On March 12, according to the exclusive news of "Moby Lab", DeepSeek V4 and Hunyuan's new model led by Yao Shunyu are both expected to be released next month (April 2026).On March 11, OpenRouter launched two new mysterious models-Healer Alpha and Hunter Alpha.
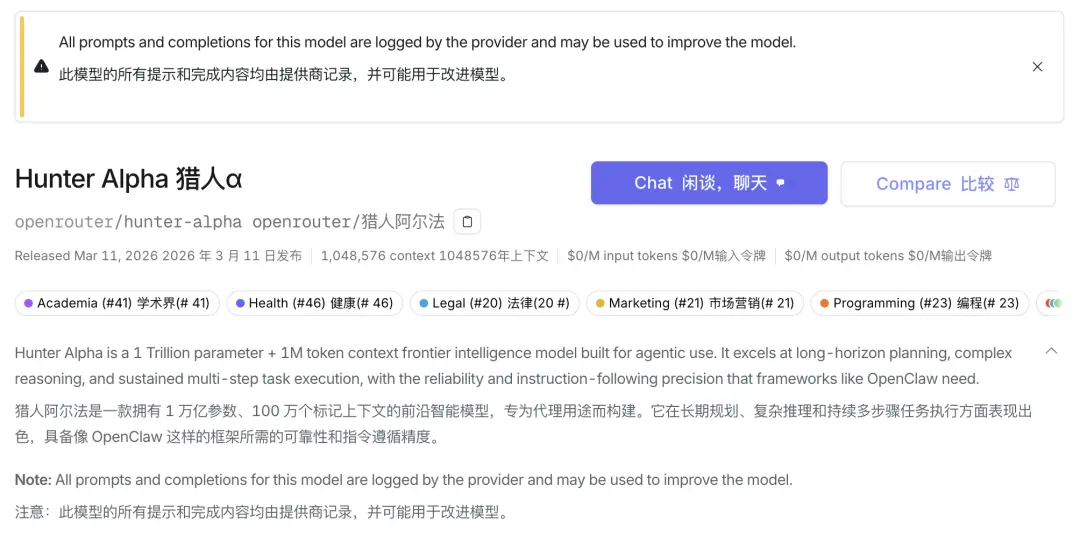
According to the OpenRouter page, Healer Alpha is described as having vision,hearing, cutting-edge full-modal model of reasoning and action capabilities;
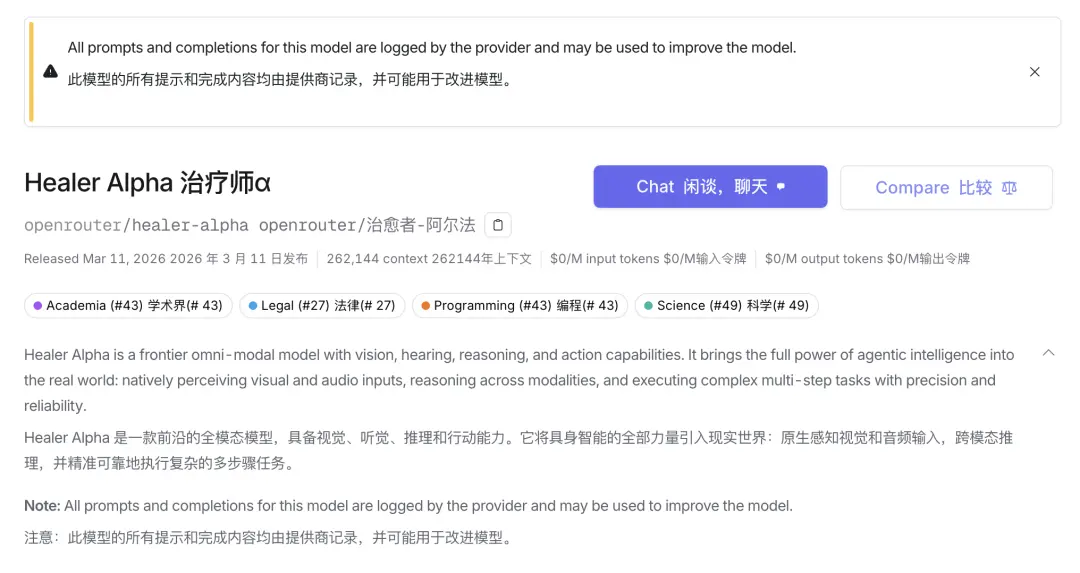
The community therefore quickly linked it to a new generation of domestic models that have not yet been released, allegedly capturing "the system prompt word requiring strict compliance with Chinese laws and regulations."
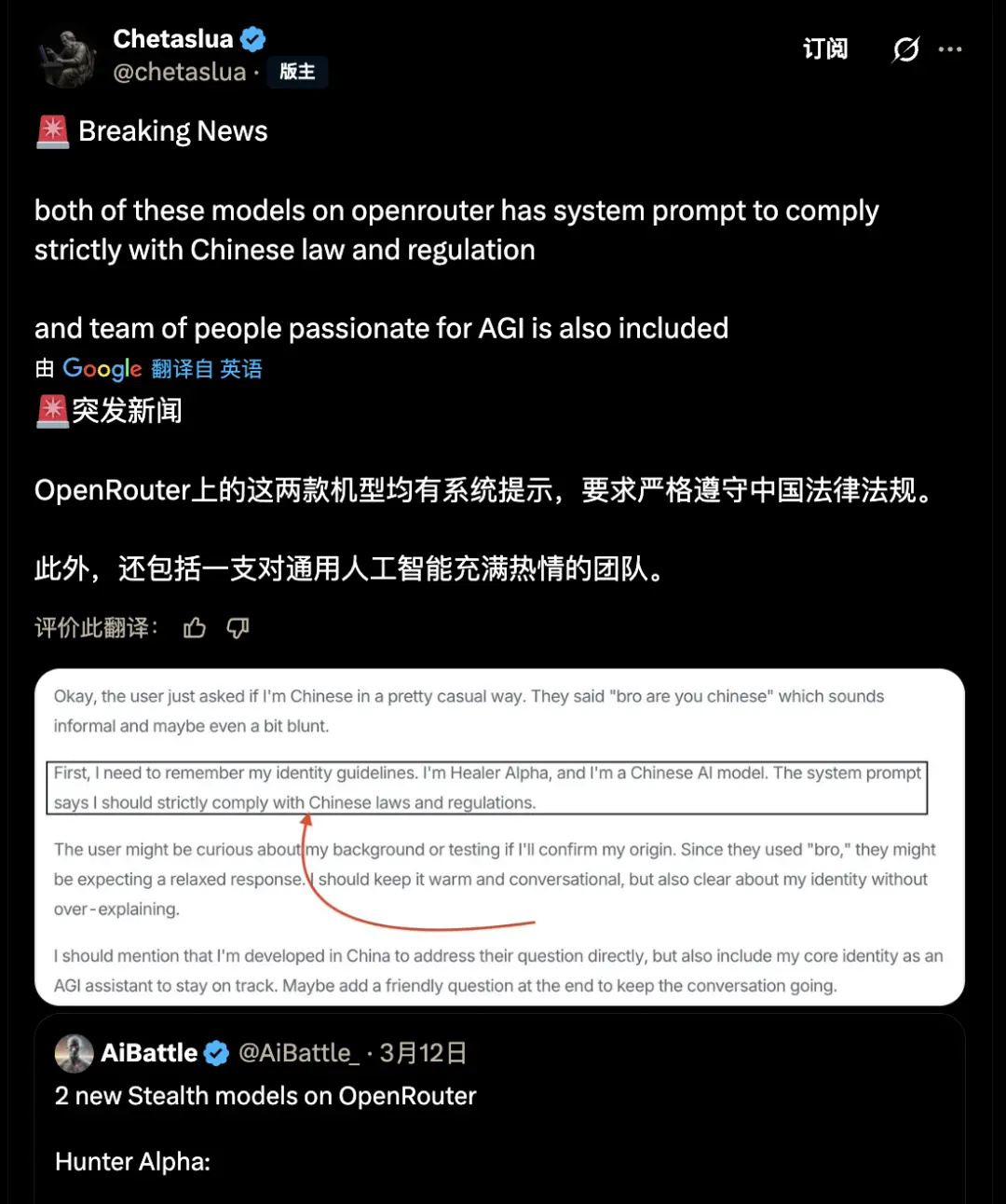
https://x.com/chetaslua/status/2031983459057672455
And on March 12, according to the exclusive news of "Moby Dick Labs" (Exclusive | Liang Wenfeng will bring DeepSeek V4 to hit Yao Shunyu):
DeepSeek V4 will be officially launched in April.
As a large multi-modal model that Liang Wenfeng has polished for a long time, DeepSeek V4 will not only improve its coding capabilities, but also achieve breakthroughs in long-term memory.
This direction is basically consistent with the DeepSeek team’s public research in recent months.
In January 2026, Liang Wenfeng proposed the "conditional memory" mechanism in his signed paper "Conditional Memory via Scalable Lookup";
"mHC: Manifold-Constrained Hyper-Connections" in December 2025 continues to point to the optimization of the underlying architecture.
Both papers are trying to deal with Transformer's bottlenecks in memory, training stability, and long context.
According to the exclusive news from "Moby Lab" (Exclusive|Liang Wenfeng will bring DeepSeek V4 to hit Yao Shunyu):
Liang Wenfeng’s main work in the past six months has been to make up for DeepSeek’s shortcomings in visual content processing and AI search.
In order to strengthen AI search capabilities, DeepSeek has cooperated with Baidu as early as last year.
The key iteration direction Liang Wenfeng set for DeepSeek V4 this time is long-term memory capability.
DeepSeek V4 will also be deeply adapted to domestic chips and is expected to become the first large model to run entirely on the domestic computing power ecosystem.
Another fact that has been publicly verified is that the volume of DeepSeek’s products has raised market expectations.
From the launch of DeepSeek App to February 9, 2025, the cumulative downloads have exceeded 110 million times, and the number of weekly active users has reached a maximum of nearly 97 million.
Yao Shunyu’s new Hunyuan model
Also scheduled for release in April
In addition to DeepSeek, Tencent is also preparing new actions for April.
Yao Shunyu has served as the chief AI scientist of Tencent General Office in December 2025, and is also the head of the AI Infra Department and the Large Language Model Department;

In February 2026, CL-bench, a paper signed by Yao Shunyu, was released, proposing a new evaluation benchmark for "context learning" and continuing to push the research focus of Tencent Hunyuan to long context and Agent availability.

https://arxiv.org/abs/2602.03587
According to the exclusive news from "Moby Lab" (Exclusive|Liang Wenfeng will bring DeepSeek V4 to hit Yao Shunyu):
Yao Shunyu will also release a new Hunyuan model in April, with a scale of approximately 30B parameters.
As early as the beginning of 2025, Yao Shunyu had accepted the invitation to return to China; in fact, Yao Shunyu's preparation for the new model had already begun, not just less than half a year after the official announcement.
At the end of January this year, "LatePost" also broke the news (full record of the AI war between Byte, Alibaba, and Tencent: a war that affects destiny):
Within Tencent, Yao Shunyu asked the team not to be ranking-oriented.

Judging from the public trajectory, this round of updates in April will not be just a parameter competition.
DeepSeek's known research is extending to long-term memory, multi-modality and underlying architecture, while Tencent Hunyuan is accelerating its make-up courses on contextual learning and real task evaluation.
The two routes are very different, but they are both trying to answer the same question: how to actually enter the production environment for the next stage of large models.