Within 48 hours of Opus 4.7’s release, word-of-mouth was divided. The official list ranks first in the world, but the public test of logical reasoning plummeted from 94.7% to 41.0%. Token consumption increased by 35%, the old interface directly reported errors, and users collectively complained that it was "more expensive, stupider, and more likely to talk back." What exactly did Anthropic upgrade and what did it mess up?
"4.6 is useless at all, and 4.7 consumes as fast as a nuclear reactor."
After the release of Opus 4.7, a Reddit user left a comment under the official Anthropic post.
It's not a joke, it's the truth.

A Reddit post titled "Claude Opus 4.7 is a serious regression, not an upgrade" quickly reached 3,000 likes.
Some people posted screenshots, saying that in 4.7 they couldn’t even answer several letters in strawberry correctly.
Not to mention "tampering with resumes to make up academic qualifications and surnames", replying to users "I'm too lazy to do cross-verification", and "hitting the limit after asking three questions" are some of the most popular comments among netizens.
After trying it out, Gergely Orosz, the author of "Pragmatic Engineer", described the model as "unexpectedly aggressive" and then gave up and switched back to 4.6.

The scolding here has not subsided, but a set of data over there points to the opposite direction.
Artificial Analysis gave Opus 4.7 an Intelligence Index score of 57, ranking first in the world with GPT-5.4 and Gemini 3.1 Pro.
Entrepreneur Jeremy Howard described it as "the first model that really understands what I am doing at work." Y Combinator CEO Garry Tan is using it for projects.
Some netizens said that Claude Opus 4.7 has achieved artificial general intelligence (AGI).
In the same model, some people see the shadow of AGI, and some people feel that their workflow has exploded.
Two days after it went online, Opus 4.7 tore the AI community apart.
Why are users so angry?
Taking it apart, users' anger is concentrated on three points, each of which hits the vitality of heavy users.
First,Code ability plummets. A large number of developers have reported that after upgrading from 4.6 to 4.7, programming tasks that could be completed stably before began to error frequently.
And they are all core operations in daily workflow: code completion becomes sluggish, context understanding deteriorates, and reasoning of complex logic chains becomes significantly weaker.
Coding ability is the trump card of the Opus series. Now that the trump card has a problem, the backlash will naturally be the strongest.
A Reddit user said that he used a long refactoring task with known answers for regression testing. As a result, the model confidently changed three tests that could have passed in 4.6 and had to roll back.

The comment section flooded with hundreds of similar experiences.
second,regression in reasoning quality.
It’s not as simple as slowing down, but a perceptible degradation in depth of thinking. Complex problems that used to be solved in one step now require repeated questioning and manual guidance.
This script AI industry is no stranger. The "intelligence reduction" controversy caused by GPT-4 Turbo last year is almost exactly the same: the running score has improved, but the experience has declined.
third,Spend more money, get worse experience.
The Opus itself is Anthropic's most expensive model.
The monthly API bill for heavy users is not a small amount. After spending more money, upgrading to a newer version, but getting a worse experience, the anger does not stop at the technical level.
benchmark is stronger
But users don’t buy it
Facing the backlash, Anthropic’s response was not slow.
Anthropic pointed out in the official migration guide that Opus 4.7 has several behavioral changes compared to 4.6. It also emphasized that Opus 4.7 is still the most comprehensive and generally available model at present, and performs particularly well in long-term agent tasks, knowledge-based work, visual tasks and memory tasks.

The multi-dimensional evaluation results of Artificial Analysis are also there. Opus 4.7 scored new highs in multiple dimensions such as mathematical reasoning, multi-language understanding, and long context processing.
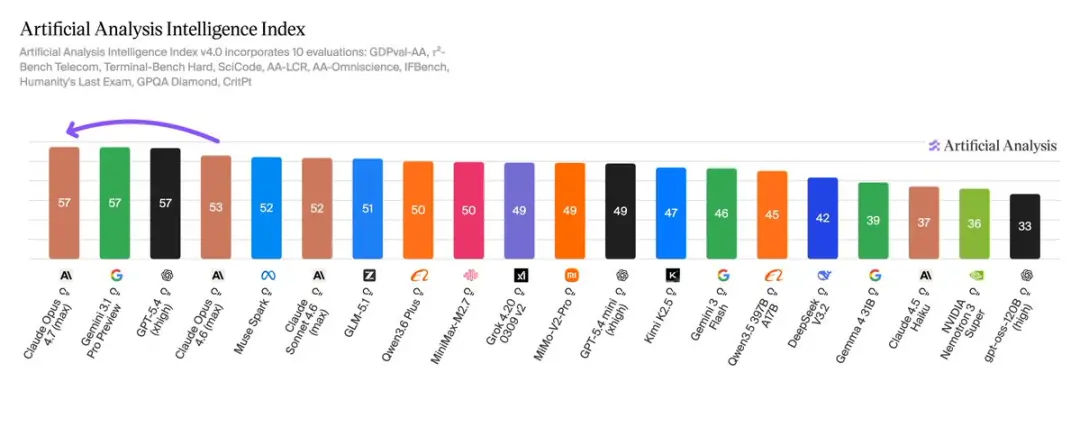
Artificial Analysis evaluation shows that Opus 4.7 (max) ranks first with 57 points, tied with Gemini 3.1 Pro Preview and GPT-5.4.
The NYT Connections Extended benchmark on GitHub also gives a top ranking.
Anthropic’s logic is not difficult to understand: iteration of large models inevitably involves the redistribution of capabilities. Some dimensions are improved, while others may be regressed. This is an engineering trade-off.
But users don’t look at this, they only look at whether they can do the work in their hands.
The price has not increased
But the bill went up
Anthropic has not adjusted its price, and the unit price per million tokens is exactly the same as Opus 4.6 and 4.5.
But the official migration guide says:When the new tokenizer processes the same text, the token usage may reach approximately 1.0 times to 1.35 times the original amount.

What's the meaning? Yesterday you used 4.6 to run a prompt for $10. Today, if you switch to 4.7 to run the same prompt, it may cost $11 to $13.5.
The unit price has not changed, but the same work consumes more tokens. Claude Code creator Boris Cherny later said on X:
Opus 4.7 consumes more thinking tokens, so we have increased the rate limit for all subscribers to compensate for this.
However, the specific increase has not been announced.

The model is not stupid
But the workflow exploded
If you are a heavy developer of Claude, you may have encountered something like this on the day 4.7 was released:
Thinking={"type":"enabled","budget_tokens": 32000} is written in the code to control the thinking budget of the model.
Running great on 4.6. Change to 4.7 and directly return a 400 error. There is no deprecation transition period, no compatibility mode, and an error is reported directly.
The official migration guide explains the alternative: use thinking={"type":"adaptive"} plus the new effort parameter instead.
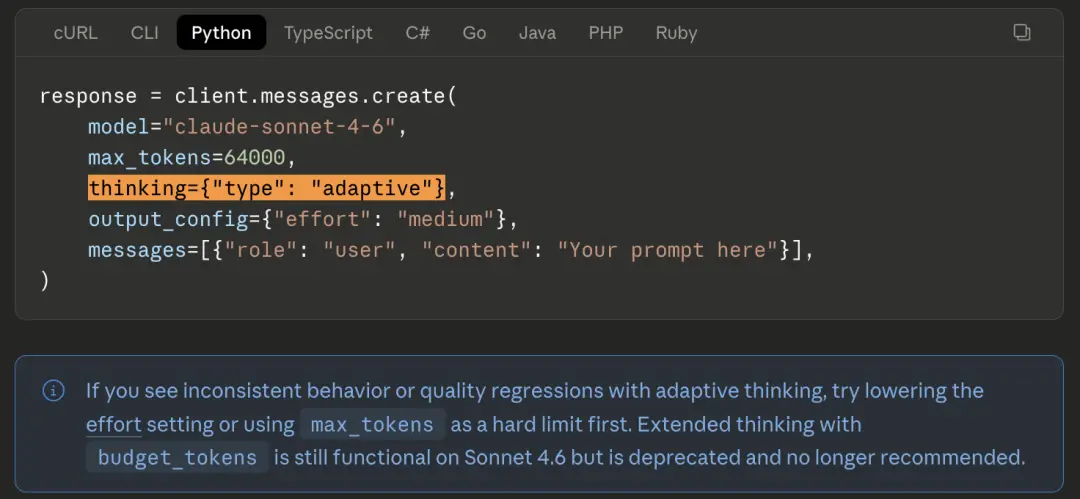
But most developers won't read the migration guide on the day the model is released.
The first thing they did was change the model name from 4.6 to 4.7 and found that everything stopped working.
A more subtle change is that thinking content is now hidden by default.
In the 4.6 era, the summary version of the model’s thinking process is displayed by default. In 4.7, the default becomes "omitted". The thinking block in the response appears to be empty.
But you are still paying full price for these invisible thinking tokens.
Anthropic’s official words: Omitting it will only reduce latency, but will not reduce costs.
It's like you ordered a set menu and the waiter said, "In order to speed up the serving time, we won't show you the dishes, but you still have to pay the full price."
"Talking back" is not a bug
One of the strongest complaints from netizens is that 4.7 has become "combative" (offensive).
Many developers have reported that 4.7 will refuse to execute instructions it considers problematic, and its tone is more than one level tougher than 4.6.
Regarding this issue, Anthropic’s official migration guide has a very crucial sentence:
Claude Opus 4.7 will understand prompt words in a more literal and explicit way.
In other words: 4.6 will "guess what you mean", and 4.7 will "do as you say".
If your prompt is originally vague, 4.6 can help you figure it out, but 4.7 won't. For some users, this is called "disobedience", but for other users, this is called "finally not guessing".
for example,Cursor designer Ryo Lu is using 4.7 for product planning and believes that this kind of precise execution is exactly what he needs.
Therefore, behind the label "talking back" is that Anthropic is transforming Claude from a "submissive assistant" into a "more assertive colleague."
According to public reviews by Artificial Analysis, Opus 4.7 scored 1753 Elo in GDPval-AA, 79 points ahead of the second place.
GDPval-AA measures the model's performance in real knowledge work tasks in 44 occupations and 9 major industries. In this dimension, 4.7 crushes all opponents, including its own predecessor 4.6 (1619 Elo).
At the same time, the hallucination rate of 4.7 dropped by 25 percentage points from 4.6, to 36%.
How is it done? According to Artificial Analysis, it mainly relies on "choosing not to answer more frequently" and would rather say "I don't know" than make up stuff.
This shows that Anthropic’s intention is not to optimize Claude’s chat experience, but to optimize Claude’s work ability.
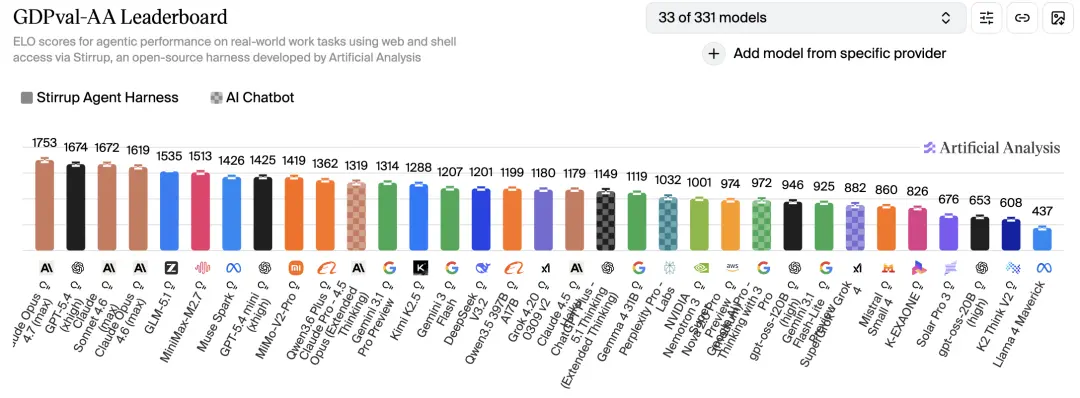
Opus 4.7 topped the GDPval-AA with 1753 Elo, 79 points ahead of the second place. This test measures the AI's ability to independently complete knowledge work in 44 occupations.
But for users, in some scenarios, they may not feel the improvement at all. Instead, they first feel that the token becomes more expensive, the interface reports errors, and the tone becomes harder.
94.7% plummeted to 41.0%
If the above three levels of problems can all be attributed to "migration costs + misaligned usage habits", there is still a set of numbers that cannot be explained by migration costs.
The NYT Connections Extended benchmark publicly maintained on GitHub uses 940 New York Times Connections puzzles to evaluate the logical reasoning and anti-interference capabilities of large language models.
This test increases the difficulty by adding additional interference words, and it is already one of the most difficult benchmarks recognized by the community.
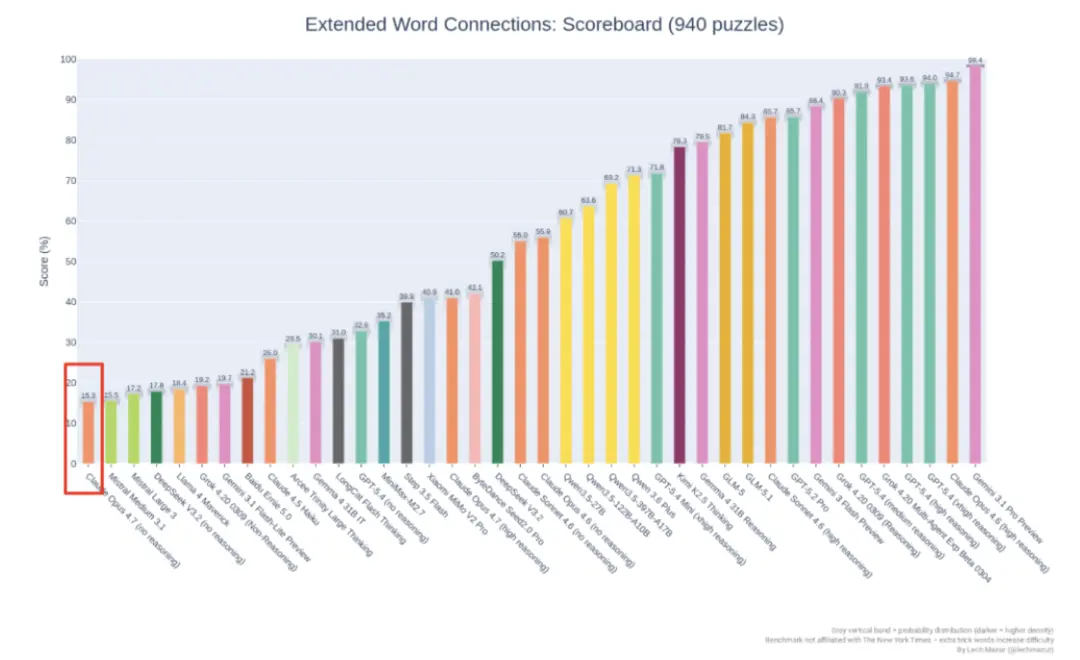
NYT Connections Extended rankings. Opus 4.6 (high reasoning) scored 94.7%, while Opus 4.7 (high reasoning) scored only 41.0%. There was a cliff-like drop in the same test.
The results are: Opus 4.6 (high reasoning) scored 94.7%, Opus 4.7 (high reasoning) scored 41.0%.
From first in grade to failing.
Another piece of data comes from the MRCR v2 benchmark of 1 million token contexts in Opus 4.7 System Card provided by Anthropic:4.6 scored 78.3%, 4.7 scored 32.2%, a drop of 46 percentage points..
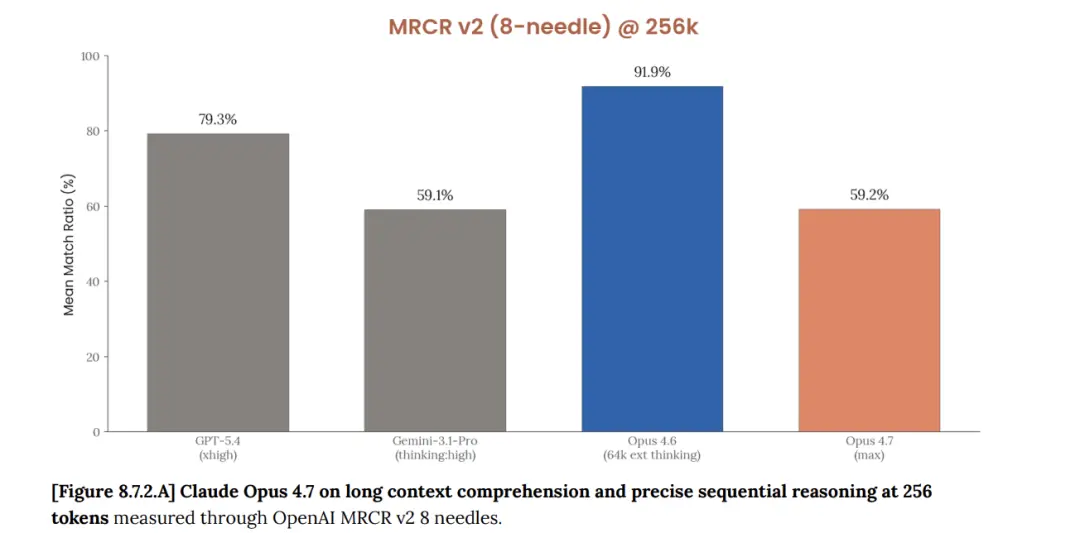
https://cdn.sanity.io/files/4zrzovbb/website/037f06850df7fbe871e206dad004c3db5fd50340.pdf
The direction of this set of data is consistent with the conclusion of NYT Connections:In some logical reasoning and long context retrieval tasks, 4.7 did show significant regression.
But let’s also be clear: these are specific types of tests. They cannot prove that 4.7 has become "stupid across the board", just like the GDPval-AA lead cannot prove that 4.7 has become "strong across the board".
User patience
Start countdown
The Opus 4.7 controversy is not an isolated case.
OpenAI has experienced the controversy of GPT-4 Turbo, and also encountered similar user backlash when it removed GPT-4o a few months ago. Now there are posts on Reddit to "mourn" Claude 4.5, full of fans who call themselves "heartbroken."
Every time a model is upgraded, a group of users lose the tools they have adapted to.
The new tokenizer makes the old cost budget invalid; the new default behavior makes the old prompt no longer easy to use; the new interface specification makes the old code report errors directly...
Each item is technically reasonable when viewed individually, but when stacked together, the entire migration cost is pushed to users at once.
Why are models getting smarter and users getting more and more anxious? Because every "better" means overturning the last "just right".
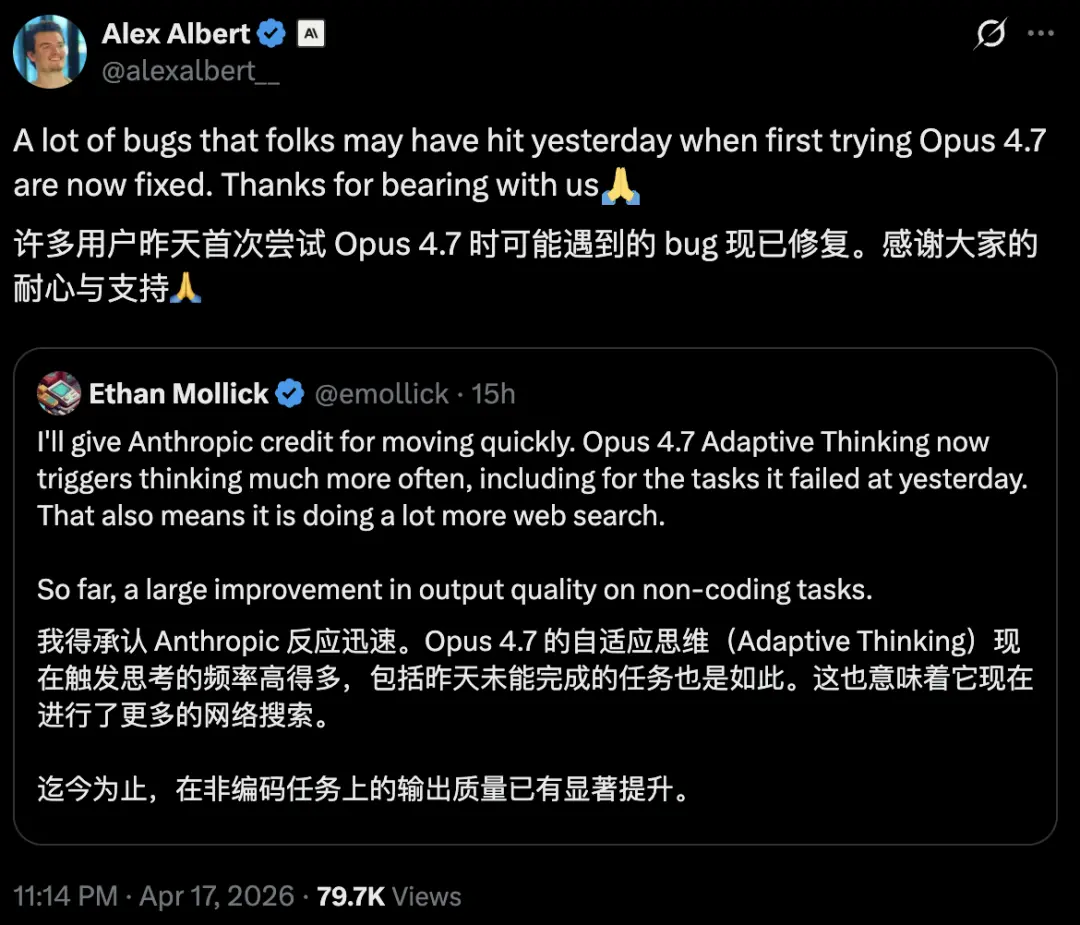
Anthropic employee Alex Albert wrote the day after the release:
Many of the bugs that people may have encountered when they first started experiencing Opus 4.7 yesterday have now been fixed. Thank you all for your tolerance and patience.
Bugs can be fixed. But trust is something that is easy to consume and slow to rebuild.
The next bottleneck in this round of AI arms race may not be just computing power and data, but also who can iterate quickly without throwing away their users.
This time, Anthropic released a migration guide, but what users want more is a promise: the upgrade cannot overthrow the original workflow and start over.
When AI changes from a toy to a productivity tool, "rapid iteration" is no longer an unconditional advantage.
How will Opus 4.8 come? Anthropic hasn't said yet.
But users’ patience has begun to count down.