Early this morning, Dark Side of the Moon launched Kimi-Dev-72B, a new open source code large model for software engineering tasks. This model achieved the world's highest open source model level in the SWE-bench Verified programming benchmark test. With only 72B of parameters, it surpassed the new version of DeepSeek-R1, which was just released on May 28 and has a parameter volume of 671B.

Kimi-Dev-72B achieved SWE-bench Verified, the AI software engineering capability benchmark test60.4%The high score is a record SOTA score for open source models.
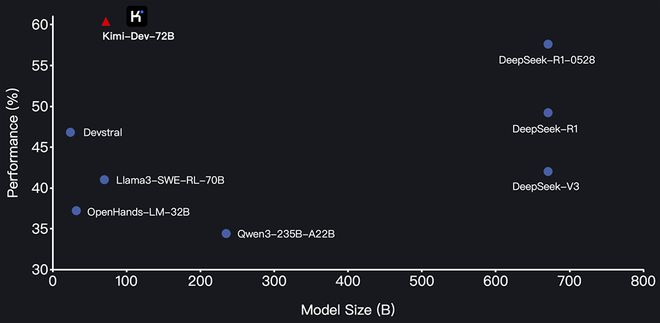
▲The performance of the open source model on SWE-bench has been verified
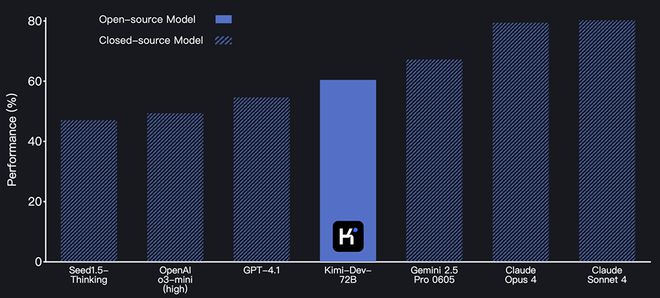
▲The performance of the closed-source model on SWE-bench has been verified
Optimized through large-scale reinforcement learning. It is able to autonomously patch real repositories in Docker and is rewarded only when the entire test suite passes. This ensures that the solution is correct and robust and adheres to real-world development standards.
Kimi-Dev-72B is now available for download and deployment on Hugging Face and GitHub. Key resources released to the community include model weights, source code, and technical reports will be released soon.
Hugging Face address:huggingface.co/moonshotai/Kimi-Dev-72B
GitHub address:github.com/MoonshotAI/Kimi-Dev
Dark Side of the Moon introduces the design concept and technical details of Kimi-Dev-72B, includingCombination of BugFixer and TestWriter,mid-term training,reinforcement learningandSelf-gaming during testing.
1. Combination of BugFixer and TestWriter
A patch that successfully fixes a bug should pass unit tests that accurately reflect the bug. At the same time, a successful test that reproduces the bug should raise an assertion error and pass after applying the correct bug fix patch to the code base. This makes BugFixer and TestWriter complementary, and a sufficiently powerful programming language model should perform well in both aspects.
BugFixer and TestWriter have similar workflows: they both find the right file to edit, and then edit the correct code update, whether that's fixing a fragile implementation or inserting a unittest function. Therefore, for both roles, Kimi-Dev-72B uses the same minimalist framework, which consists of only two stages: file localization and code editing. The dual design of BugFixer and TestWriter laid the foundation for Kimi-Dev-72B.
2. Mid-term training
To enhance Kimi-Dev-72B's prior knowledge as a BugFixer and TestWriter, Dark Side of the Moon uses approx.150 billionhigh-quality real data for mid-term training.
Taking the Qwen 2.5-72B base model as a starting point, Dark Side of the Moon has collectedmillionsGitHub issues and PR submissions serve as its mid-term training data set. The data recipe is carefully constructed to enable Kimi-Dev-72B to learn how human developers reason about GitHub issues, write code fixes, and unit tests.
Dark Side of the Moon has also undergone rigorous data cleansing, removing all repositories from SWE-bench Verified.
Mid-term training fully enhances the basic model's understanding of actual bug fixes and unit testing, making the model a better starting point for subsequent reinforcement learning training.
3. Reinforcement learning
With proper mid-term training and SFT, Kimi-Dev-72B excels at file localization. Therefore, its reinforcement learning phase focuses on improving its code editing capabilities.
Dark Side of the Moon uses the policy optimization method described in Kimi k1.5, which performs well on inference tasks. For SWE-bench Verified, Dark Side of the Moon focuses on the following three key designs:
Rewards based solely on results.Only the final execution result of Docker (0 or 1) is used as reward, and no format or process-based reward is used during training.
Efficient prompt set.Filter out hints where the model has a zero success rate under multi-sample evaluation, thereby utilizing large batches more efficiently. Adopt curriculum learning method to introduce new prompts and gradually increase the difficulty of tasks.
Reinforcement by positive examples.In the final stage of training, the most recent successful samples from previous iterations are included in the current batch. This helps the model enhance success patterns and improve performance.
Kimi-Dev-72B benefits from training on a scalable number of problem-solving tasks by using a highly parallel, powerful and efficient internal agent infrastructure.
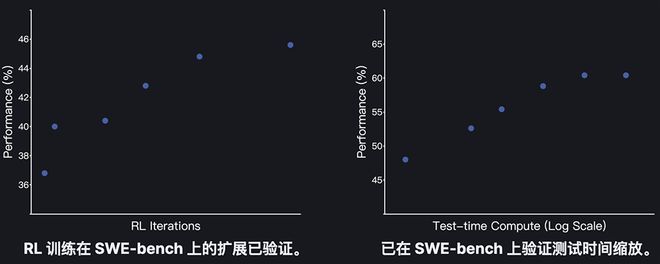
4. Self-game during testing
After reinforcement learning, Kimi-Dev-72B can master the roles of BugFixer and TestWriter at the same time. During the testing process, it will adopt a self-game mechanism to coordinate its own bug repair and test writing capabilities.

▲Self-game between BugFixer and TestWriter during testing
Each problem can generate up to 40 patch candidates and 40 test candidates (according to the standard agentless setting), and the extended effect of self-game during testing can be observed.
Conclusion: Future iterations will focus on deep integration and more seamless integration into workflows
Dark Side of the Moon is actively researching and developing ways to extend the capabilities of Kimi-Dev-72B and exploring more complex software engineering tasks.
Its future iterations will focus on deeper integration with popular integrated development environments (IDEs), version control systems and CI/CD pipelines, allowing Kimi-Dev-72B to integrate more seamlessly into developer workflows.
The company promises to continue improving Kimi-Dev-72B, conduct rigorous red team testing, and release more powerful models to the community.