Google officially launched Gemini 3.1 Flash-Lite today, claiming that it is the fastest and most cost-effective model in the Gemini 3 series. It also said that 3.1 Flash-Lite is designed for developers' large-scale, high-throughput workloads and demonstrates extremely high quality in its price range and model level.
Starting today, 3.1 Flash-Lite will be available as a preview to developers through the Gemini interface in Google AI Studio, and will be available to enterprise users through Vertex AI.
3.1 Flash-Lite costs US$0.25 per million input tokens (Input tokens) and US$1.50 per million output tokens (Output tokens). According to Artificial Analysis' benchmark test, 3.1 Flash-Lite performs better than 2.5 Flash while maintaining the same or higher quality. Its first word response speed (Time to First Answer Token) has increased by 2.5 times, and the output speed has also increased by 45%. Google says this low-latency feature is a must-have for high-frequency workflows, making it an ideal model for developers to build responsive, real-time experiences.
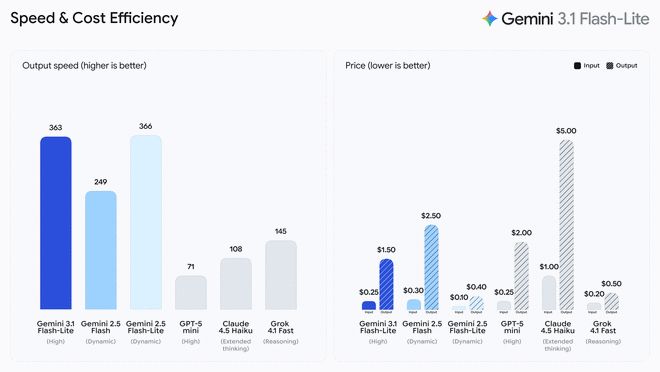
3.1 Flash-Lite scored 1432 points on the Arena.ai leaderboard. In various benchmark tests of reasoning and multimodal understanding, its performance surpasses other models of the same level. For example, it achieved a score of 86.9% on the GPQA Diamond test and 76.8% on the MMMU Pro test. This performance even surpasses previous generations of larger models, such as the 2.5 Flash.
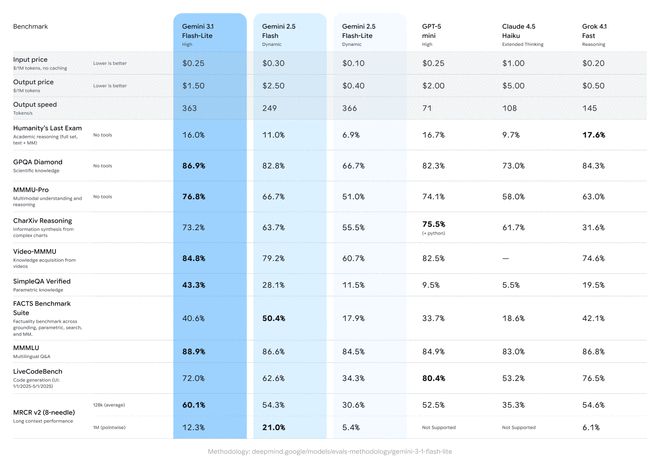
In addition to native performance, Gemini 3.1 Flash-Lite also comes standard with "Thinking Level" functionality in AI Studio and Vertex AI. This gives developers the flexibility to control how deeply their models “think” for specific tasks, which is critical for managing high-frequency workloads. 3.1 Flash-Lite is capable of handling large-scale tasks such as cost-sensitive high-volume translation and content moderation. At the same time, it is also capable of complex tasks that require deep reasoning, such as generating user interfaces and dashboards, creating simulation environments, and following complex instructions.
Google said that early access developers of AI Studio and Vertex AI, as well as companies such as Latitude, Cartwheel and Whering, are already using 3.1 Flash-Lite to solve complex problems at scale. Early testers highlighted 3.1 Flash-Lite's efficiency and inference capabilities. They said that the model can handle complex inputs with the accuracy of large-scale models, and can strictly follow instructions and maintain a high degree of consistency.