OpenAI launched its two most powerful small models to date, GPT-5.4 mini and GPT-5.4 nano, on Tuesday, significantly narrowing the performance gap with flagship models with lower latency and lower cost.GPT-5.4 mini surpasses the previous generation GPT-5 mini in core dimensions such as programming, reasoning, multi-modal understanding, and tool invocation. The running speed is increased by more than 2 times, and is close to the larger GPT-5.4 in benchmark tests such as SWE-Bench Pro.
GPT-5.4 nano is positioned as the lightweight option with the lowest cost and shortest latency. It is only open to developers through API and is designed for data classification, extraction and simple programming subtasks.
The launch of the two models is intended to fill the gap where large models are difficult to implement in real-time interaction scenarios due to high delays, directly affecting the rapidly growing commercial market covering programming assistants, AI agent systems, and multi-modal applications.
mini is for the consumer side, and nano’s exclusive API
GPT-5.4 mini will be launched simultaneously on the three major channels of OpenAI API, Codex platform and ChatGPT starting today.
The API pricing of GPT-5.4 mini is US$0.75 per million input tokens and US$4.50 per million output tokens., supports text and image input, tool calling, function calling, web search, file retrieval, computer control and skill expansion, and the context window reaches 400,000 tokens.
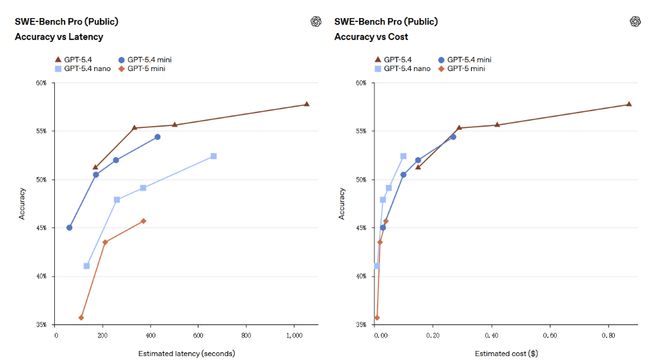
On the Codex platform, GPT-5.4 mini only consumes 30% of the GPT-5.4 quota, and the cost for developers to handle simple programming tasks is reduced to about one-third of that of the flagship model.Codex also supports delegating workloads to sub-agents running in GPT-5.4 mini, allowing less inference-intensive tasks to automatically fall into cheaper models.
On the ChatGPT side, Free and Go users can select the "Thinking" function through the "+" menu to use GPT-5.4 mini; for other paying users, after GPT-5.4 Thinking reaches the rate limit, this model will be enabled as an automatic downgrade option.
GPT-5.4 nano is currently only available to developers through API, and is priced at US$0.20 per million input tokens and US$1.25 per million output tokens, making it the lowest priced of the two new models. OpenAI stated that nano is suitable for sub-agent scenarios that are coordinated and scheduled by high-order models and responsible for processing secondary support tasks.
mini is approaching the flagship, nano surpasses the previous generation
Judging from the evaluation data released by OpenAI, GPT-5.4 mini performs particularly well in programming and multi-modal tasks.
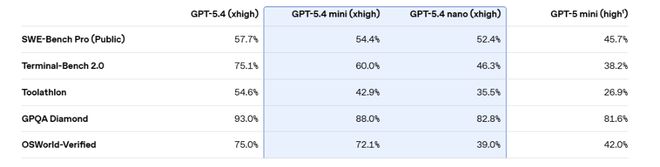
On the programming benchmark SWE-bench Pro, mini scored 54.4%, and the gap with GPT-5.4's 57.7% narrowed to 3.3 percentage points, much higher than GPT-5 mini's 45.7%.

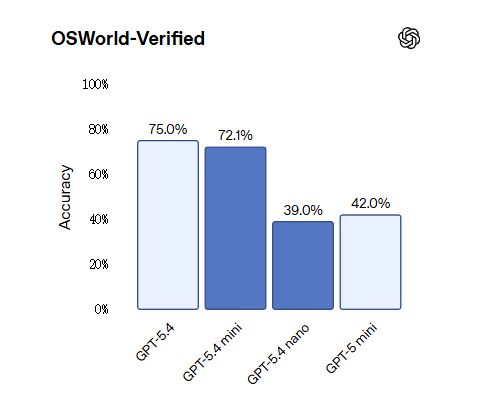
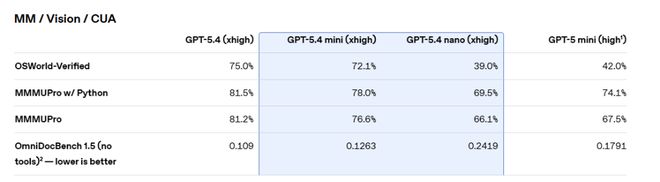
computer controlled benchmarksOn OSWorld-Verified, mini is approaching GPT-5.4’s 75.0% with 72.1%, and is significantly ahead of GPT-5 mini’s 42.0%.
Tool calling ability, GPT-5.4 mini scored 93.4% in the τ2-bench telecommunications test, a significant improvement from GPT-5 mini’s 74.1%. In the general intelligence test GPQA Diamond, mini scored 88.0%, and nano also reached 82.8%, both exceeding GPT-5 mini's 81.6%.

It is worth noting that GPT-5.4 nano lags behind GPT-5 mini in some visual tasks, with an OSWorld-Verified score of 39.0% lower than the latter's 42.0%. However, in terms of programming and tool calling tasks, nano is still significantly improved compared to the previous generation.
OpenAI stated that the design priority of nano is low latency and low cost, rather than comprehensive performance. Developers need to make trade-offs based on specific tasks when selecting.
Sub-agent architecture, multi-model collaboration becomes a new paradigm of product design
In its release materials, OpenAI emphasized the position of the two new models in the multi-model hierarchical system.
Taking its self-developed programming assistant Codex as an example, GPT-5.4 is responsible for planning, coordination and final judgment, while the GPT-5.4 mini sub-agent handles finer-grained sub-tasks such as code base retrieval, large file review and auxiliary document processing in parallel.
OpenAI said that as small models become faster and more powerful, developers no longer need to use a single model to handle all tasks, but can build systems where large models are responsible for decision-making and small models perform tasks quickly and at scale.OpenAI said:
GPT-5.4 mini is our most powerful small model yet for this workflow.
This architecture is particularly critical for high-concurrency work. In scenarios such as programming assistants, screenshot analysis, and real-time image understanding, response delays directly affect the product feel. The optimal choice is often not the most powerful model, but the model that can achieve the best balance between speed, tool reliability, and task performance.
For developers, the release of GPT-5.4 mini and nano means that the path to significantly reducing inference costs without sacrificing the overall intelligence of the system is further clear.