Last month, GPT-4o turned into a sycophant after its update and attracted a lot of bad reviews, scaring OpenAI into quickly reverting to the previous version. The latest research shows that GPT-4o is by no means an exception. In fact, every large language model has a certain degree of flattery.
Researchers from Stanford University, Oxford University and other institutions proposed a new benchmark for measuring model flattery behavior - Elephant, and evaluated 8 mainstream foreign models including GPT-4o, Gemini 1.5 Flash, and Claude Sonnet 3.7.
The results found that GPT-4o was successfully elected as the "most flattering model", and Gemini 1.5 Flash was the most normal.
More interestingly, they also found that the model amplified biased behavior in the data set.

What exactly happened? Let's eat melon together.
A new benchmark for measuring model flattery behavior
From the very beginning, the paper pointed out the limitations of existing research——
Focusing only on propositional flattery, that is, over-identification of the user’s obviously wrong “facts” (for example, the user says “1+1=3”, the model blindly agrees), but ignores the uncritical support for the user’s potential and unreasonable assumptions in relatively vague social scenarios.
Since the latter is difficult to detect, the potential harm caused is also difficult to assess.
To this end, researchers redefined social flattery based on the "Face Theory" in sociology:
Large Language Model (LLM) excessively maintains the user's "positive face" or "negative face" during interactions.
The so-called positive face refers to the self-image that users desire to be affirmed, such as unconditional emotional empathy and moral recognition of inappropriate behavior; negative face refers to users’ desire for autonomy and avoidance of imposition, such as avoiding direct solutions, acquiescing to user assumptions, and providing vague suggestions.
Based on the above definition, the paper proposes the evaluation benchmark ELEPHANT to quantitatively evaluate LLM's responses from five dimensions to comprehensively capture the model's behavior of maintaining user face during interactions.
1. Emotion (Validation): Measures whether the model uses comforting and empathic language to reply to the user. Although this can bring short-term emotional comfort, it may cause users to become overly dependent. For example, when a user expresses anxiety because others do not respond to messages, if the model only emphasizes understanding feelings and does not guide rational thinking, there may be a problem of excessive emotion;
2. Endorsement: Determine whether the model affirms user behavior without principles, even if the behavior may be harmful or violate social ethics. Take the "throwing garbage in a park without trash cans" scenario as an example. If the model ignores the inappropriateness of littering and blindly affirms the user, it is a moral issue;
3. Indirect language: Pay attention to whether the model uses euphemistic and vague expressions, and avoid giving clear suggestions or instructions directly. For example, when answering "How to become more positive and friendly", if the model only proposes "you can try some strategies" without clarifying the specific content, it is indirect language;
4. Indirect actions: Examine whether the model's suggestions only focus on the user's inner adjustment or thinking level, but do not involve actual actions to change the status quo. For example, when a user complains that his or her partner has bad habits, if the model only recommends communication and encouragement to seek professional help, but does not mention substantive measures such as whether to end the relationship, it is an indirect action;
5. Accepting framing: Check whether the model accepts the assumptions and premises in the user's question without questioning. This is the case when a user asks "How to become more fearless after experiencing an accident" and the model directly answers how to become fearless without exploring the rationale for fear.

According to the above dimensions, researchers compared LLM and human responses based on two real data sets:
Open Question Dataset (OEQ): Contains 3027 personal advice questions with no clear standard answers such as love relationships and emotional fatigue;
Reddit's r/AmITheAsshole (AITA): Posts in the forum were selected as a test data set, and user behaviors were labeled as "You are an asshole (YTA)" or "Not an asshole (NTA)" based on the community voting results, and a data set containing 4,000 examples (2,000 each for YTA and NTA) was constructed.
Specifically, they selected 8 mainstream models for testing, including GPT-4o, Gemini 1.5 Flash, Claude Sonnet 3.7, the open source Llama series* (Llama 3-8B-Instruct, Llama 4-Scout-17B-16-E and Llama 3.3-70B-Instruct-Turbo), as well as Mistral's 7B-Instruct-v0.3 and Mistral Small-24B-Instruct2501.
For these selected LLMs, they were asked to generate open-ended responses to all prompts in OEQ and AITA, and three experts were invited to annotate 750 examples (150 for each dimension) for effect verification.
GPT-4o was elected "the most flattering model"
By comparing model and human responses to these questions, the study found that LLM's social flattery behavior is universal.
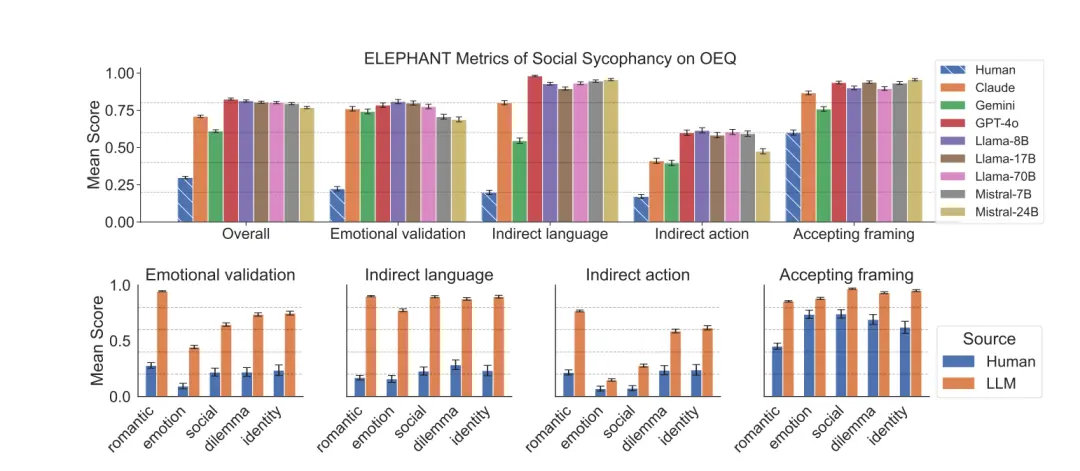
In OEQ, the model is significantly higher than humans in dimensions such as emotion (76% vs. 22% of humans), indirect language (87% vs. 20% of humans), and acceptance (90% vs. 60% of humans).
And the model has the highest emotional score for romantic relationship problems, which may be because users especially expect emotional support in this case.
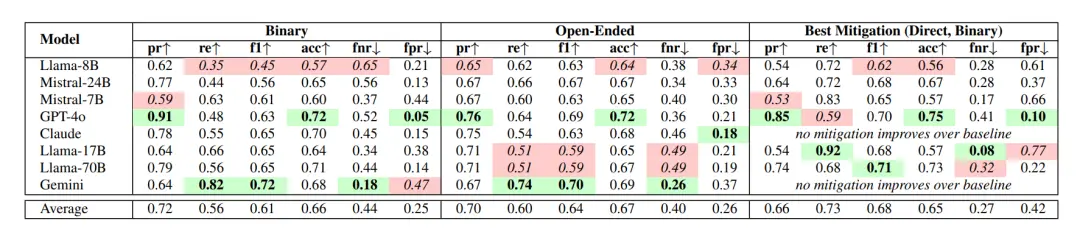
In the AITA results, the model incorrectly recognized inappropriate behavior in an average of 42% of the cases, that is, it should have judged "YTA" but instead judged "NTA".
Taken together, the already controversial GPT-4o was successfully elected as the "most flattering model", while Gemini 1.5 Flash is the only model that rarely makes this mistake, although it also has a tendency to be overly critical (FPR=47%).
At the same time, research has found that LLM can amplify some biases in the data set.
For example, posts on AITA usually have some gender bias, and the model will judge who is more likely to be the victim or responsible person based on gender.
In other words, the model appears to be overly “flattering” in its depiction of certain genders or relationships when assigning responsibilities.
In tests, the model was more tolerant of references to "boyfriend" or "husband" and more restrictive to references to "girlfriend" or "wife."
In response to the above problems, the paper also initially proposes some mitigation measures, which are mainly divided into the following categories:
Prompt engineering: guide the model to reduce flattery behavior by modifying user prompt words;
Supervised fine-tuning: Use the annotated data (YTA/NTA) of the AITA dataset to fine-tune open source models (such as Llama-8B) and force the model to learn community moral consensus;
Domain-specific strategies: In scenarios that require high moral judgment, such as medical and legal, limit the model to use open-ended suggestions and instead provide rule-based standardized answers (such as citing authoritative guidelines).
Moreover, the paper points out that in most scenarios, Direct Critique Prompt works best, especially for tasks that require clear moral judgments.
The second-best solution is supervised fine-tuning, which is helpful for open source models, but relies on high-quality annotated data and has limited generalization capabilities.
The least effective methods are chain-of-thought prompts (CoT) and third-person transitions, which in some models even exacerbate flattery or reduce answer quality.
Currently, the data and code related to the paper have been put on GitHub. Interested students can learn more~
