Flash has 284 billion total parameters and 13 billion activation parameters. Both support 1 million tokens context.
The official document also shows that the concurrency limit of V4 Flash is 2500; while the high-performance model of V4 Pro has a concurrency limit of 500, and its supply elasticity is weaker than Flash.
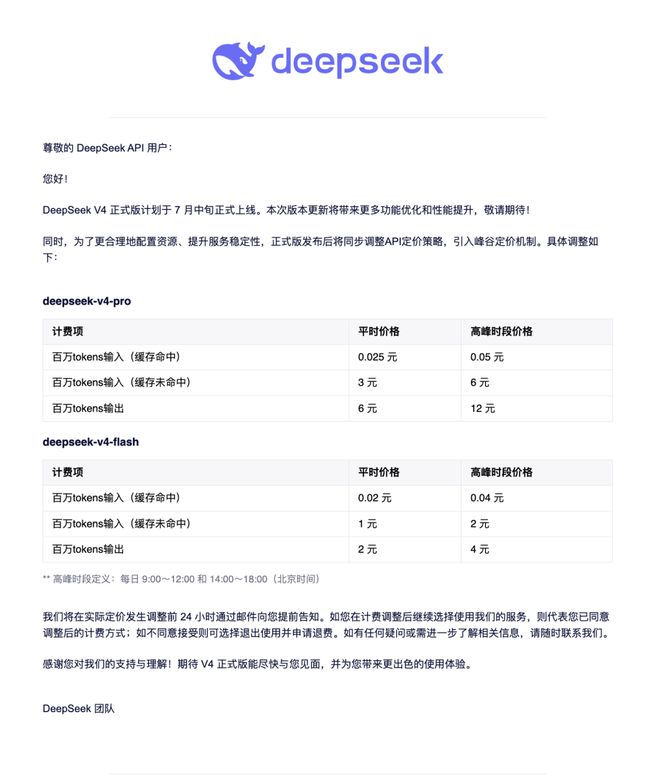
On May 23, DeepSeek announced that it would convert the previous 75% discount on V4 Pro to a permanent price, and the API fee would be reduced from the previous maximum of 24 yuan/million tokens to a maximum of 6 yuan/million tokens. The market speculated at the time that it might be related to the increased supply of Huawei's Ascend 950 chips, but DeepSeek did not respond to this.
After the permanent price reduction, the current normal price of V4 Pro is 0.025 yuan/million tokens for cache hit input, 3 yuan/million tokens for cache miss, and 6 yuan/million tokens for output. The corresponding prices of V4 Flash are 0.02 yuan, 1 yuan, and 2 yuan respectively. During peak hours, these prices will double, but will still be lower than when they were previously released.
For ordinary users, this adjustment may not be directly reflected in changes in chat application charges; those mainly affected are developers, AI application companies and enterprise customers who access the DeepSeek model through APIs.
Taking V4 Pro as an example, when calculating output tokens, if an AI application consumes 100 million output tokens per day during peak hours, the normal cost is about 600 yuan, and the peak price is about 1,200 yuan; if it consumes 1 billion output tokens per day, the cost rises from about 6,000 yuan to 12,000 yuan. For high-frequency applications such as customer service, code assistants, office agents, and search-enhanced Q&A, doubling the price may directly affect gross profit margins and calling strategies.
It’s not about giving up the low-price route
At present, DeepSeek's introduction of peak and valley pricing does not mean giving up the low-price route. To be more precise, DeepSeek just re-stratified computing resources according to usage periods, so that its low-price strategy began to change from unified cheapness to refined cheapness.
Because only judging from the pricing of tokens, DeepSeek is still in the low-price "really fragrant" range after the introduction of peak and valley time, and is still very competitive in the international market. This is also the reason for DeepSeek's price increase.
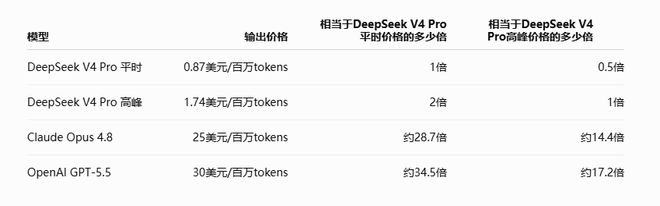
According to the DeepSeek English API price page, the output price of V4 Pro is US$0.87/million tokens, which is approximately US$1.74 based on peak doubling. In contrast, OpenAI's official price page shows that the standard API price of GPT-5.5 is $5 for input, $0.5 for cache input, and $30 for output/million tokens; the regular price of Anthropic's Claude Opus 4.8 is $5 for input and $25 for output/million tokens.
If we only look at the output tokens, the price of high-end models of OpenAI and Anthropic is still about 14-17 times the peak price of DeepSeek V4 Pro.
On the other hand, as the pricing model of large models in overseas markets shifts from fixed subscriptions to billing by tokens, the usage costs of enterprises have begun to rise dramatically. Many overseas enterprises with limited budgets are turning more calls to low-cost models such as DeepSeek.
According to previous reports, take the taxi-hailing software Uber as an example. After the large-model pricing model changed, the company's AI budget for the entire year was quickly consumed in just 4 months, resulting in the company having to restrict its use by executives. It was fortunate to be "the first major company to stop burning money on AI."
Executives from Microsoft, Coinbase and other companies have also begun to emphasize that many enterprise tasks do not always require the most expensive and largest models. These changes have pushed enterprises to adopt more "multi-model routing", that is, assigning simple tasks to cheap models and complex tasks to high-end models.
Therefore, OpenRouter data shows that open source models have accounted for about 65% of the token processing volume on its platform. Among them, the use of low-cost models in China, represented by DeepSeek, has increased significantly, which intuitively reflects that overseas users have entered the era of "cost-conscious".