AMD is promoting a vision of artificial intelligence that does not rely on the cloud. Its newly released OpenClaw framework, paired with two sets of hardware reference configurations RyzenClaw and RadeonClaw, is designed to allow developers and early adopters to run large language models and multi-agent workflows on local PCs. This move is part of AMD's larger "Agent Computer" plan, which believes that the future of AI should not be limited to remote data centers, but should give users control of their own data and computing environment, keep local AI assistants running for a long time, reduce network dependencies and subscription burdens, and alleviate privacy concerns.

From a technical perspective, OpenClaw currently runs on the Windows platform through WSL2 (Windows Subsystem for Linux 2), and LM Studio is used with the llama.cpp backend to undertake local inference tasks. In this environment, users can run models including Qwen 3.5 35B A3B directly on the machine. The system also supports an embedded memory framework called Memory.md for storing contextual information locally without relying on cloud synchronization. AMD positions the official tutorial as a relatively streamlined configuration path to facilitate developers to build a complete OpenClaw environment on Windows and test the AI agent architecture, but the document does not give a clear estimated configuration time.

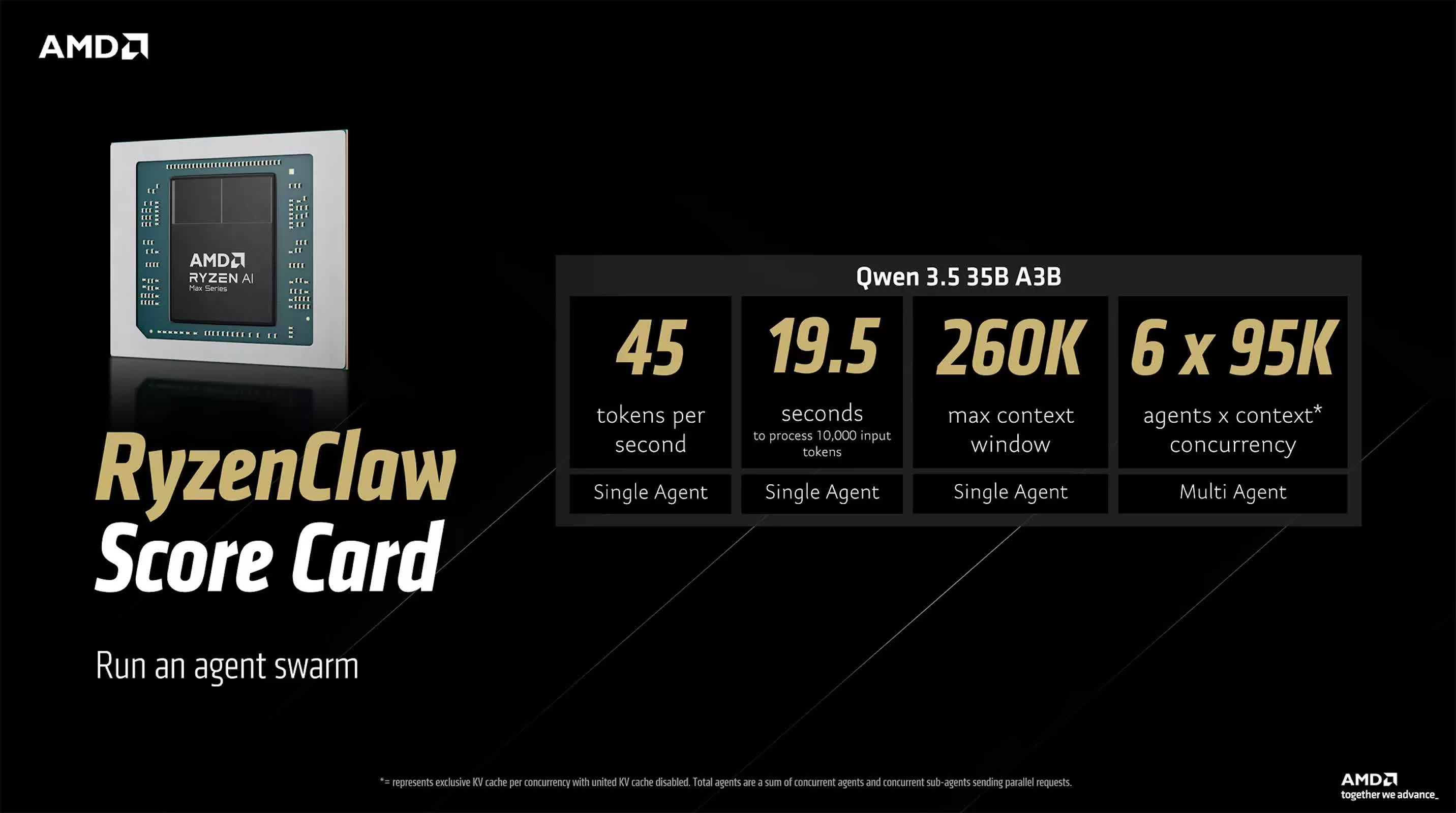
The two OpenClaw references proposed by AMD represent different routes toward "high-performance native AI." The RyzenClaw solution is built around the Ryzen AI Max+ processor and is equipped with 128GB of unified memory, of which AMD recommends that approximately 96GB be allocated as variable video memory to ensure large model inference efficiency. Under this configuration, Qwen 3.5 35B A3B generates approximately 45 tokens per second, takes approximately 19.5 seconds to process an input of 10,000 tokens, supports a context window of approximately 260,000 tokens, and can be used in multi-agent workflows or "agent cluster" experimental environments. AMD says the platform can run up to six local AI agents simultaneously, which is typical of non-data center-level systems.

Another RadeonClaw configuration shifts the focus of computing power to the independent GPU - Radeon AI PRO R9700. This workstation-class graphics card offers 32GB of dedicated graphics memory, significantly increasing inference throughput. Under the same model, the generation speed can be increased to about 120 tokens per second, shortening the time to process an input of 10,000 tokens to about 4.4 seconds. However, this performance gain comes with certain trade-offs: the maximum context window is reduced to approximately 190,000 tokens, and the number of concurrent agents is reduced to 2. These differences highlight AMD's attempt to provide different tuning paths that allow developers to trade off greater context depth and faster inference based on their needs.
In terms of positioning, neither RyzenClaw nor RadeonClaw is an entry-level configuration for ordinary consumers. Taking RyzenClaw as an example, a desktop computer based on the Ryzen AI Max+ 395 chip and equipped with 128GB of memory (such as the Framework Desktop plan) starts at about $2,700. If you go the RadeonClaw route, you'll also need to purchase the Radeon AI PRO R9700 graphics card, which alone has a suggested retail price of about $1,299. AMD currently admits that OpenClaw's main target users are engineers and early adopters who are experimenting with local AI agents, rather than mainstream PC users.

Still, OpenClaw's message goes beyond the specific hardware itself. AMD is betting on a trend in which developers will value autonomy and privacy over cloud-scale expansion, hoping to build a bridge between personal computing and distributed AI through local agents running on consumer-grade chips. If this idea is recognized by the ecosystem, AMD is expected to occupy a unique position in the rapidly evolving AI landscape, allowing some high-end desktops and workstations to gradually have AI processing capabilities close to data centers, while maintaining a sense of control and flexibility on the user side.