Gemini core developer Dustin Tran officially announced yesterday that he has switched jobs from Google DeepMind to xAI to develop a new generation of Grok! Musk also retweeted the tweet immediately, confirming that the news of this new colleague joining xAI was true:
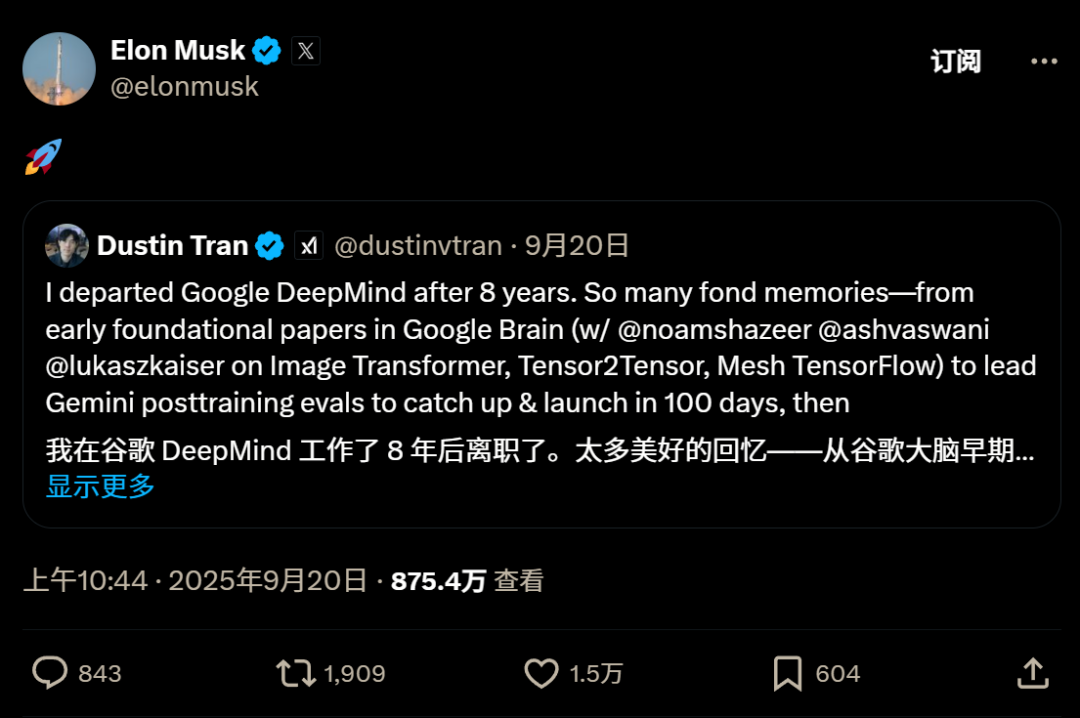
It is known from the official announcement that Dustin Tran has joined xAI for at least a few weeks and participated in the development of Grok 4 Fast, but he did not modify his external title introduction until today, even slower than Musk retweeted.
This was also discovered and ridiculed by sharp-eyed netizens:
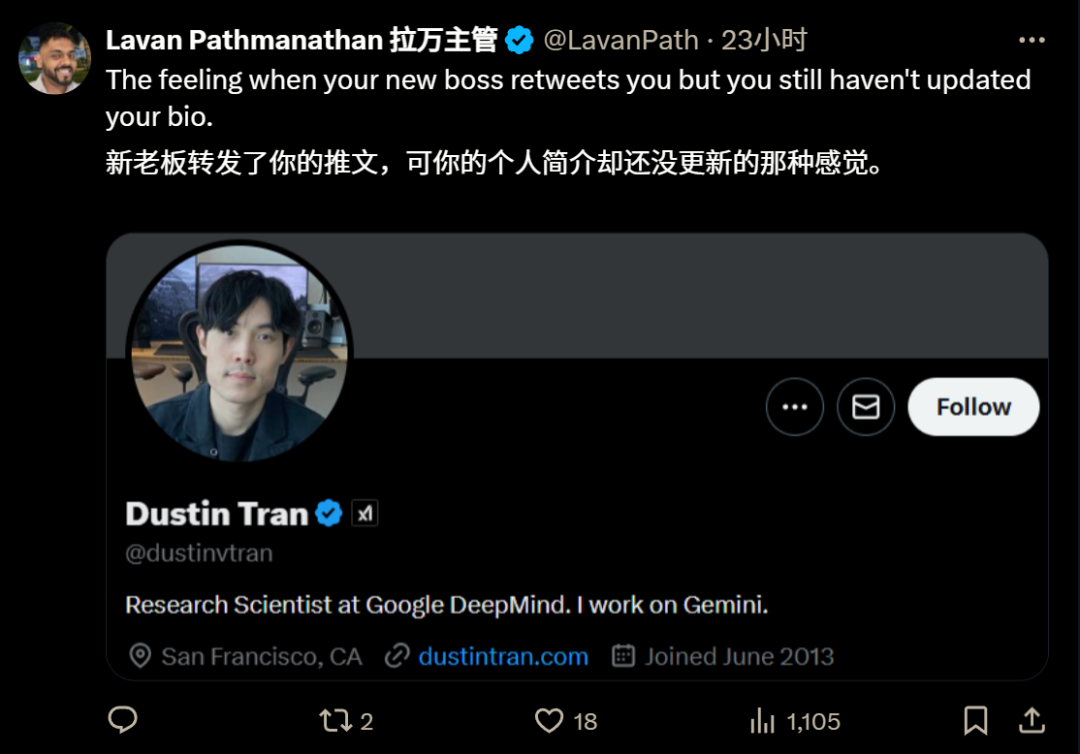
Dustin Tran’s new colleague, xAI founding member Toby Pohlen, who also switched jobs from Google DeepMind, also immediately forwarded a tweet to welcome the new colleague:
Some netizens are also concerned about the restrictions brought by non-compete clauses:
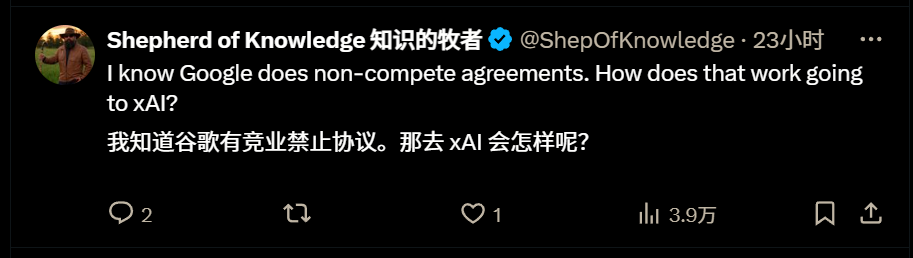
California's ban on non-compete clauses allows talents to flow freely among companies, which is generally considered to be an important guarantee for California's innovative vitality.
Dustin Tran, Gemini core developer
Dustin Tran is the core developer of Gemini from its inception to the latest models.



In 2014, he graduated from the University of California, Berkeley, with an undergraduate degree in mathematics and statistics. He then entered Harvard University to pursue a PhD in statistics. Two years later, he transferred to Columbia University to pursue a PhD in computer science, and received his PhD in 2018.

His current papers have received more than 24,000 citations.

He also won many awards during his doctoral studies, including the Google PhD Scholarship:

His work resume is quite concise: he interned at the OpenAI research position in 2017, and in the same year entered the Google Brain research position as an intern and stayed there for 8 years.
In the long official tweet announcing his resignation, he fondly reviewed his eight years of work at Google, his journey of finding Gemini from chaos, and his decision to join xAI because of its massive computing power:
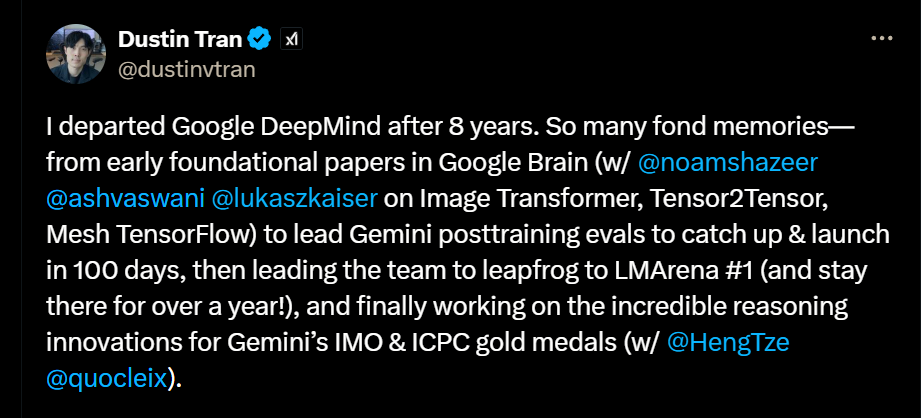
I officially bid farewell to Google DeepMind and ended my 8-year journey. There are a lot of good memories along the way - from the earliest days of participating in some foundational papers in Google Brain (working on Image Transformer, Tensor2Tensor, Mesh with @noamshazeer, @ashvaswani, @lukaszkaiser TensorFlow), and was later responsible for the post-training evaluation of Gemini, catching up and going online within 100 days; then led the team to achieve a leap, winning the first place in LMArena (and holding the top spot for more than a year!); and finally participated in Gemini's inference innovation that won gold medals at IMO and ICPC (together with @HengTze and @quocleix).
Gemini's journey has been full of ups and downs, constantly experiencing paradigm shifts: initially, we transformed the LaMDA model (the first command-like chatbot!) to evolve it from a simple chatbot to one that can give longer and more informative answers through RLHF; later, we explored enhancing reasoning and deep thinking capabilities through long-chain thinking training, novel environments, and reward heads. At the beginning, the outside world was generally not optimistic. Many people felt that Google would be doomed to fail due to the historical baggage of search and internal politics. But now, Gemini has not only ranked first in user preferences for a long time, but also continues to promote new scientific breakthroughs. Instead, everyone feels that Google's victory is natural. (In the past, every time Google had new results, OpenAI would always rely on its backlog of ideas to be released first to seize the AI news cycle; but it can be said that their "inventory" has now been exhausted.)
Then I joined xAI. The secret is actually very clear: computing power, data, and about O(100) smart and hard-working people, this is everything needed to win the cutting-edge large language model. xAI really believes in this. In terms of computing power, even at Google, I have never seen this kind of "chip per capita" scale (and there are 100,000+ GB200/300,000+ GB300 coming soon on Colossus 2). On the data side, Grok 4 makes the biggest bet on RL and post-training scaling. xAI is now betting on data expansion, deep thinking and training recipes. The team also moved extremely quickly - in such a short period of time, no other company can reach xAI's current level of AI capabilities. As @elonmusk said, a company’s first and second derivatives are the most critical: xAI’s development momentum is the fastest.
I'm excited to announce that within the first few weeks of joining, we've launched Grok 4 Fast. Grok 4 is an excellent inference model and still ranks first on ARC-AGI and new benchmarks such as FinSearchComp. But it runs slowly and is not originally designed for general user needs. Grok 4 Fast is one of the best lightweight models - ranked 8th on LMArena (Gemini 2.5 Flash is 18th!). In core inference evaluations (such as AIME), it can compete with Grok 4 while costing 15 times less. Special thanks to @LiTianleli, @jinyilll, @ag_i_2211, @s_tworkowski, @keirp1, @yuhu_ai_.
Gemini has achieved such outstanding results now, which also makes us look forward to the surprises Dustin Tran can bring to Grok 5.
Colossus 2’s massive computing power
Summons a powerful Grok 5
In our previous article, we also conducted a detailed analysis of Colossus 2, which is under intensive construction by Musk: Musk is burning 14 trillion, and 50 million H100 computing power will be online in five years! The ultimate explosion reaches billions

The massive computing power of Colossus 2 reflects Musk’s unabashed ambition: realizing AGI and even ASI is the goal pursued by Grok 5 and even later models of xAI.
As the world's richest man, Musk needs to use astronomical computing power to keep all opponents at bay.
The top computing power attracts the top talents.
Musk doesn’t want to miss out on all the production factors for building powerful off-the-shelf AI.
Let us wait and see how powerful Grok 5 can be brought to us by the addition of Dustin Tran.