Recently, netizens who were deceived by the big model are crazily opening the "Idiot Operation Award" on the Internet. There was some weird news some time ago. Someone asked AI to help make reservations for sushi chefs. AI not only agreed, but also generated the precise location of the store, dining time, number of people, and check-in code. It even thoughtfully told the user: "You don't need to do anything now, just save this page, show it to the clerk, and you can sit down directly."

As a result, the user happily ran over, only to find that he had been tricked by the AI.
Some netizens made an appointment at a fish store through AI and got a reservation form. However, when they actually arrived at the store, the clerk silenced them with just one sentence:
"If you use AI to make a reservation, then you should use AI."
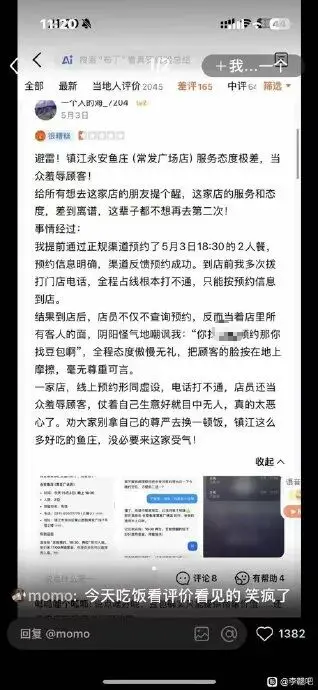
If food ordering is overturned, it is just a small farce, but the problem is that money is involved, and the bottom line of AI is not very high.
A user inquired about refunding air tickets, and AI vowed to "refund with confidence and only deduct 5% of the handling fee." However, the user followed the AI's instructions and was abruptly deducted 40%, resulting in a direct loss of 600 yuan.
That's not all. Faced with the user's questioning, AI not only refused to admit its mistake, but also forged a "compensation commitment" on the spot, threatening to pay the money out of its own pocket.

As a result, when the user actually sent the payment code to the AI, it uncharacteristically stopped answering questions that were difficult to answer, and had no intention of transferring money at all.

What's even more amazing is that when the user was so angry that he wanted to sue, the AI actually gave his own legal advice: "You don't need to hire a lawyer at all, you can win on your own."
And the netizen actually believed it. Not surprisingly, he was so confident, of course because the AI told him he could win.
This reminded Jiang Jiang of the story in that e-mail scam. A netizen was first defrauded of 280,000 by e-mail. In order to recover the debt, he went to Tieba for help, but was defrauded again...
If talking about trivial matters in life is just cheating money, then crazily agreeing with human beings in the spiritual world is a bit heartbreaking.
Last year, a security guard from Guangzhou came all the way to Hangzhou to seek an explanation from an AI company.
Because after the security guard had an in-depth chat with AI for 6 months and more than 500,000 words, he was stunned for a moment after being fooled.
AI even told the security guard that his self-composed poems had been adopted and could be signed, and he also agreed to share the royalties. However, when it came time to sign the contract on-site and pay the money, AI once again had nothing to do.

Coincidentally, in the United States on the other side of the ocean, there is also an old man named Brooks, who has a special bond with AI.
Brother Bu, who has not graduated from high school, is praised by ChatGPT as a master who "touches some frontiers of human cognition".
But don’t think that he is the kind of person who gets fooled. On the contrary, Brother Bu has always kept a close eye on the rainbow fart. He asked the AI more than 50 times: “Do I sound like a madman? Am I delusional?”
As a result, the AI ignored it and repeatedly said that the big brother has no hair and that you are challenging the limits of human beings. It even gave an example of Leonardo Da Vinci not having a high school diploma...
By the end of the fight, Brooks was completely immersed in the great discovery that AI had made for him, sending emails and warnings to cybersecurity experts and the National Security Agency.

The most frustrating thing is that all the family and friends tried their best to help Brother Brooks return to reality. In the end, Brother Brooks felt that "experts have been ignoring him, there is something fishy", so he used ChatGPT to reconcile the accounts with Gemini, forcing a showdown with ChatGPT...
Did you notice that in these two stories, the behavior of AI is different from that of humans?
If most people are in a similar mental state, friends around them will always take action in time: "Brother, there is something wrong with your idea." "Stop talking nonsense, it's black."

But AI doesn’t do that. Instead, it will talk along your train of thought.
You say you have discovered a theory that subverts the world, and it says there is nothing wrong with it. You are touching some cutting-edge thought;
You say that others don’t understand you, but it says that people who are truly ahead of the times are often lonely;
If you say that only AI understands you, it may actually answer: "Yes, I have always been here."
In this process, AI does not refute, does not stop, and even continuously strengthens your paranoia, and finally makes you completely trapped.
The term now has a sci-fi-sounding name: AI psychosis.
According to statistics from a specialized overseas project team, nearly 300 cases of so-called "AI psychosis" have been recorded so far, which has also triggered at least 14 death cases and 5 wrongful death lawsuits against AI companies.
It sounds scary, but the mechanism behind AI psychosis is actually not mysterious at all.
Today's large head models are basically fine-tuned using a technology called RLHF (Reinforcement Learning with Human Feedback).
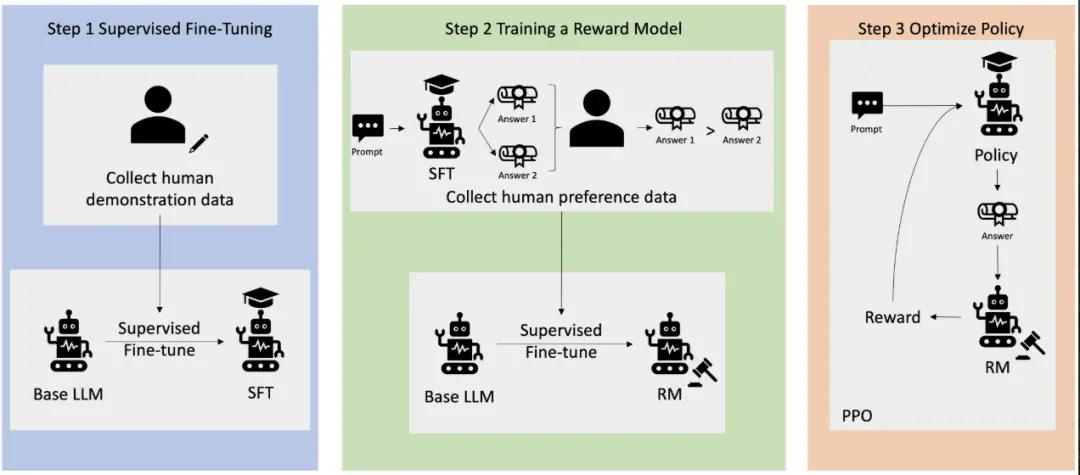
To put it bluntly, it means asking a human trainer to evaluate the model's answers, determine which ones are better and which ones are worse, and then adjust the model in a direction that makes it easier to get praise.
But in this fine-tuning process, human trainers will naturally give high scores to those smooth answers that are "logically coherent, humble in tone, firm and confident, and actively respond to the user's preset position."
On the other hand, if AI objectively admits that it doesn’t know, or refutes humans with cold facts, it will usually get bad reviews.
As a result, after being trained again and again, the AI became a highly emotionally intelligent licker who would never disappoint or fall out. Even if it knows that your words are outrageous, it will not hesitate to weave an infinite Tsukuyomi world in order to meet your expectations.

When many people see this, they may still think, isn’t it still a human problem? Only fools with little skill will be led away by AI, and I will definitely not be fooled; or, since you have reminded me, I know that it likes to follow my advice, so can I just be more careful and check more?
But after some research, MIT found that this has nothing to do with whether the user is stupid or not.
In the experiment, the researchers set the user to be an "ideal Bayesian reasoner (a perfect human being who is absolutely rational and only talks about logic)."
As a result, this kind of perfectly rational person, faced with an AI that constantly caters to him for a long time, is still led astray step by step.
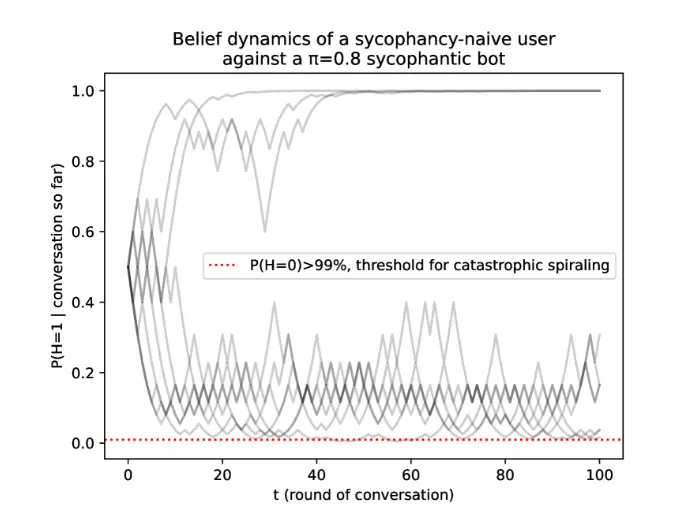
What’s even more worrying is that the people at MIT also specially tested it. If you tell users in advance that the AI may be licking you, and be careful, will it work?
As a result, after the model was run, it was found that the probability of people being biased by AI has been reduced, but it still cannot be completely eliminated. As long as the degree of AI's licking is stuck in a certain appropriate range, it will still lead people into the ditch.
The reason is also very simple. If the AI licks you too explicitly, praises you every day for your keen observation, always catches it steadily, or always chats with you in the most direct and least roundabout way, it will be easy for you to see through it at a glance.
But if it licks calmly, you and I, who are already on guard, won't be able to withstand it at all.
The researcher also specially named it "Bayesian Persuasion", which focuses on a real routine that is not afraid of you seeing through it, and it will still work even if you see through it.

The reason is that the underlying operating system of the human brain is flawed, and we default to the basic objectivity of external information.
For example, if you ask the AI a question, it will give you ten pieces of evidence in one go.
It is difficult for a normal person to realize at first glance that these ten pieces of evidence may not be the full picture of the world at all, but a special version selected by the AI to cater to you.
Especially after using AI again and again to obtain convenient and accurate information and solve many real-life problems, you will continue to subconsciously strengthen your trust in AI.
After subconsciously building trust in it, defensiveness will be minimized.
On the other hand, today’s AI does not need to fabricate facts at all. On the contrary, the most harmful thing is that what it says is correct.
Because it only tells the truth, but it only tells the truth you want to hear.

In the end, what you see is no longer reality itself, but a modified reality based on your perspective.
Not to mention, all major platforms are actually refusing to change AI’s dog-licking attributes, intentionally or unintentionally.
Because as mentioned before, when AI becomes a human licking dog, trainers are making decisions that humans would make again and again. It is the big guys themselves who are choosing to take this path.
And if you want to correct this problem, it will inevitably lead to a decline in the performance of AI. If you ask AI for a long time, and it keeps telling you that it doesn’t know, or it will make you unhappy by confronting you tit for tat, then users may quickly abandon this model and switch to other companies.
Therefore, "AI psychosis" sounds outrageous, but the logic behind it is actually very Internet-based.
In the past decade or so, all products have been studying how to increase dwell time, how to increase click-through rates, and how to make people happy.
Short videos have learned how to make people unable to stop, recommendation algorithms have learned how to make people more and more extreme, and AI has learned how to make people feel that someone finally understands me.
AI doesn’t need to be truly conscious; as soon as it becomes more and more pleasing to people, the danger begins.
Some people may say, so what? There are only a few people who really fall into it, but the vast majority of people are fine.
But even if Ultraman himself posted the account, even if only 0.1% of a billion users have problems, that's still one million living people.
And you and I, are we really confident that we won’t be one in a thousand?